本来这一篇是打算写包头在分布式平台中的具体变换过程的。其实文章已经写好了。但是想了这个应该是不能随便发表的。毕竟如果知道了一个包的具体每个字节的意义。能伪造包来攻击系统。其次来介绍一个包的具体变换过程意义不大。在每个分布式系统的里。包的扭转应该是个有不同。我们着重的应该是一种思想。一种共性。而不是个体的具体实现。
这里打算就介绍下大包的处理。其实这个更多的是介绍了下TCP切包。跟分布式没啥关系。。。。 不过这也算是系统的一部分
下面介绍下一个大包的具体处理过程
一、发送请求并分析
1)首先我们在客户端发送一个超过1M 的包给客户端处理,结果是服务端只收了一次recv就拒绝了
2)为了更清晰 我们用tcpdump来抓包处理
[root@localhost git]# tcpdump -i lo port 53101 -w ./target.cap
拿到数据以后放到wireshark里分析


因为TCP包头中会带有12字节的选项—-时间戳
sysctl -a | grep net.ipv4.tcp_wmem net.ipv4.tcp_wmem = 4096 16384 81920
c)为什么服务端拿到一次recv就之间关闭请求了。
因为我们服务端允许客户端传来的请求必须小于1M.所以拿到一次recv以后。就可以解析包头。发现客户端到底需要发送多少个字节。
超过1M 我们认为就是非法包。直接拒绝并关闭客户端连接。
二、接下来我们来分析一个服务端能处理的大包
1、我们发送一个262360 个字节包给服务端
2、这里注意下epoll收包的写法
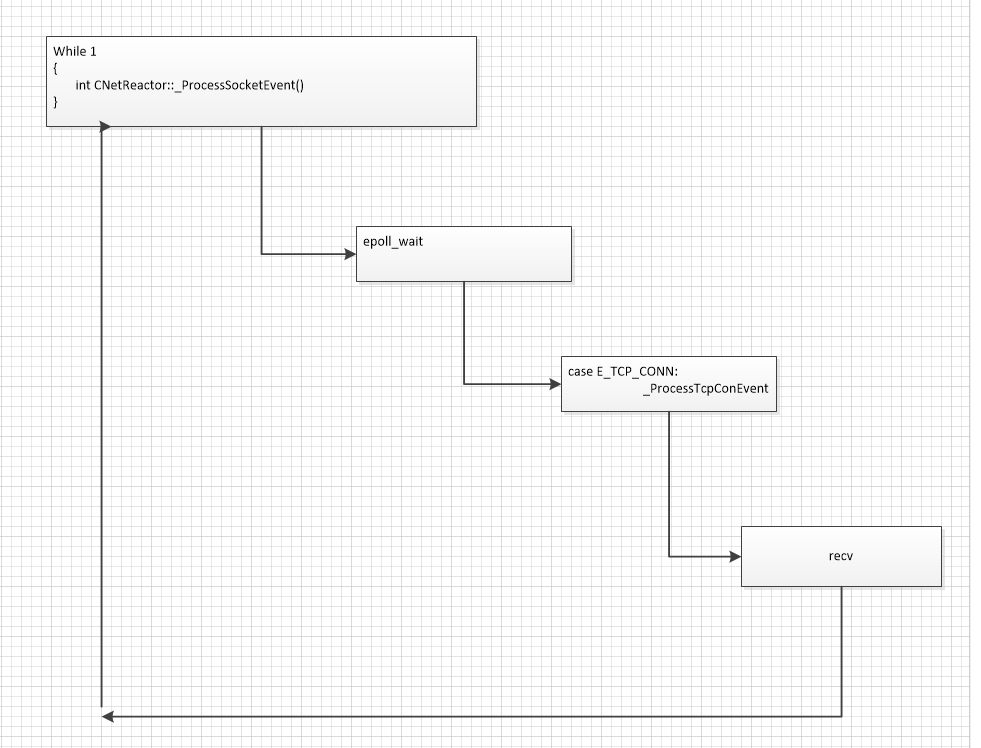
while(1)
{
cnt = (int)recv(m_socket, pBuf,RECVSIZE, 0);
if( cnt >0 )
{
//正常处理数据
}
else
{
