此节来自于《Python学习手册第四版》第三部分
一、python语句简介(第10章)
1、首先记得一个概念:a、程序由模块构成;b、模块包含语句;c、语句包含表达式;d、表达式建立并处理对象。python的语法是由语句和表达式组成,表达式处理对象并嵌套在语句中,语句编码实现程序操作中更大的逻辑关系,语句是对象生成的地方,有些语句会完全生成新的对象类型(函数、类)。语句总是存在于模块中,而模块本身则又是由语句来管理的。
2、下面是一个python的语句表:




a、赋值语句以不同的语法形式呈现,例如:基本的、序列的、扩展的等等;b、print在3.0中不是一个保留字,也不是一条语句,而是一个内置的函数调用,因为总是自己单独一行,通常将其看作是一条语句类型;c、yield实际上是一个表达式,而不是一条语句,他通常单独用在一行,所以它包含在上表中,但是脚本偶尔会赋值惑使用其结果,与print不同,作为一个表达式,yield也是一个保留字。
3、上表中大多数也适用于2.6,不过如果使用2.6或者更早的版本注意:a、nonlocal不可用;b、print是一条语句,不是内置函数;c、3.0的exec代码执行内置函数是一条语句,具有特定的语法;因为它支持带有圆括号的形式,通常在2.6中使用其3.0的调用形式;d、2.5中try/except和try/finally语句合并了;即用谁都行;e、whit/as是一个可选的扩展,并且通常它是不可用的,除非你通过运行__future__import with_statement来打开它。
4、在c系列中判别表达式需要圆括号括起来(x>y),而且语句需要用大括号{}括起来;而在python中在使用冒号:代替,而且无需花括号,一般首行以冒号结尾,下一行嵌套的代码按缩进的格式书写:

在python中:a、括号是可选的,比如if(x>y)写成 if x>Y;b、在python中不会出现的语法成分就是分号,一行结束就结束了(这个观点是好,是坏不评论,我是喜欢分号的);c、缩进结束就是代码块的结束,不需要和c语言一样,输入大括号,或者和matlab等一样输入begin/end,then/endif,在python中,是靠缩进来确定代码块的开头和结尾的,python不在乎缩进的方式和距离,只知道一个单独的嵌套块中所有的语句都必须缩进在相同的距离,不然会报错。
5、在上述4中 python还是有几个特例的:a、虽然很多时候是一行一个,但是也有一行多个的,这时候中间用分号隔开,作为语句界定符:a = 1;b = 2;print(a+b),不过这三个不能是复合语句,必须是简单语句,比如赋值操作,打印和函数调用等等;b、上面是一行多个,这里是多行一个,在括号(),方括号【】和字典的大括号{},这几个中程序的代码可以横跨好几行:

在不用这三个括号的时候,还有个方法:

(这个方法不推荐)。而且对于当行的语句可以跟在比如if x>Y:print(X).
6、在需要写一个标准的“读取、计算、打印”的循环程序:在python中交互式循环的典型模版代码可能如下图:

while是最通用的循环语句;input用于通用控制台输出,打印可选的参数字符串作为提示,并返回用户输入的回复字符串;用了嵌套代码块中特殊的单行if语句;break跳出循环。
7、用测试输入数据来处理错误,来个例子if语句避免错误导致的异常:


8、用try语句处理上面的错误:

在try后面跟着的是代码主要代码块(我们尝试运行的代码),再跟except部分,给异常处理器代码,再接else部分,如果try部分没有异常,就执行这一部分代码。Python会先执行try部分,然后运行except部分(如果有异常发生)或else部分(如果没有异常发生),这里else是和try结合,不是和if结合。
9、嵌套代码三层:

这个代码while包含一个if-elif-else 其中else包含一个if-else。之后while外部在加了一个print().
二、赋值、表达式和打印(第11章)
赋值:(前面说过了,其实本书真的和知乎上说的一样,好啰嗦,1162页很多都是在啰嗦):a、赋值语句建立对象引用值;b、变量名在首次赋值时会被创建;c、变量名在引用前必须被赋值;d、执行隐式赋值的一些操作。赋值语句的形式如下图:

