大家好,又见面了,我是全栈君。
1、 ElasticSearch介绍
1.1 介绍

官网:https://www.elastic.co/cn/products/elasticsearch
Github:https://github.com/elastic/elasticsearch
总结:
1、elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
2、elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
突出优点:
1.扩展性好,可部署上百台服务器集群,处理PB级数据。
2.近实时的去索引数据、搜索数据。
es和solr选择哪个?
1.如果你公司现在用的solr可以满足需求就不要换了。
2.如果你公司准备进行全文检索项目的开发,建议优先考虑elasticsearch,因为像Github这样大规模的搜索都在用它。
1.2原理与应用
1.2.1索引结构
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边橙色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件
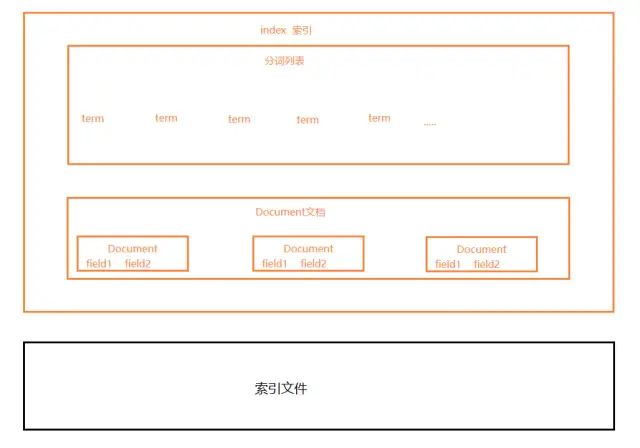
逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:
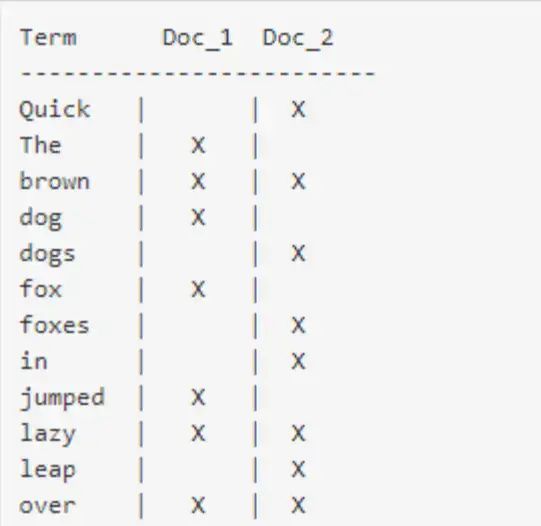
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
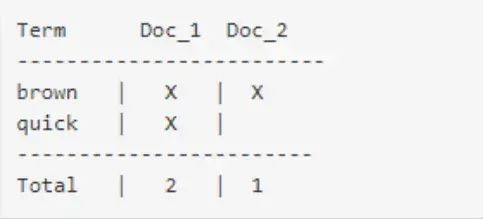
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
2 ElasticaSearch安装
2.1 安装
安装配置:
1、新版本要求至少jdk1.8以上。
2、支持tar、zip、rpm等多种安装方式。
在windows下开发建议使用ZIP安装方式。
3、支持docker方式安装
参见:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
下载ES: Elasticsearch 6.2.1:
https://www.elastic.co/downloads/past-releases
解压 elasticsearch-6.2.1.zip
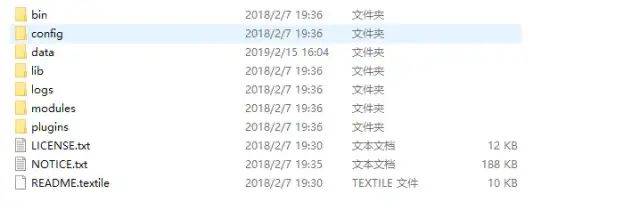
bin:脚本目录,包括:启动、停止等可执行脚本
config:配置文件目录
data:索引目录,存放索引文件的地方
logs:日志目录
modules:模块目录,包括了es的功能模块
plugins :插件目录,es支持插件机制
2.2 配置文件
2.2.1 三个配置文件
ES的配置文件的地址根据安装形式的不同而不同:
使用zip、tar安装,配置文件的地址在安装目录的config下。
使用RPM安装,配置文件在/etc/elasticsearch下。
使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
我们使用的zip包安装,配置文件在ES安装目录的config下。
配置文件如下:
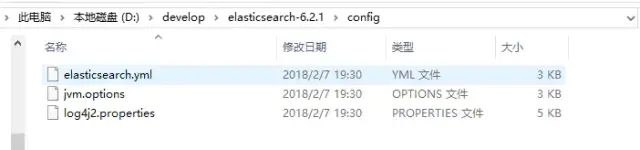
elasticsearch.yml :用于配置Elasticsearch运行参数
jvm.options :用于配置Elasticsearch JVM设置l
og4j2.properties:用于配置Elasticsearch日志
2.2.2 elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path: data: /var/lib/elasticsearch logs: /var/log/elasticsearch
方式2:属性方式
path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch
例子如下:
cluster.name: xuecheng #配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name: xc_node_1 #节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
network.host: 0.0.0.0 #绑定ip地址 ,这个位置改为127.0.0.1,否则报错
http.port: 9200 #暴露的http端口
transport.tcp.port: 9300 #内部端口
node.master: true #主节点
node.data: true #数据节点
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"] #设置集群中master节点的初始列表
discovery.zen.minimum_master_nodes: 1 #主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
bootstrap.memory_lock: false #内存的锁定只给es用
node.max_local_storage_nodes: 1 #单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1
path.data: D:\ElasticSearch\elasticsearch‐6.2.1\data #索引目录
path.logs: D:\ElasticSearch\elasticsearch‐6.2.1\logs #日志
http.cors.enabled: true # 跨域设置
http.cors.allow‐origin: “*” #设置跨域
2.2.3 jvm.options
设置最小及最大的JVM堆内存大小:
在jvm.options中设置 -Xms和-Xmx:
1) 两个值设置为相等
2) 将 Xmx 设置为不超过物理内存的一半
2.2.4 log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
2.3 启动ES
进入bin目录,在cmd下运行:elasticsearch.bat
浏览器输入:http://localhost:9200
显示结果如下(配置不同内容则不同)说明ES启动成功:

2.4 head插件安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head 。
从ES6.0开始,head插件支持使得node.js运行。
1、安装node.js
2、下载head并运行
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start open
HTTP://本地主机:9100 /
3、运行结果

最后
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描下发二维码关注一下,您的支持是我坚持写作最大的动力。求一键三连:点赞、转发、在看

回复 ElasticSearch 获取 分布式搜索引擎elasticsearch 视频教程
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111473.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