if((cnt<0) &&(errno == EAGAIN||errno == EWOULDBLOCK||errno == EINTR))
{
continue;//继续接收数据
}
break;//跳出接收循环
}
}
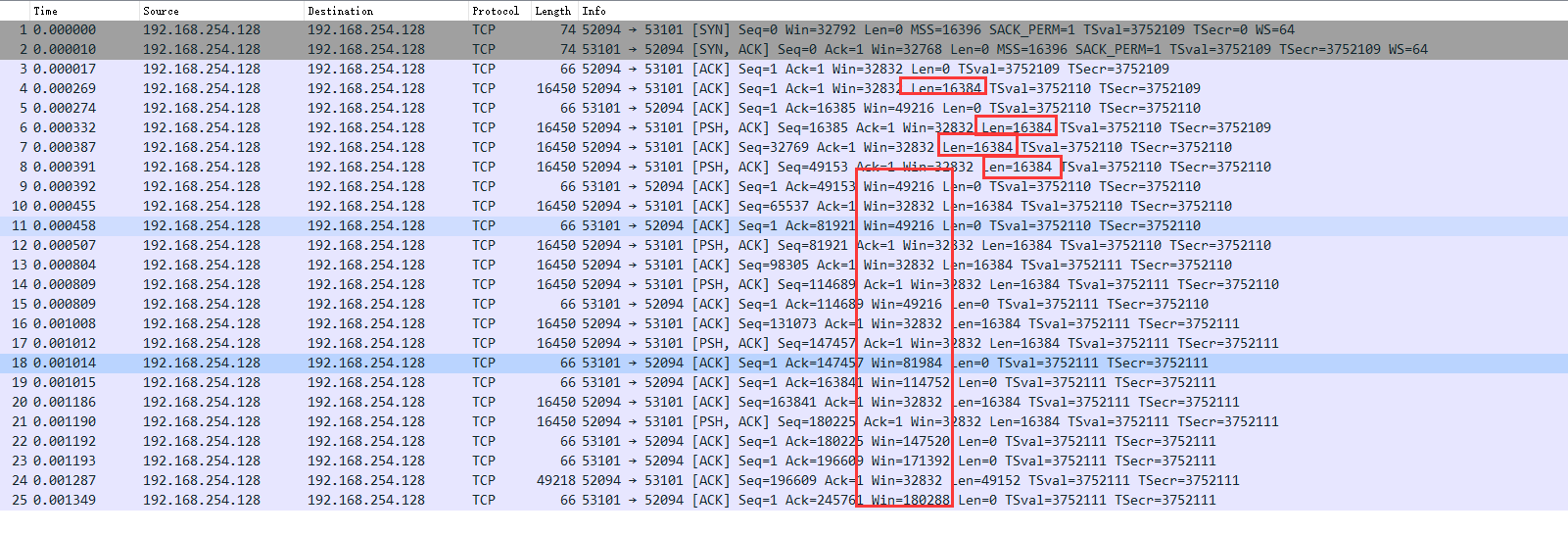
3、结果以及分析
最后收到的结果如下 收了11次。总共262360个字节
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:32768 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:65536 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:32768 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
m_iRecvBufLen:16602 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
我们看到每次发送的length都是16384 但是由于滑动窗口win。时大时小。发送的速度。不一样。导致recv一次能收到的数据也是不一样的
这里最后总结:
a)假如我们在TCP层用更大的数据量来打包会有什么结果呢?
答案是降低了传输效率。
这个就是在以太网上,TCP不发大包,反而发送1448小包的原因。只要这个值TCP才能对链路进行效能最高的利用。
转载于:https://www.cnblogs.com/ztteng/p/5375356.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/109079.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
