大家好,又见面了,我是全栈君。
如何爬取王者荣耀全皮肤英雄壁纸
-
知道我们的目的
先来看成果吧!


我们的目的需要很明确,我们要做什么,我们要干什么,如何做,在什么地方做。
-
我们的目的:爬取王者荣耀全英雄皮肤壁纸。
-
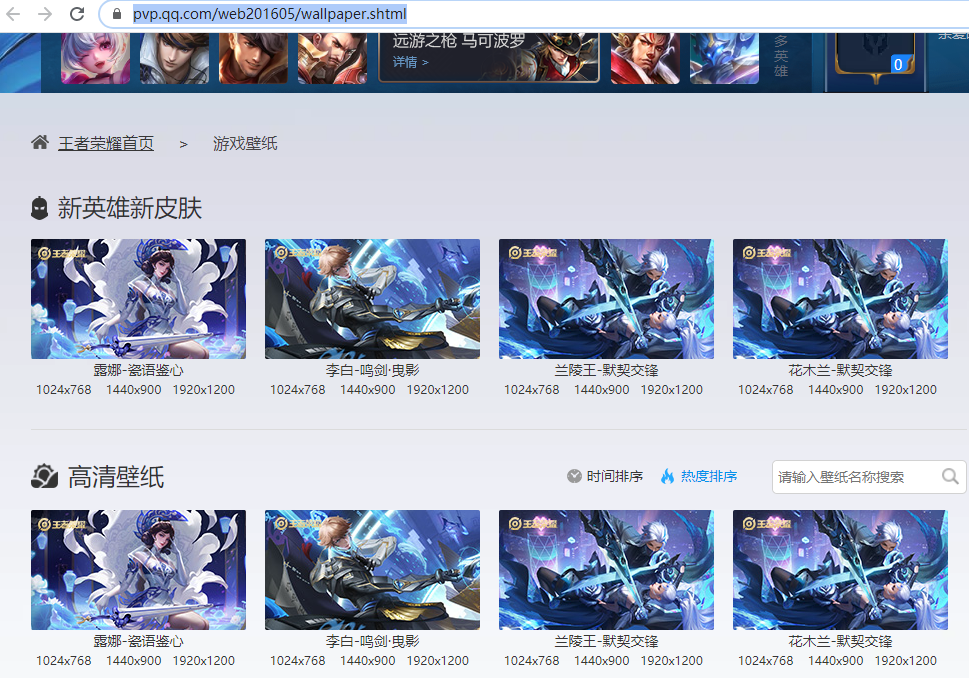
在什么地方:王者荣耀官网—-https://pvp.qq.com/web201605/wallpaper.shtml
-
怎么爬?用python,那下面我们一步一步来。
-
如何获取数据
我们要爬取王者荣耀英雄图片得让自己的思路清晰起来。
第一、我们找到我们需要的壁纸所在的页面。
第二、按F12,点击network,打开开发者工具,查找英雄壁纸的数据特点。
