文本分类算是自然语言处理领域最最常见的问题了,开源的工具也很好用,但是苦于训练速度缓慢,需要引进多核的版本,开源提供的多核支持参数有限,而同事提供的又有语言障碍,觉得自己探索下多分类器。
分类算法有很多,但是效果较好的基本就是LR和SVM,而这两个算法业内著名的开源代码应该就是liblinear和libsvm,libsvm支不支持多核暂时还未了解,但是liblinear支持的多核版本也就三组(0、2、11),正好避开了我需要用的那组参数,于是就摸索下liblinear的train代码。
一、先说分类
二分类是分类问题中最最基本的功能,这个功能LR和SVM都支持,接着说多分类问题。
多分类可以分为两种:(1).直接多分类,(2)利用多重二分类组合
1.1 直接多分类
softmax就是LR版本的直接多分类形式,而SVM自己就可以直接实现多分类,在目标函数上进行修改,将多个分类面的参数求解合并到一个最优化问题中,通过求解该最优化问题“一次性”实现多类分类类。这种方法看似简单,但其计算复杂度比较高,实现起来比较困难,只适合用于小型问题中。因此利用多重二分类更为常见。
1.2 利用多重二分类组合
(a)一对多法(one-versus-rest,简称OVRSVMs)。
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个分类器。分类时将未知样本分类为具有最大分类函数值的那类。
假如我有四类要划分(也就是4个Label),他们是A、B、C、D。于是我在抽取训练集的时候,分别抽取A所对应的向量作为正集,B,C,D所对应的向量作为负集;B所对应的向量作为正集,A,C,D所对应的向量作为负集;C所对应的向量作为正集,A,B,D所对应的向量作为负集;D所对应的向量作为正集,A,B,C所对应的向量作为负集,这四个训练集分别进行训练,然后的得到四个训练结果文件,在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试,最后每个测试都有一个结果f1(x),f2(x),f3(x),f4(x).于是最终的结果便是这四个值中最大的一个。
原作者注:这种方法有种缺陷,因为训练集是1:M,这种情况下存在biased.因而不是很实用.
我注:liblinear采用的就是这种方法,因而训练速度快,但是占用内存很大。
(b)一对一法(one-versus-one,简称OVOSVMs或者pairwise)。
其做法是在任意两类样本之间设计一个分类器,因此k个类别的样本就需要设计k(k-1)/2个二分类器。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
还是假设有四类A,B,C,D四类。在训练的时候我选择A,B;A,C; A,D; B,C;B,D;C,D所对应的向量作为训练集,然后得到六个训练结果,在测试的时候,把对应的向量分别对六个结果进行测试,然后采取投票形式,最后得到一组结果。
投票是这样的.
A=B=C=D=0;
(A, B)-classifier 如果是A win,则A=A+1;otherwise,B=B+1;
(A,C)-classifer 如果是A win,则A=A+1;otherwise, C=C+1;
…
(C,D)-classifer 如果是A win,则C=C+1;otherwise,D=D+1;
The decision is the Max(A,B,C,D)
原作者注:这种方法虽然好,但是当类别很多的时候,model的个数是n*(n-1)/2,代价还是相当大的.
我注:libsvm采用的就是该种方法,因而准确率会比liblinear高,但是速度会慢很多。
(c)层次支持向量机(H-SVMs)。
层次分类法首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环,直到得到一个单独的类别为止。
对c的详细说明可以参考论文《支持向量机在多类分类问题中的推广》(计算机工程与应用。2004)##没有了解,有空关注下
(d)DAG-SVMS是由Platt提出的决策导向的循环图DDAG导出的,是针对“一对一”SVMS存在误分、拒分现象提出的。算法在训练阶段与“一对一”法同,也要构每两类间的分类器,既有n(n-1)/2个分类器。但在分类阶段,该方法将所有分类器构成一个两向有向环图,包括n(n-1)/2个节点和n个叶。其中每个节点为一个分类器,并与下一层的两个节点(或叶)相连。当对一个未知样本进行分类时,首先从顶部的节点(包含两类)开始,据节点的分类结果用下一层的左节点或右节点继续分类,直到达到底层某个叶为止,该叶所表示类别即为未知样本的类别。DAGSVM在训练上同OVOSVM,都需要训练n*(n-1)/2个分类器,但是在分类的时候借助有向环图的结构,可以只利用(n-1)个分类器就可以完成。而效率上有提升。
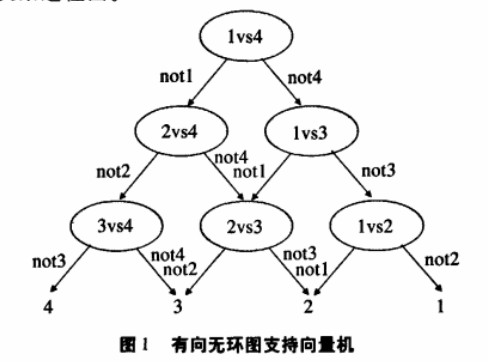

但是DAG-SVMS在分类过程中存在误差积累现象,即若在某个节点处发生分类错误,则会把分类错误延续到该节点的下层节点中、分类错误在越接近根节点的位置发生,误差积累的现象就会越严重,分类的性能也会越差。
我注:二分类真正的结合决策树了……
参考文献:
1.http://blog.sina.com.cn/s/blog_4c98b96001009b8d.html
2.http://www.doc88.com/p-6092154562202.html
转载于:https://www.cnblogs.com/zidiancao/p/5046508.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/109210.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
