大家好,又见面了,我是全栈君。
“ 如何获取百度的实时热点信息。”
该文章对需要实时了解热点新闻,以及咨询的同学有一定帮助。我们需要每天晚上7:00的时候把这些信息发送给我们。方便我们对信息做出处理。
01— 我们需要获取的数据内容
我们需要获取到的数据信息是什么,打开百度—》搜索内容,右边栏处有一个百度热榜,那我们就来获取这部分的内容好了。如图:
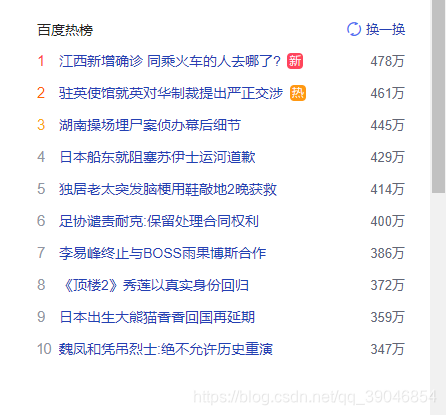

02— 获取内容实例
以下就是我获取到的数据内容,来看一下吧。这样就大大节省了我们收集信息的时间,快速了解热点信息。
热点排行:
1 .江西新增确诊同乘火车的人去哪了? ----478万
2 .驻英使馆就英对华制裁提出严正交涉 ----461万
3 .湖南操场埋尸案侦办幕后细节 ----445万
4 .日本船东就阻塞苏伊士运河道歉 ----429万
5 .独居老太突发脑梗用鞋敲地2晚获救 ----414万
6 .足协谴责耐克:保留处理合同权利 ----400万
7 .李易峰终止与BOSS雨果博斯合作 ----386万
8 .《顶楼2》秀莲以真实身份回归 ----372万
9 .日本出生大熊猫香香回国再延期 ----359万
10.魏凤和凭吊烈士:绝不允许历史重演 ----347万
11.女子为得999车牌号与公公假结婚 ----334万
12.驻香港部队狙击手集训 ----323万
13.乌合麒麟出漫画新作 ----311万
14.中概股惊魂夜谁是幕后推手? ----290万
15.iPhone折叠屏手机曝光 ----280万
16.韩国农心集团创始人去世 ----270万
17.薇娅1小时卖出2千多万元新疆棉制品 ----261万
18.崔天凯谈中美领事馆是否会重开 ----251万
19.20余省份公务员考试今举行 ----243万
20.2020中国考古新发现揭晓 ----234万 03— 代码实现
class hot():
def baidu_hot(self):
header={
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Upgrade-Insecure-Requests": 1,
"Host": "www.baidu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36"
}
html=requests.get("http://www.baidu.com/s?ie=UTF-8&wd=百度&rsv_spt=1&rsv_iqid=0xb9173f8c00007b8a&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=0&rsv_dl=ib&rsv_sug3=4&rsv_btype=i&inputT=9675&rsv_sug4=9675",params=header)
html.encoding="utf-8"
html_text=html.text
Soup = BeautifulSoup(html_text, "html.parser")
tbody=Soup.find_all("tbody")[0]
hot_text="热点排行:\n"
if tbody!="None":
for j in range(2):
tbody_num = Soup.find_all("tbody")[j]
for i in range(1,11):
text=str(tbody_num.find_all("a")[i-1].get_text()).replace(" ","").replace("\n","")
# url=t.find_all("a")[i]["href"]
hot_num=tbody_num.find_all("td",attrs=({"class":"toplist1-right-num toplist1-td c-color-gray"}))[i-1].get_text()
if j==0:
hot_text=hot_text+'{0:2}.{1:20}----{2:10}\n'.format(str(i),text, hot_num)
else:
hot_text=hot_text+'{0:2}.{1:20}----{2:5}\n'.format(str(10+i),text, hot_num)
return hot_text
else:
pass
if __name__=="__main__":
hot=hot()
print(hot.baidu_hot())这样,我们就完成了百度热榜的获取了,还在等什么,赶快学起来吧。后面还可给他增加一个定时器,发送邮箱,这样我们还可以完成,定时给指定邮箱发送百度热榜信息。
相关推荐:
关注我们:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111372.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