思路:这里我们有两种获取的方式:a、直接使用html抓取图片url路径。b、如果图片是通过接口返回,直接通过接口获取。
我们通过查找html查看,结果html中居然没有返回图片链接。如图:什么都没有
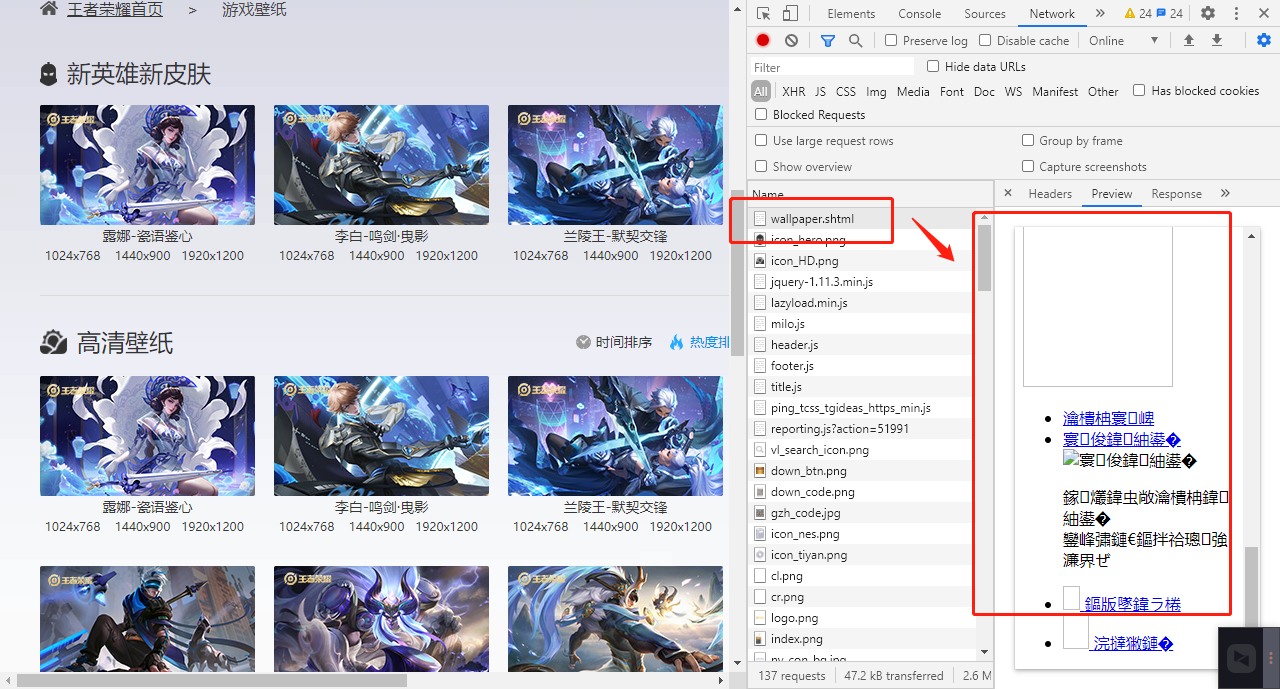
排除这种情况,那就是说,是接口返回的了,噢噢噢(开心~)那就更简单了。
第三、寻找我们所需要的接口吧!
找了半天,终于找到一个似像非像,的接口,噢噢~,那是不是它呢,我们继续来看。
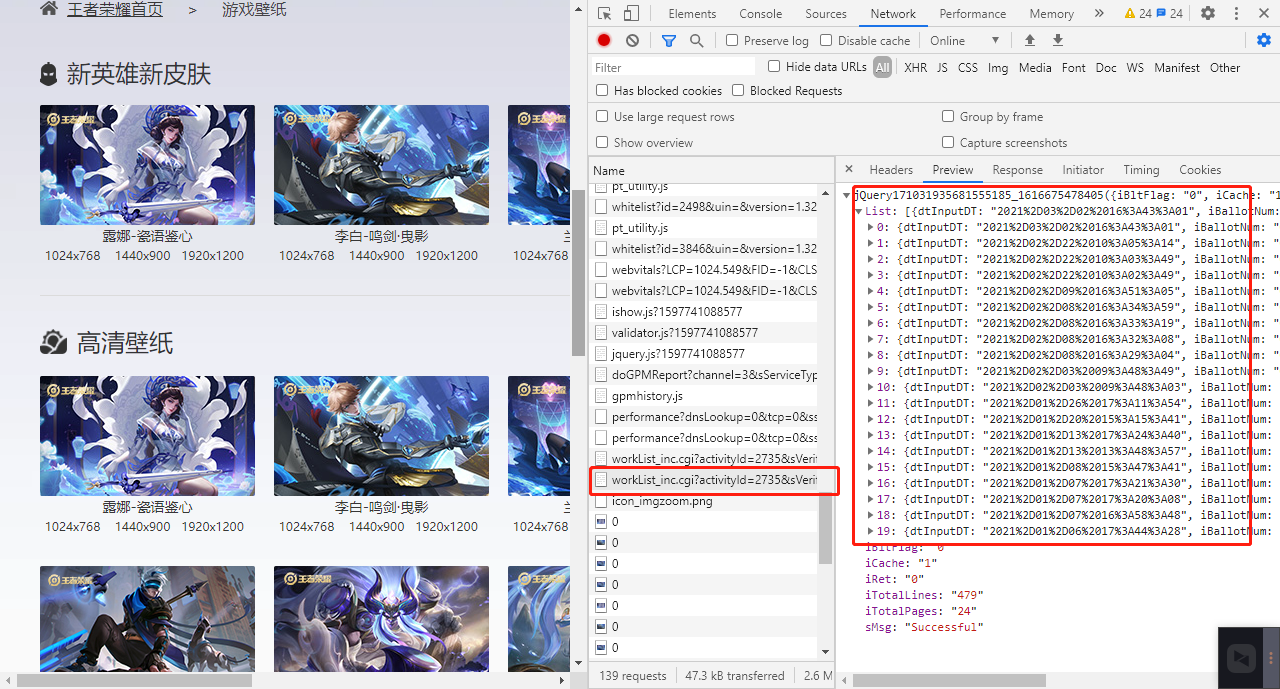
如图,我们成功找到一个接口,但是怎么不是我们认识的字。接着看,我们观察之后,诶,好像很熟悉哦,是不是要转码呀?带着这个疑问,于是我们将他转换一下。我们打开一个认识的词语,name,如图,我们就使用它好了
