大家好,又见面了,我是全栈君。
[TOC]
本文基于Linux2.6.32内核版本号。
引言
软中断、tasklet和工作队列并非Linux内核中一直存在的机制,而是由更早版本号的内核中的“下半部”(bottom half)演变而来。
下半部的机制实际上包含五种,但2.6版本号的内核中。下半部和任务队列的函数都消失了,仅仅剩下了前三者。
介绍这三种下半部实现之前。有必要说一下上半部与下半部的差别。
上半部指的是中断处理程序,下半部则指的是一些尽管与中断有相关性可是能够延后运行的任务。
举个样例:在网络传输中。网卡接收到数据包这个事件不一定须要立即被处理,适合用下半部去实现;可是用户敲击键盘这种事件就必须立即被响应,应该用中断实现。
两者的主要差别在于:中断不能被同样类型的中断打断。而下半部依旧能够被中断打断;中断对于时间很敏感,而下半部基本上都是一些能够延迟的工作。由于二者的这种差别,所以对于一个工作是放在上半部还是放在下半部去运行,能够參考以下4条:
- 假设一个任务对时间很敏感。将其放在中断处理程序中运行。
- 假设一个任务和硬件相关,将其放在中断处理程序中运行。
- 假设一个任务要保证不被其它中断(特别是同样的中断)打断,将其放在中断处理程序中运行。
- 其它全部任务,考虑放在下半部去运行。
有写内核任务须要延后运行。因此才有的下半部,进而实现了三种实现下半部的方法。这就是本文要讨论的软中断、tasklet和工作队列。
下表能够更直观的看到它们之间的关系。 
软中断
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上仅仅是在软中断的基础上加入了一定的机制)。软中断通常是“可延迟函数”的总称,有时候也包含了tasklet(请读者在遇到的时候依据上下文判断是否包含tasklet)。它的出现就是由于要满足上面所提出的上半部和下半部的差别,使得对时间不敏感的任务延后运行,而且能够在多个CPU上并行运行。使得总的系统效率能够更高。
它的特性包含:
- 产生后并非立即能够运行,必须要等待内核的调度才干运行。软中断不能被自己打断(即单个cpu上软中断不能嵌套运行)。仅仅能被硬件中断打断(上半部)。
- 能够并发运行在多个CPU上(即使同一类型的也能够)。所以软中断必须设计为可重入的函数(同意多个CPU同一时候操作),因此也须要使用自旋锁来保其数据结构。
相关数据结构
- 软中断描写叙述符
struct softirq_action{ void (*action)(struct softirq_action *);};
描写叙述每一种类型的软中断,其中void(*action)是软中断触发时的运行函数。 - 软中断全局数据和类型
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
enum
{
HI_SOFTIRQ=0, /*用于高优先级的tasklet*/
TIMER_SOFTIRQ, /*用于定时器的下半部*/
NET_TX_SOFTIRQ, /*用于网络层发包*/
NET_RX_SOFTIRQ, /*用于网络层收报*/
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /*用于低优先级的tasklet*/
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};相关API
- 注冊软中断
void open_softirq(int nr, void (*action)(struct softirq_action *))即注冊相应类型的处理函数到全局数组softirq_vec中。比如网络发包相应类型为NET_TX_SOFTIRQ的处理函数net_tx_action.
- 触发软中断
void raise_softirq(unsigned int nr)实际上即以软中断类型nr作为偏移量置位每cpu变量irq_stat[cpu_id]的成员变量__softirq_pending。这也是同一类型软中断能够在多个cpu上并行运行的根本原因。
- 软中断运行函数
do_softirq-->__do_softirq运行软中断处理函数__do_softirq前首先要满足两个条件:
(1)不在中断中(硬中断、软中断和NMI) 。1
(2)有软中断处于pending状态。
系统这么设计是为了避免软件中断在中断嵌套中被调用,而且达到在单个CPU上软件中断不能被重入的目的。对于ARM架构的CPU不存在中断嵌套中调用软件中断的问题,由于ARM架构的CPU在处理硬件中断的过程中是关闭掉中断的。
仅仅有在进入了软中断处理过程中之后才会开启硬件中断,假设在软件中断处理过程中有硬件中断嵌套,也不会再次调用软中断,because硬件中断是软件中断处理过程中再次进入的,此时preempt_count已经记录了软件中断!