上面第五行,是将右边字符串的第一个字母来匹配a,用剩下的部分来匹配b:也就是a赋值为‘s’,b赋值为‘pam’。
1、元组赋值语句可以在不建立零时变量的时候进行变量互换,比如:nudge = 1;wink = 2; >>>A,B = nudge,wink;或者>>>[C,D] = [nudge,wink];互换可以这样>>>nudge,wink = wink,nudge。在python中原始的元组和列表赋值语句形式,最后已被通用化,右侧可以是任何类型的序列,只要长度相等就行,例如下面的:

不过其实序列赋值语句实际上支持右侧任何可迭代的对象,而不仅局限于任何序列,这是更为通用的概念。不过想要更通用,可以使用分片例如:


或者低端的使用for循环来进行循环赋值:

序列解包赋值语句也会产生另一种python常见的用法:


2、在3.0的扩展序列解包中,序列赋值变得更为通用,从而使这一过程变得容易,一个带有单个星号的名称,可以在赋值目标中使用,以指定对序列的一个更为通用的匹配–一个列表付给了带星号的名称,该列表收集了序列中没有赋值给其他名称的所有项;


,

这种扩展的序列解包语法对于任何序列类型都是有效的,而不只是针对列表有效,比如>>>a,*b=’spam’;或者>>>a,*b,c = ‘spam’;在扩展的序列解包中,一些边界情况值得注意,如果在分配不够的时候带星号的名称可能只匹配单个的项,但是总会向其赋值一个列表:,其次如果没有剩下的内容给带星号的,那么就会赋值一个空的列表给他,而不管该名称出现在哪:


不过如果有多个带星号的名称,或者如果值少了,而没有带星号的名称(像前面一样),以及如果带星号的名称自身没有边写到一个列表中,都将会引发错误:
>>>a,*b,c,*d = seq;>>>a,b = seq;>>>*a = seq;这三个都是错的;>>>*a, = seq这个加了逗号,表明就是一个列表 结果就是a = [1,2,3,4];
3、这里一个有用的便利形式,不过说必须在python 2.X中使用,所以这里略
4、在3.0中,扩展赋值可能出现在单词for之后,而更常见的用法就是一个简单的变量名称:

结果就是a,*b,c = (1,2,3,4);*b = [2,3];或者在2.6中用下面的形式来模拟:

5、多目标赋值:a=b=c=’spam’,这里三个变量但是共享一个对象,不过如果对>>>a=b=0; >>>b = b+1;这样,a和b是两个对象,因为数字或者字符串是不能更改的,所以赋值之后b得到的是一个新的对象,而不是原对象;不过将变量初始值设为空的可变对象时(列表或者字典),就要小心了:


所以如果是可变对象的,最好单独初始化。
6、增强赋值语句,从c语言中借鉴过来的:

如果需要增加单个元素到列表末尾时,可以合并或调用append,不过要把一组元素增加到末尾,可以再次使用合并,或者调用列表的extend方法:

,

这两种情况下,合并对共享对象引用产生的副作用可能会更小,不过会比对等的原处形式运行的更慢,合并操作是创建一个新的对象,将左侧的复制到列表中,然后右侧的复制到列表中,而原处方法调用就是直接在一个内存快末尾添加项。不过在使用增强赋值语句来扩展列表时,python会自动调用较快的extend方法,而不是较慢的“+”合并运算,所以“+=”是隐含了对列表进行原处处理的。就所有的共享引用情况而言,只有其他变量名引用的对象被修改,其差别才可能体现出来:


这只对列表和字典这类可变对象才重要,而且是相当罕见的情况(至少,直到影响程序代码时才算),所以如果不想被默认的共享引用值,那么就对可变对象进行拷贝。
7、变量命名规则:a、语法:(下划线或字母)+(任意数目的字母、数字或下划线);b、区分大小写;c、禁止使用保留字:

上表是针对3.0的,2.6的略有不同:print是保留字,exec是保留字,nonlocal不是保留字,更早的就略P305页。大多数的python保留字都是小写的,不过后续介绍的内置作用域中的变量名不同。因为import语句中的模块变量名会变成脚本中的变量,这种限制也会扩展到模块的文件名:比如可以写and.py和my-code.py这类的文件,但是没法导入,因为其变量名没有“.py”扩展名时,就会变成代码中的变量,就会与保留字冲突了。ps:在Jpython版的python实现中,用户定义的变量名偶尔可以和python的保留字相同。
命名惯例:这些不是必须的,不过实际上通常大家都会遵守,a、以单一下划线开头的变量名(_X)不会被from module import *语句导入(22章说明);b、前后有下划线的变量名(__X__)是系统定义的变量名,对解释器有特殊意义;c、以两个下划线开头,但结尾没有两个下划线的变量名(__X)是类的本地变量(30章说明);d、通过交互模式运行时,只有单个下划线的变量名(_)会保存最后表达式的结果。还有一些比如类变量名通常以一个大写字母开头,而模块变量名以小写字母开头,此外,变量名self虽然并非保留字,但在类中一般都有特殊的角色,在第17章中会有接着讲解,涉及到内置变量名,这些是预先定义的变量名,但并非保留字。更多信息可以通过搜索“Python PEP 8”。
8、通常在下面两种情况下表达式用作语句:a、调用函数和方法;b、在交互模式提示符下打印值,下表是一些常见的表达式语句的形式,函数和方法的调用写在函数、方法变量名后的括号中,具有零个或多个参数的对象(这就是计算对象的表达式):

上表最后两条是特殊的,在3.0中,打印是一个函数调用而通常独自边写一行,并且生成器函数中的yield操作通常也编写为一条语句,二者都只是表达式语句的实际例子。
9、对于初学者来说经常犯得错误就是>>>L = L.append(X)这样,可是得到的结果是L= None,因为对列表调用append、sort或reverse这类在原处的修改的运算,一定是对列表做原处的修改,但是这些方法在修改之后,不会把列表返回,而是返回None。
10、python中打印与文件和流的概念紧密相连:a、文件对象方法,第九章说了一些写入文件的文件对象方法(如;file.write(str)),文件写入方法是将字符串写入到任意文件,print默认把对象打印到stdout流,添加一些自动的格式化,和文件方法不同,在使用打印操作的时候,不需要将对象转换成字符串;b、标准输出流,在python中可以作为内置的sys模块中的stdout文件对象使用(如sys.stdout),使得用文件的写入方法调用来模拟print成为可能,不过print很容易使用,所以很容易将文本打印到其他流或文件。
11、在3.0中print函数的形式为:

,方括号是可选的,=后面的值都给了参数的默认值,这个内置函数将字符串sep所分隔开的一个或多个对象的文本表示,后面跟着字符串end,都打印到流file中。sep、end和file如果都给出的话,必须作为关键字参数给定,使用“name=value”语法来根据名称而不是位置来传递参数(18章深入介绍):a、sep是在每个对象的文本间插入一个字符串,默认是一个单个空格,传递一个空字符串将会抑制分隔符;b、end是添加在打印文本末尾的一个字符串,默认是\n换行符,传递一个空字符串将会避免在打印的文本末尾移动到下一个输入行—-下一个print将会保持添加到当前输出行的末尾;c、file指定了文本将要发送到的文件、标准留或者其他类似文件的对象;默认是sys.stdout,带有一个类似文件的write(string)方法的任何对象都可以传递,但真正的文件应该已经为了输出而打开。
12、在3.0中print可能要更简单一些,下面就是个例子:
,


右边的就是通过将sep赋值来进行分隔符的处理


上图中是对end赋值和对sep混合赋值,至少一点,这些都要在参数之后。

如果想要更具体的格式,不要这样,还是按照之前的字符串格式化,然后一次性打印

13、print语句只是python的人性化的特性,提供了sys.stdout对象的简单接口,再加上一些默认的格式设置,复杂点可以如下:

这段程序调用了sys.stdout的write方法,通常来说print和sys.stdout的关系如下:print(X,Y)等价于>>>import sys;>>>sys.stdout.write(str(X)+‘ ’+str(Y)+‘\n’);后者更复杂,不过后者也更灵活,例如:
,这里我们把sys.stdout重设成已打开的文件对象(附加模式)。重设之后,程序中任何print语句都会将结果写道文件log.txt的末尾,而不是原始的输出流。甚至可以将sys.stdout重设为非文件的对象,只要该对象有预期的协议(write方法)。当该对象是类时,打印的文字可以定位并通过任意方式进行处理。