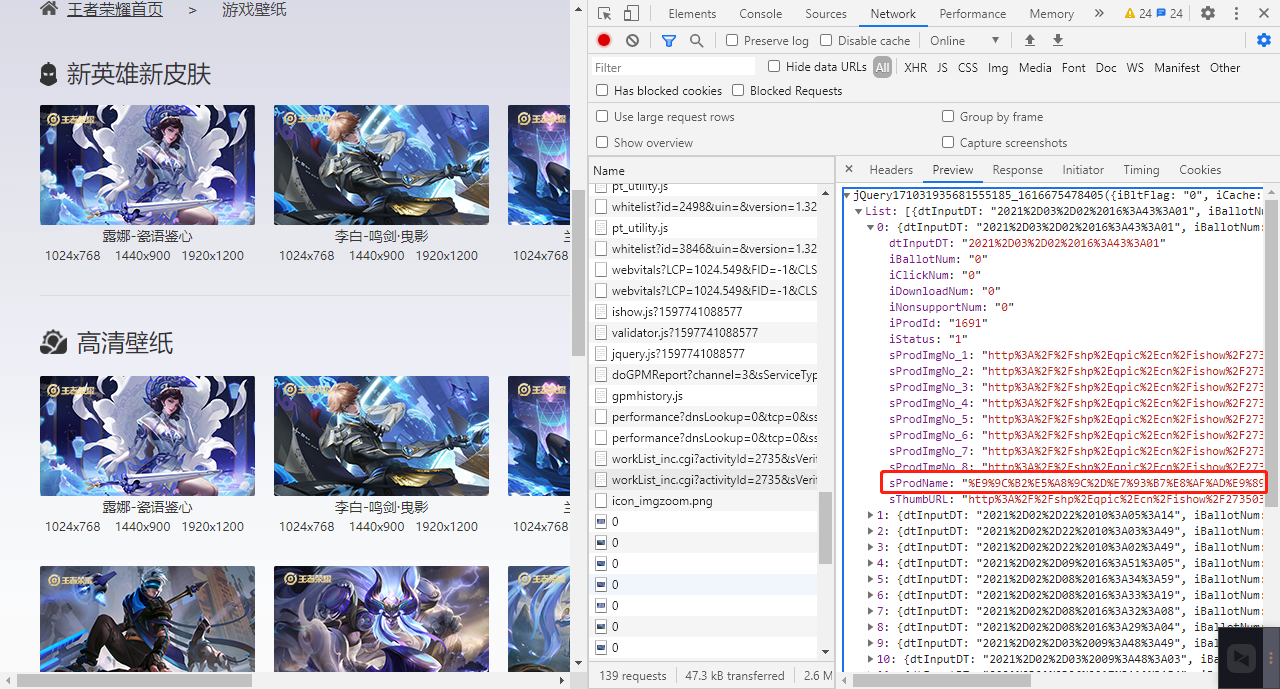
点击顶部的console,然后输入一段神奇的代码:
decodeURIComponent("%E9%9C%B2%E5%A8%9C%2D%E7%93%B7%E8%AF%AD%E9%89%B4%E5%BF%83")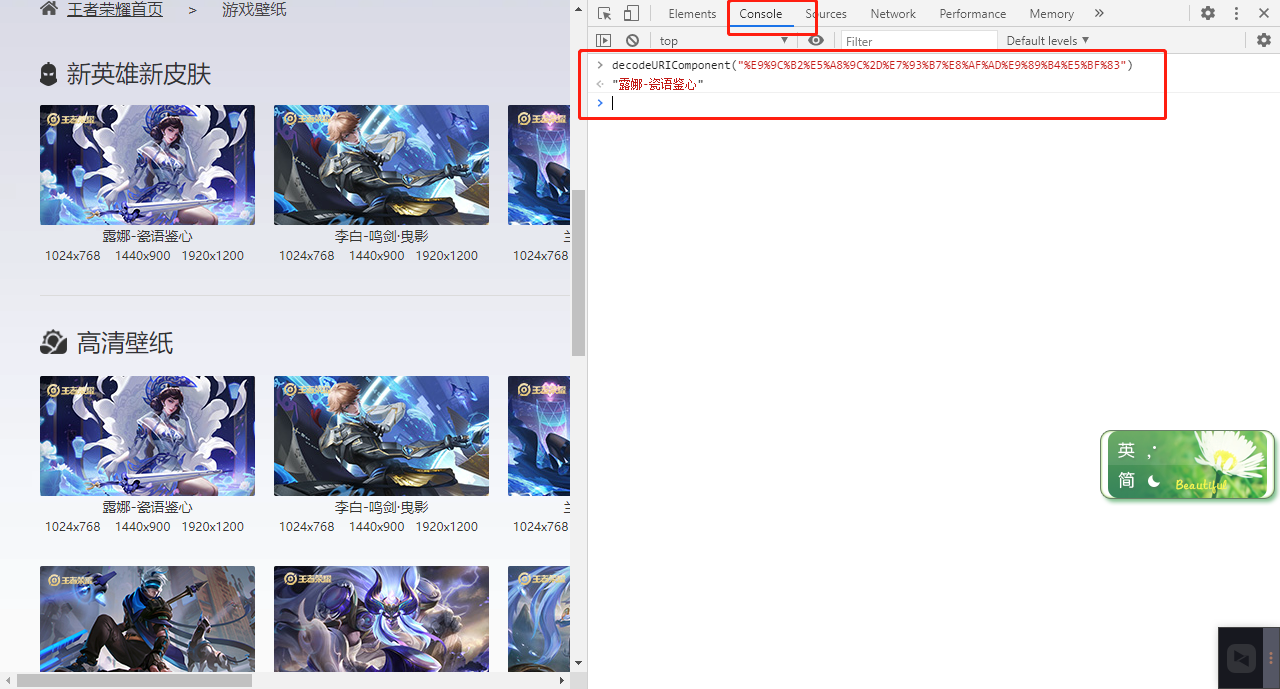
看到这里,请把 “NB” 打在评论区。
-
深度解析接口
已经拿到接口的我们已经离胜利又近了一步,稳得一匹。接口如下:
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171031935681555185_1616675478405&