1. 任务
为了实现一些机械分词算法,准备使用“国家语委语料库”的分词词表,在线下载到得词表文件是一个Excel文件。本文的任务就是使用Perl从该Execl文件中提取所有的词语。
词表文件格式如下:


需要的词语的位置在从第8行开始的,第B列的所有单元格。一共有14629个词语。(PS:语料库的分词词表包含8万多个词语,但是在线下载到是出现次数在50次以上的词语,只有这1万多)。
2. 使用什么模块
通过阅读一些博文发现,PERL的Spreadsheet::ParseExcel模块支持Excel的读操作。
3. 如何下载模块(windows xp上的草莓PERL)
在命令行下输入:cpan Spreadsheet::ParseExcel,即可自动安装。
![]()
![]()
安装结束后,输入perldoc Spreadsheet::ParseExcel,即可检测是否安装成功。(如果安装失败,会输出安装失败)
4. 样例代码
感觉perldoc的样例代码读起来很费力,不如直接到cpan网站上面去看样例代码,或者下载模块的样例代码。
登录cpan网站:http://search.cpan.org/,查找Spreadsheet::ParseExcel模块,在其主页
http://search.cpan.org/~jmcnamara/Spreadsheet-ParseExcel-0.59/lib/Spreadsheet/ParseExcel.pm#NAME
上面可以找到样例代码和一些解释。样例代码如下,遍历所有的worksheet,遍历每个worksheet下面的单元格。
!/usr/bin/perl -w
use strict;
use Spreadsheet::ParseExcel;
my
$parser = Spreadsheet::ParseExcel->new();
my
$workbook =
$parser->parse(
‘
Book1.xls
‘);
if ( !
defined
$workbook ) {
die
$parser->error(),
“
.\n
“;
}
for
my
$worksheet (
$workbook->worksheets() ) {
my (
$row_min,
$row_max ) =
$worksheet->row_range();
my (
$col_min,
$col_max ) =
$worksheet->col_range();
for
my
$row (
$row_min ..
$row_max ) {
for
my
$col (
$col_min ..
$col_max ) {
my
$cell =
$worksheet->get_cell(
$row,
$col );
next
unless
$cell;
“
Row, Col = ($row, $col)\n
“;
“
Value =
“,
$cell->value(),
“
\n
“;
“
Unformatted =
“,
$cell->unformatted(),
“
\n
“;
“
\n
“;
}
}
}
另外,在该网页上可以找到该模块的文件:
http://search.cpan.org/CPAN/authors/id/J/JM/JMCNAMARA/Spreadsheet-ParseExcel-0.59.tar.gz
这个压缩包包含了很多模块的样例代码。
5. 样例文件读取
首先建立一个只有4行1列的excel文件,进行尝试:
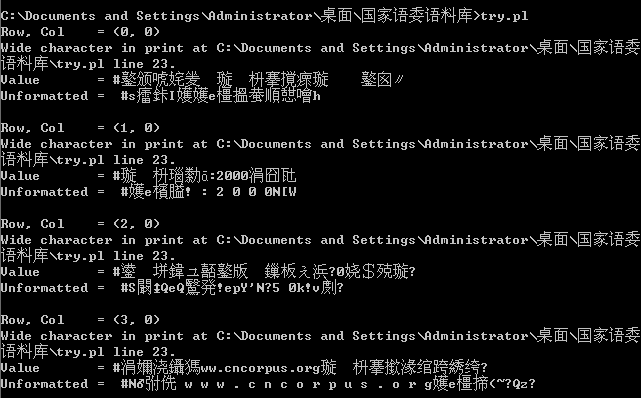
然后使用前面的样例代码,将’Book1.xls’替换为目标文件名,即可。显示中文乱码。
根据网上资料来看,excel的字符编码是unicode,一般使用如下代码进行解决:
$formatter = Spreadsheet::ParseExcel::FmtUnicode->new(Unicode_Map=>
“
CP936
“);
my
$workbook =
$parser->parse(
‘
example.xls
‘,
$formatter);
完整代码如下:
!/usr/bin/perl -w
use Spreadsheet::ParseExcel;
use Spreadsheet::ParseExcel::FmtUnicode;
my
$parser = Spreadsheet::ParseExcel->new();
my
$formatter = Spreadsheet::ParseExcel::FmtUnicode->new(Unicode_Map=>
“
CP936
“);
my
$workbook =
$parser->parse(
‘
example.xls
‘,
$formatter);
if ( !
defined
$workbook ) {
die
$parser->error(),
“
.\n
“;
}
for
my
$worksheet (
$workbook->worksheets() ) {
my (
$row_min,
$row_max ) =
$worksheet->row_range();
my (
$col_min,
$col_max ) =
$worksheet->col_range();
for
my
$row (
$row_min ..
$row_max ) {
for
my
$col (
$col_min ..
$col_max ) {
my
$cell =
$worksheet->get_cell(
$row,
$col );
next
unless
$cell;
print
“
Row, Col = ($row, $col)\n
“;
print
“
Value =
“,
$cell->value(),
“
\n
“;
print
“
\n
“;
}
}
}
<STDIN>;
注意所有需要安装的模块有如下几个:
Spreadsheet::ParseExcel:最开始安装的。
Unicode::Map:这个要安装一下,用于字符编码。
IO-stringy:这个已经安装过了,具体不清楚。
OLE-Storage_Lite:这个是访问office套件的需要的包。在安装Spreadsheet::ParseExcel被安装了。
这里只需要安装Unicode::Map即可。
上面代码显示结果正常:

此处可以发现,行和列的单元格的下标都是从0开始的。
6. 任务实现
词语的行从第8行开始(下标为7),列都在第2列(下标为1)。这样对代码略作修改,令$row_min=7,令$col_min=$col_max=1。修改目标文件名为’CorpusWordlist.xls’。输出结果如下:
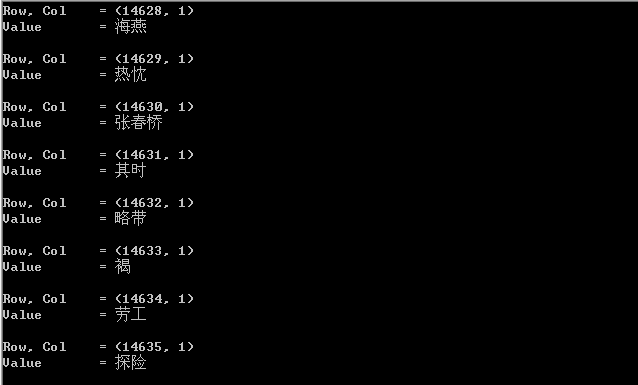
从第7行到14635行,刚好14629行。
7. 文件
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/110481.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