14、那么如何保存原来的输出流使得在打印完文件之后可以切换回来,在2.6和3.0中,可以使用sys模块中的__stdout__属性,这也就是程序启动时sys.stdout的原始值。不过,等修改之后还是需要将sys.stdout恢复成sys.__stdout__从而回到原始流的值:

上图可以看出这样一个print扩展功能有时候会很多余,在3.0中file关键字允许一个单个的print调用将其文本发送给一个文件的write方法,而不用真正的重设sys.stdout,这种设定是暂时的,普通的print还是会接着打印到原始输出流的。(2.6中是用print >> log,x,y,z;这里的log是“log.txt”)。
15、上面的是和版本相关的打印,这里介绍下版本独立的打印:如果写的是2.6的print语句,那么使用3.0中的2to3转换脚本来在3.0中调用。或者可以在2.6的代码中写3.0的print函数,通过下面的语句支持该函数调用的变体:

这条语句将2.6修改为支持3.0的print函数,如果需要真的可移植,那么就把打印字符串格式化为一个单个的对象,使用字符串格式化表达式或者方法调用:

16、print和sys.stdout之间等效,print语句只是传送文本给sys.stdout.write方法而已,例如可以传送打印的文字给GUI窗口,或者定义一个有write方法的对象,他会做所需要的发送工作,后面介绍类的时候会有这种技巧:

上述代码可以工作是因为print是一种多态运算:sys.stdout重要的是有个方法(接口)称为write:

print内置的raw_input()函数会从sys.stdout文件读入。ps:因为打印的文字进入stdout流,这也是在CGI脚本中打印HTML的方式,这也可以在os中用shell语法形式实现:

三、if测试和语法规则 (第12章)
python中的if功能差不多:
,


,

1、在python中没有switch或case语句,在python中多路分支是写成一系列的if/elif测试的,或者对字典进行索引运算或搜索列表:

因为在if系列中有个默认选项,而在字典中也可以使用get来实现:

2、python中的语法规则:python都有简单的和基于语句的语法,不过有些特性还是需要知道的:a、语句是逐个运行的,除非不这样写,if这种会影响流程的叫做控制流程语句;b、块和语句的边界会自动检测;c、复合语句 = 首行+“:”+缩进语句,复合语句都遵循相同的格式:首行以冒号终止,再第二行接一个或多个嵌套语句,通常都是在首行下缩进的,缩进的语句叫做块(组);d、空白行、空格以及注释通常都会忽略;e、文档字符串(docstring)会忽略,但会保持并由工具显示:与#注释不同,文档字符串会在运行时保留下来以便查看,文档字符串只出现在程序文件和一些语句顶端的字符串中,虽然python会忽略这些内容,不过在运行时会自动将其附在对象上,而且可以由文档工具显示。
3、一般来说python的语句没法跨行,不过:a、使用如(),【】,{}这类括号就可以跨行;b、反斜线结尾;c、字符串的三重引号字符串块,相邻的字符串常量可以隐式的连接起来;d、其他规则,比如分号可以把多行放在一行。
4、如这个括号:

,括号内可以存放表达式、函数参数、函数的首行、元组和生成器表达式,以及可以放到花括号中的任何内容(字典以及3.0中的集合常量、集合和字典解析)等内容。
5、python的布尔运算符和c这类的布尔运算服有些不同,在python中:a、任何非零数字或非空对象都为真;b、数字零、空对象以及特殊对象None都被认为是假;c、比较和相等测试会递归地应用在数据结构中;d、比较和相等测试会返回True或False;e、布尔and和or运算符会返回真或假的操作对象。:X and Y ;X or Y ; not X。
6、在python中布尔and 和or 返回的是真或假的对象,而不是True或False:or测试中从左到右进行计算对象,返回第一个真的操作对象,如果or两边都是假,那么返回第二个;and测试中从左到右进行计算对象,返回第一个假的对象:
,

。

7、if/else的三元表达式,就例如CPP中的?:三元表达式一样:

当X为真的时候执行Y,当X为假的时候执行Z。而且在python中使用下列表达式也是类似的,因为bool函数会把X转换成对应的整数1或0。然后就能用于从一个列表中挑选真假值:

;举例:

8、


这两个就是or的好处,可以用来做选择一个固定大小集合中非空的对象,不过因为or的截断操作,左右两边是函数的话,提前执行,然后比较结果,不要直接比较函数;表达式((A and B)or C)即总是可以用来模拟if/else语句。ps在后面的运算符重载部分,当我们用类定义新的对象类型的时候,可以用_bool_或_len_方法指定其布尔特性(2.6中叫做_nonzero_).
四、while和for循环(第13章)
while语句是python语句中最通用的迭代结构,简而言之,只要顶端测试一直计算到真值,就会一直执行下面的语句块,格式为:

1、break,略;continue,略;pass,什么事也不做,只是占位置;else,只有当循环正常离开时才会执行(也就是之前没遇到break):

对于pass来说,在3.0中允许在可以使用表达式的任何地方使用…(三个连续的点)来省略代码,因为省略号什么也不做,可以当作pass语句的一种替代方案。
2、因为在python中赋值语句只是语句,不是表达式,这样就排除了一个c容易犯的错误,“==”打成“=”,所以在循环的测试部分不需要写上赋值语句,有三种代替方法:
,

,


for是一个通用的序列迭代器,可以遍历任何有序的序列对象内的元素,可以用于字符串、列表、元组、其他内置可迭代对象以及之后通过类所创建的新对象。它的一般格式是:

它的完整格式:

3、在运行for的时候,会逐个将序列对象中的元素赋值给目标,然后为每个元素执行循环主体,循环主体一般使用赋值的目标来引用序列中当前的元素,就好像那是遍历序列的游标。首行中用作赋值目标的变量名通常是for所在作用域中的变量,这个变量没什么特别,甚至可以在循环主体中修改,不过当控制权回到循环顶端的时候,会自动被设成序列中的下一个元素,循环之后,该变量一般都还是引用了最近所用过的元素,也就是序列中最后的元素,除非通过一个break语句退出循环。
4、任何赋值目标在语法上都能用在for这个关键字之后:
,


其他例子没写,不过也不用写
5、在文件读取的时候,有几种方法:





最后一种是推荐的方法,它不但简单,而且对任意大小的文件都有效,而且不会一次性就把整个文件都载入到内存中,迭代器版本可能更快,不过在3.0中I/O性能稍差。
6、一般来说for比while容易写,而且执行也更快,不过有时候需要特定的方式来迭代,比如每隔一个元素或者两个元素,或者在同一个for循环内,并行遍历一个以上的序列。虽然可以用while循环以及手动索引运算完成,不过python提供了两个内置函数,在for循环内制定迭代:a、内置range函数返回一系列连续增加的整数,作为for中的索引;b、内置zip函数返回并行元素的元组的列表,可用于for中内遍历整个序列。
7、接上6:range函数是通用的工具,虽然常用在for循环中产生索引,但是也可以用在任何需要整数列表的地方,在3.0中,这是一个迭代器,可以按照需要产生元素,所以需要将其包含到一个list调用中以一次性显示器结果:

range当只有一个参数时,会有【0,X);两个参数时【X,Y);三个参数时【X,Y),Z为步长。通常来说,for好于while,而且尽可能少的使用range,因为它没有in 表达式快速。例如下面的代码:

,这个可以实现跳跃,这种方法容易编写,而且更容易阅读,使用range唯一的优点在于它没有复制字符串,而且不会在3.0中创建一个列表,对于很大的字符串来说,这会节省内存。
,


,左边这段代码再次提醒我们这里的x只是引用,而且就算在for中用了,也还是无法改变L中的值,当下一次for循环时,x就自动变成和L中下一个值,相当于遍历位置,而不是元素;右边的通过索引实现修改列表中的值。如果用while的话,可能运行很慢,不过可以使用【x+1 for x in L】来重新生成一个列表。
8、内置函数zip也让我们在for中并行使用多个序列。在基本运算中,zip会取得一个或多个序列作为参数,然后返回元组的列表,将这些序列中的并排的元素配成对,因为zip在3.0中也是一个可迭代对象,所以必须将其包含在一个list调用中以便一次性显示所有的结果:

,

,

这是2个参数的,三个参数也是一样的,当参数的长度不同的时候,zip会以最短序列的长度为准来截断所得到的元组。(2.6中的map这里不介绍,略)
9、zip调用也可以用来产生字典,:
,不过在2.2极其之后的版本中,可以完全跳过for循环,直接将zip的键/值列表传给内置的dict构造函数:


10、在for循环中,会有一个记录当前偏移值的计数器,一个新的内置函数,叫做enumerate:

enumerat函数返回一个生成器对象:简单来说,这个对象有一个__next__方法,有下一个内置函数调用它,并且循环中每次迭代的时候它会返回一个(index,value)元组。可以在for循环中通过元组赋值运算将元组解包:
它会自动执行迭代协议:

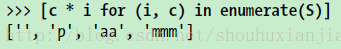
五、迭代器和解析,第一部分(第14章)
“可迭代对象”的概念在python中是相当新颖的,但在语言的设计中很普遍,基本上,这就是序列观念的通用化:如果对象是实际保存的序列,或者可以在迭代工具环境中(如for)一次产生一个结果的对象,就看作是可迭代的。总之,可迭代对象包括实际序列和按照需求而计算的虚拟序列。
1、文件迭代器:每次调用readline方法,就会前进到下一列。到达文件末尾时,就会返回空字符串。不过文件也有一个方法,叫做_next_,差不多有相同的效果:每次调用时,就会返回文件中的下一行,唯一的区别在于到达文件末尾时,_next_会引发内置的StopIteration异常,而不是返回空字符串:


这部分中“可迭代的”指的是支持iter的一个对象,而“迭代器”指的是iter所返回的一个支持next(I)的对象。这个接口就是python中的迭代协议:有_next_方法的对象会前进到下一个结果,而在一系列结果的末尾时,则会引发StopIteration。在python中,任何这类对象都认为是可迭代的,任何这类对象也能以for循环或其他迭代工具遍历,因为所有迭代工具内部工作起来都是在每次迭代中调用_next_,并且捕捉StopIteration异常来确定何时离开:

这个代码是读取文本文件最佳的方法,因为简单、运行最快、而且从内存使用来看也是最好的。虽然>>>for line in open(‘scripy1.py’).readlines():这个依然能用,不过却不是最好的方法,而且从内存上看效果也很差,因为实际上,该版本是一次性把整个文件加载到内存,虽然用while方法:

可是因为for是c语言实现的,而while是通过python虚拟机运行python字节码,所以相对慢一些,不过在3.0中有一种计时技术,可以用来衡量方法的速度情况。
2、为了支持手动迭代代码,3.0提供了一个内置函数next,可以自动调用一个对象的_next_方法,next(X)等同于X._next_(),不过前者简单很多。技术上说,迭代协议有一点值得注意,for循环开始的时候,会通过它传给iter内置函数,以便从可迭代对象中获得一个迭代器,返回的对象含有需要的next方法。不过对于文件来说,不需要这样,因为文件对象自己就是自己的迭代器,文件有自己的_next_方法,所以不需要返回一个不同的对象:

,

文件

不过列表以及很多其他的内置对象,不是自身的迭代器,因为他们支持多次打开迭代器,这样的对象就需要调用iter来启动迭代:



3、除了文件以及列表,其他类型也有其适用的迭代器,比如遍历字典键的经典方法就是获取键的列表,不过在较新的python中,字典有一个迭代器,在迭代环境中,会自动一次返回一个键:>>>I = iter(D);>>>next(I);>>>next(I);其他的python对象蕾西也支持迭代协议,所以可以在for中使用,例如shelves和os.open的结果都是可迭代的:
在2.6中popen对象支持P.next()方法,在3.0中支持P._next_()方法,不支持next(P)内置函数。所以现在也知道enumerate工具的工作方式了:


4、列表解析看上去就像是一个反向的for循环,例子:

,将列表解析写在一个方括号中,该方法写容易,而且运行快,要运行该表达式,python在解释器内部执行一个遍历L的迭代,按照顺序把 x 赋给每个元素,并收集对各元素运行左边表达式的结果。推荐用。
5、因为文件对象中的readlines方法是会在行的末尾包含一个换行符号(\n),如何去掉呢,