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1616675480449拿到接口的我们,看一下这个接口需不需要什么特殊的参数呢?
结果发现,还真的有参数的变化,page,和jsoncallback,_
page属于翻页,”_”这个属于时间戳,那jsoncallback呢,这个也是变动的。这可咋整。想到这里,那这个参数的做用是什么,我们把他删除可不可以。还真别说,还真的有效,并且返回数据也变为了json形式。(开心~)
-
突如其来的失望
失落在心头
结果没有开心多久,发现,我们得到的url根本不是高清图片,而是一张缩略图。让我们本来高兴的心顿时凉了一截,这个图片完全不正确,下载下来的图片当然也是不正确的。难道我们要这样放弃了吗?不,不可能,一定会有办法的。
思前想后,我们只能从高清图片上找入手点了。
转机
点开一张图片,复制图片地址。在对应接口中,找到对应的数据,复制链接,与之进行对比:
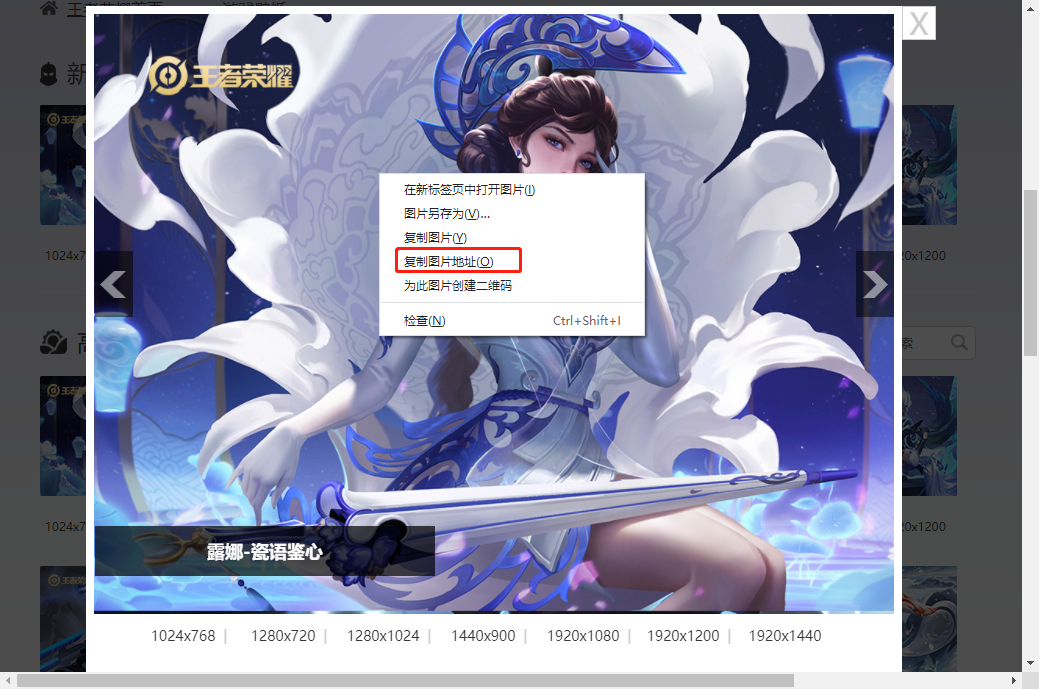
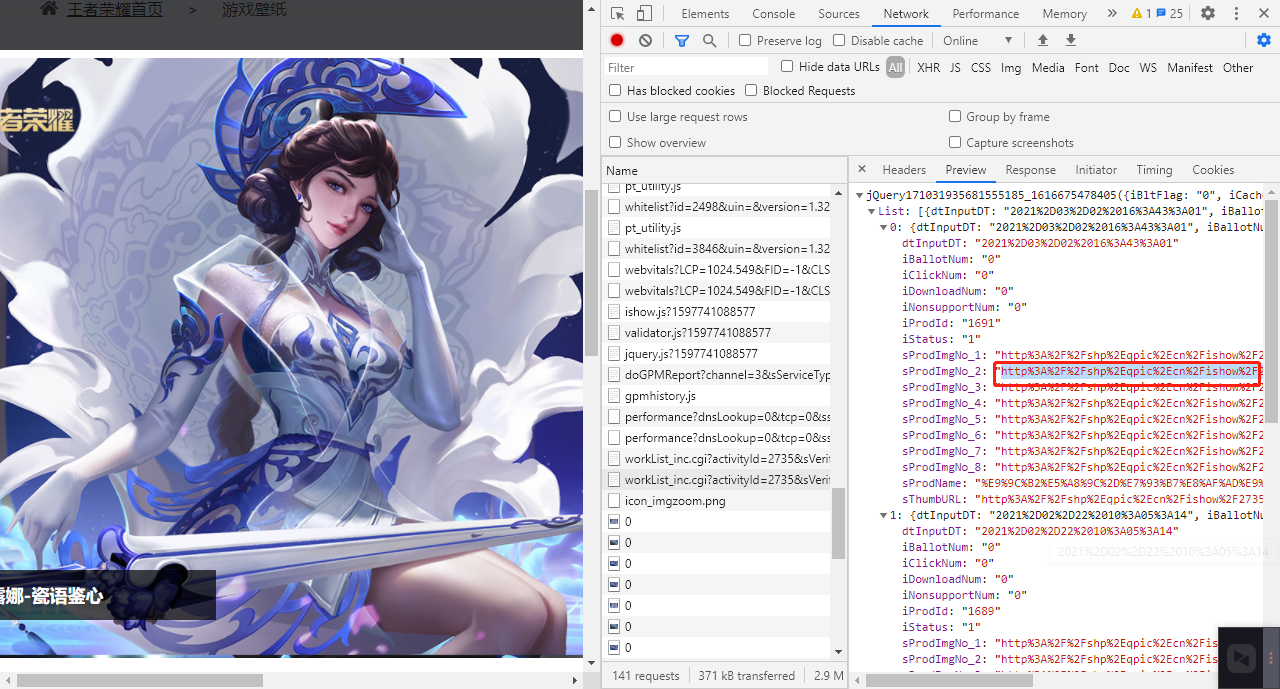
http://shp.qpic.cn/ishow/2735030216/1614674580_84828260_31404_sProdImgNo_2.jpg/0 高清图
http://shp.qpic.cn/ishow/2735030216/1614674580_84828260_31404_sProdImgNo_2.jpg/200 缩略图我~~~~我激动得说不出话来,难道我只需要把200,改为0就可以了吗?
我疯了,还真是~噢噢噢噢噢…… 各位,请把“NB”打在屏幕上。
图片地址那不就有了吗?可恶,这该死的聪明才智。
-
思路解析
我们来整理一下思路:
找到数据位置—>获取url—->解析url—>获取不同尺寸的图片url—>url解码—->将图片尾部200修改为0—>保存图片
-
编码开始
1、首先,说一下我们需要使用到的模块:
requests安装 pip install requests
模块导入:import requests
url解码,导入模块
from urllib.parse import unquote2、解析图片壁纸url,得到json数据
hero=requests.get("https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1616587902145")
hero_picture=hero.json()["List"]3、解析一页数据的所有壁纸,获取壁纸列表,英雄名称。
for j in range(len(hero_picture)):#len()函数统计数量
print(j,hero_picture[j])
hero_name=unquote(hero_picture[j]["sProdName"], 'utf-8')4、获取每一张壁纸中包含的不同尺寸的壁纸。每张里面包含不同尺寸。获取8个尺寸的数据
for y in range(1,8):
print(hero_picture[j]["sProdImgNo_"+str(y)])#y=1~75、转码url
unquote(hero_picture[j]["sProdImgNo_"+str(y)], 'utf-8')6、截取url,去除200,并添加0
hero_image_url = unquote(hero_picture[j]["sProdImgNo_"+str(y)], 'utf-8')[:-3]+"0"#[:-3]这个表示截取字符串长度,+"0"表示字符串拼接7、判断文件是否存在,存在则保存图片,不存在则创建
if os.path.exists("sProdImgNo_"+str(y))==True:
else:
8、解析图片地址,并保存
hero_image = requests.get(hero_image_url).content#解析图片链接,返回二进制
with open("sProdImgNo_"+str(y)+"/"+hero_name+".jpg","wb") as f:#拼接图片路径,保存图片写入文件
f.write(hero_image)9、完整判断
if os.path.exists("sProdImgNo_"+str(y))==True:
hero_image = requests.get(hero_image_url).content
with open("sProdImgNo_"+str(y)+"/"+hero_name+".jpg","wb") as f:
f.write(hero_image)
else:
hero_image = requests.get(hero_image_url).content
os.mkdir("sProdImgNo_"+str(y))#创建目录
with open("sProdImgNo_"+str(y)+"/"+hero_name+".jpg","wb") as f:
f.write(hero_image)10、考虑到中途我们可能会请求失败,避免重复操作,因此,我们需要做文件是否存在的判断
if os.path.exists("sProdImgNo_"+str(y)+"/"+hero_name+".jpg")==True:#如果文件存在就跳过,不存在就保存
pass
else:11、再增加翻页请求,我们的代码就完整了。看到这里还不点赞,加关注。
-
完整的代码解析
import requests
from urllib.parse import unquote
import os
for i in range(0,24):
hero=requests.get("https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?"
"activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page="+str(i)+
"&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId="
"267733&iActId=2735&iModuleId=2735&_=1616587902145")
hero_picture=hero.json()["List"]
for j in range(len(hero_picture)):
hero_name=unquote(hero_picture[j]["sProdName"], 'utf-8')
for y in range(1,9):
hero_image_url = unquote(hero_picture[j]["sProdImgNo_"+str(y)], 'utf-8')[:-4]+"/0"
print(hero_name,y)
if os.path.exists("sProdImgNo_"+str(y))==True:
if os.path.exists("sProdImgNo_"+str(y)+"/"+hero_name+".jpg")==True:
pass
else:
hero_image = requests.get(hero_image_url).content
with open("sProdImgNo_"+str(y)+"/"+hero_name+".jpg","wb") as f:
f.write(hero_image)
else:
if os.path.exists("sProdImgNo_"+str(y)+"/"+hero_name+".jpg")==True:
pass
else:
hero_image = requests.get(hero_image_url).content
os.mkdir("sProdImgNo_"+str(y))
with open("sProdImgNo_"+str(y)+"/"+hero_name+".jpg","wb") as f:
f.write(hero_image)欢迎关注公众号,大家一起学编程
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111373.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