第二个表达式做了许多隐式的工作,python扫描文件并自动构建了操作结果的一个列表,因为大多数工作在python解释器内完成,这可能比等价的语句要快好多,而且对于特别较大的文件,列表解析的速度有明显的优势,而且for前面的表达式可以比如:line.rstrip().upper()等。
6、表达式中嵌套的for循环可以有一个相关的if子句,来过滤那些测试不为真的结果项:

该if 子句检查从文件读取的每一行,看他的第一个字符是否是p,如果不是,从结果列表中省略该行。更复杂for循环有:

7、在对象中从左到右扫描的每种工具都使用了迭代协议,比如for循环,列表解析、in成员测试、map内置函数以及像sorted和zip调用这样的内置函数也都使用了迭代协议,当应用于一个文件时,所有的这些使用文件对象的迭代器都自动的按行扫描:
>>>uppers = [line.upper() for line in open(‘script1.py’)];>>>map(str.upper,open(‘script1.py’));>>>list(map(str.upper,open(‘script1.py’)));>>>’y = 2\n’ in open(‘script1.py’);>>>’x = 2\n’ in open (‘script1.py’)。map函数是一个内置函数,将一个函数调用应用于传入的可迭代对象的每一项。map类似于列表解析,但是它更有局限性,因为他需要一个函数而不是一个任意的表达式。在3.0中,它还返回一个可迭代的对象自身,因此,我们需要将它包含到一个list调用中以迫使其一次性给出所有的之,由于map像列表解析一样,与循环和函数都相关,在后续接着介绍。在一些内置函数中,和map以及其他函数不同,sotred在3.0中返回一个真正的列表而不是一个可迭代的对象。
8、接7,其他内置函数也支持可迭代协议,例如sum计算任何可迭代对象中的总数,如果一个可迭代对象中任何的或所有的项为真的时候,any和all内置函数分别返回True;max和min分别返回一个可迭代对象中最大和最小的项。严格的来说,max和min函数也可应用于文件-他们自动使用迭代协议来扫描文件,并且分别选择具有最高和最低的字符串值的行。在list和tuple内置函数,字符串join方法甚至包括序列复制,所有的这些都将在一个打开的文件上工作并且自动一次读取一行:

9、相比较上面的dict调用接受一个可迭代的zip结果,set的调用记忆3.0中新的集合解析和字典解析表达式:

不过集合解析和字典解析都支持列表解析的扩张语法,包括if测试:

10、最后一个介绍的迭代环境,也会在18章学习,在函数调用中用到的一种特殊的*arg形式,他会把一个集合的值解包为单个参数。当然他也会接受任何可迭代对象,包括文件:

由于此调用中的参数解包语法接受可迭代对象,也可能使用zip内置函数来吧zip过得元组unzip,只要对任何另一个zip调用使用之前的或嵌套的zip结果参数:

11、3.0与2.X来说就是更强调迭代,除了与文件和字典这样的内置类型相关的迭代,字典方法keys、values和items都在3.0中返回和迭代对象,就像内置函数range、map、zip和filter所作的那样,他们返回可迭代的对象,在3.0中根据请求产生结果,而不是和2.6中构建结果列表。虽然这样可以节约内存,不过在某种程度上会影响到我们的编码方式,这意味这要在交互模式下显示结果需要额外的录入,这对较大的程序来说很有用,在计算很大的结果列表的时候,这样的延迟计算可以节约内存并避免暂停。
12、range迭代器,返回一个迭代器,该迭代器按照需要产生范围中的数字,而不是在内存中构建一个结果列表,如果需要一个范围列表的话,必须使用list(range(…))来强制一个真正的范围列表:>>>R = range(10);结果是R为range(0,10);>>>I = iter(R);>>>next(I) ;结果为0,接着调用next,结果为1,如果用>>>list(range(10)),结果为【0,1,2,3,4,5,6,7,8,9】;在3.0中range对象只支持迭代、索引以及len函数。它们不支持任何其他的序列操作:>>>len(R),;结果为10;>>>R[0]结果为0。
13、和range类似,map、zip以及filter内置函数在3.0中也变成迭代器以节约内存,而不会在内存中一次性生成一个结果列表,所有的这三个函数不仅像是在2.X中一样处理可迭代对象,而且在3.0中返回可迭代结果。和range不同,他们都是自己的迭代器,换句话说,不能在它们的结果上拥有在那些结果中保持不同位置的多个迭代器:

14、zip内置函数,返回以同样方式工作的迭代器:


还有后面学习的filter内置函数,也是一样:

filter可以接受一个可迭代对象并进行处理,返回一个可迭代对象并在3.0中产生结果。
15、range对象支持len和索引,当不是自己的迭代器,并且它支持在其结果上的多个迭代器,这些迭代器会记住他们各自的位置;

,x相反,zip、map和filter不支持相同结果上多个迭代器:也就是这三个的不同的I1会等于I2,结果就是一个迭代器。
16、在3.0中字典的keys、values和items方法返回可迭代的视图对象,他们一次产生一个结果项,而不是在内存中一次产生全部结果列表。视图项保持和字典中的那些项相同的物理顺序,并且反映对底层的字典做出的修改:

和所有迭代器一样,我们总可以通过把一个3.0字典视图传递到list内置函数中,从而强制构建一个真正的列表,不过这通常不是必须的,除了交互的现实结果或者 应用索引这样的列表操作:

,而且3.0字典仍然有自己的迭代器,它返回连续的键,因此,无需直接在此环境中调用keys:

。由于keys不再返回一个列表,按照排序的键来扫描一个字典的传统编码模式在3.0中不再有效,相反,首先用一个list调用来转换keys视图,或者在一个键视图或者字典自身上使用sorted调用:

17、在20章有更多介绍,29章也还有,后面会看到:a、使用yield语句,用户定义的函数可以转换为可迭代的生成器函数;b、当编写在圆括号中的时候,列表解析转换变为可迭代的生成器表达式;c、用户定义的类通过__iter__或__getitem__运算符重载变得可迭代。
六、文档(第15章)
这部分介绍的:a、设计python的语法模型;b、给那些想了解python工具集的读者资源。如下表 ,可以从很多地方查找python信息,而且都是逐渐增加的,因为文档是实际编程中重要的工具:

1、文档字符串适用于较大型功能的文档,而#注释适用于较小功能的文档。
2、dir内置函数是抓取对象内可用所有属性列表的简单方式,它能够调用任何有属性的对象。比如>>>import sys;>>>dir(sys);要找出内置对象类型提供了哪些属性,可运行dir并传入所需要类型的产量,例如>>>dir([])。任何内置类型的dir结果都包含一组属性,这些属性和该类型的实现相关,他们的开头和结尾都是双下划线,从而保证其独特性。而且dir(str)==dir(’ ‘);dir(list)==dir(【】).
3、除了¥注释以外,python也支持可自动附加在对象上的文档,而且在运行时还可保持查看。从语法上说,这类注释是写出字符串,放在模块文件、函数以及类语句的顶端,就在任何可执行程序代码前,python会自动封装这个字符串,也就是成为所谓的文档字符串,使其成为相应对象的__doc__属性。a、例如下面的文件,其文档字符串出现在文件开端以及其中的函数和类的开头,这里文件和函数多汗注释使用的是三重引号块字符串,但是任何类型的字符串都能用:下面左图,该文档协议的重点在于,注释会保存在__doc__属性中以供查看。因此,要显示这个模块以及其对象打算关联的文档字符串,我们只需要导入这个文件,简单的打印其__doc__属性:


ps:一般都需要明确说出要打印的文档字符串,否则会得到嵌有换行字符的单个字符串。
4、查看内置文档字符串>>>import sys;>>>print(sys.__doc__);>>>print(sys.getrefcount.__doc__);>>print(int.__doc__);不过不需要这么做,还是推荐help方法。
5、常见的编写代码的陷阱:a、冒号;b、从第1汗开始,顶层程序代码从第一行开始;c、空白行在交互模式提示符下很重要;d、缩进要一致;e、不要在python中写c代码;f、使用简单的for循环,而不是while或range;g、注意赋值语句中的可变对象;h、不要期待在原处修改对象的函数会返回结果;i、一定要使用括号调用函数,比如file.close();j、不要在导入和重载中使用扩展名或路径,写成import mod ,而不是import mod.py .
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/109437.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