对于其它架构的CPU,有可能在触发调用软件中断前,也就是还在处理硬件中断的时候,就已经开启了硬件中断,可能会发生中断嵌套,在中断嵌套中是不同意调用软件中断处理的。Why?我的理解是,在发生中断嵌套的时候,表明这个时候是系统突发繁忙的时候,内核第一要务就是赶紧把中断中的事情处理完毕,退出中断嵌套。避免多次嵌套,哪里有时间处理软件中断。所以把软件中断推迟到了全部中断处理完毕的时候才干触发软件中断。
实现原理和实例
软中断的调度时机:
- do_irq完毕I/O中断时调用irq_exit。
- 系统使用I/O APIC,在处理完本地时钟中断时。
- local_bh_enable,即开启本地软中断时。
- SMP系统中。cpu处理完被CALL_FUNCTION_VECTOR处理器间中断所触发的函数时。
- ksoftirqd/n线程被唤醒时。
以下以从中断处理返回函数irq_exit中调用软中断为例详细说明。触发和初始化的的流程如图所看到的:
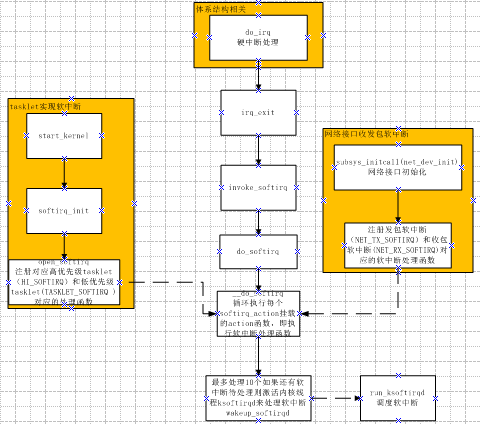
软中断处理流程
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending();
account_system_vtime(current);
__local_bh_disable((unsigned long)__builtin_return_address(0));
lockdep_softirq_enter();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(h - softirq_vec);
trace_softirq_entry(h, softirq_vec);
h->action(h);
trace_softirq_exit(h, softirq_vec);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %td %s %p"
"with preempt_count %08x,"
" exited with %08x?\n"
, h - softirq_vec, softirq_to_name[h - softirq_vec], h->action, prev_count, preempt_count()); preempt_count() = prev_count; } rcu_bh_qs(cpu); } h++; pending >>= 1; } while (pending); local_irq_disable(); pending = local_softirq_pending(); if (pending && --max_restart) goto restart; if (pending) wakeup_softirqd(); lockdep_softirq_exit(); account_system_vtime(current); _local_bh_enable(); }
- 首先调用local_softirq_pending函数取得眼下有哪些位存在软件中断。
- 调用__local_bh_disable关闭软中断,事实上就是设置正在处理软件中断标记,在同一个CPU上使得不能重入__do_softirq函数。
- 又一次设置软中断标记为0,set_softirq_pending又一次设置软中断标记为0,这样在之后又一次开启中断之后硬件中断中又能够设置软件中断位。
- 调用local_irq_enable。开启硬件中断。
- 之后在一个循环中。遍历pending标志的每一位,假设这一位设置就会调用软件中断的处理函数。在这个过程中硬件中断是开启的,随时能够打断软件中断。这样保证硬件中断不会丢失。
- 之后关闭硬件中断(local_irq_disable),查看是否又有软件中断处于pending状态。假设是,而且在本次调用__do_softirq函数过程中没有累计反复进入软件中断处理的次数超过max_restart=10次,就能够又一次调用软件中断处理。假设超过了10次,就调用wakeup_softirqd()唤醒内核的一个进程来处理软件中断。设立10次的限制。也是为了避免影响系统响应时间。
- 调用_local_bh_enable开启软中断。
软中断内核线程
之前我们分析的触发软件中断的位置事实上是中断上下文中,而在软中断的内核线程中实际已经是进程的上下文。
这里说的软中断上下文指的就是系统为每一个CPU建立的ksoftirqd进程。
软中断的内核进程中主要有两个大循环,外层的循环处理有软件中断就处理。没有软件中断就休眠。内层的循环处理软件中断,每循环一次都试探一次是否过长时间占领了CPU,须要调度就释放CPU给其它进程。详细的操作在凝视中做了解释。
set_current_state(TASK_INTERRUPTIBLE);
//外层大循环。
while (!kthread_should_stop()) {
preempt_disable();//禁止内核抢占,自己掌握cpu
if (!local_softirq_pending()) {
preempt_enable_no_resched();
//假设没有软中断在pending中就让出cpu
schedule();
//调度之后又一次掌握cpu
preempt_disable();
}
__set_current_state(TASK_RUNNING);
while (local_softirq_pending()) {
/* Preempt disable stops cpu going offline. If already offline, we'll be on wrong CPU: don't process */
if (cpu_is_offline((long)__bind_cpu))
goto wait_to_die;
//有软中断则開始软中断调度
do_softirq();
//查看是否须要调度,避免一直占用cpu
preempt_enable_no_resched();
cond_resched();
preempt_disable();
rcu_sched_qs((long)__bind_cpu);
}
preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
wait_to_die: preempt_enable();
/* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;tasklet
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高。作为设备驱动程序的开发人员来说,添加了负担。而假设某种应用并不须要在多个CPU上并行运行,那么软中断事实上是没有必要的。
因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
a)一种特定类型的tasklet仅仅能运行在一个CPU上,不能并行,仅仅能串行运行。
b)多个不同类型的tasklet能够并行在多个CPU上。
c)软中断是静态分配的。在内核编译好之后,就不能改变。但tasklet就灵活很多,能够在运行时改变(比方加入模块时)。
tasklet是在两种软中断类型的基础上实现的。因此假设不须要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊使用方法。即延迟情况下的串行运行。
相关数据结构
- tasklet描写叙述符
struct tasklet_struct
{
struct tasklet_struct *next;//将多个tasklet链接成单向循环链表
unsigned long state;//TASKLET_STATE_SCHED(Tasklet is scheduled for execution) TASKLET_STATE_RUN(Tasklet is running (SMP only))
atomic_t count;//0:激活tasklet 非0:禁用tasklet
void (*func)(unsigned long); //用户自己定义函数
unsigned long data; //函数入參
};- tasklet链表
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);//低优先级
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);//高优先级相关API
- 定义tasklet
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
//定义名字为name的非激活tasklet
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
//定义名字为name的激活tasklet
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
//动态初始化tasklet- tasklet操作
static inline void tasklet_disable(struct tasklet_struct *t)
//函数临时禁止给定的tasklet被tasklet_schedule调度。直到这个tasklet被再次被enable;若这个tasklet当前在运行, 这个函数忙等待直到这个tasklet退出
static inline void tasklet_enable(struct tasklet_struct *t)
//使能一个之前被disable的tasklet。若这个tasklet已经被调度, 它会很快运行。tasklet_enable和tasklet_disable必须匹配调用, 由于内核跟踪每一个tasklet的"禁止次数"
static inline void tasklet_schedule(struct tasklet_struct *t) //调度 tasklet 运行,假设tasklet在运行中被调度, 它在完毕后会再次运行; 这保证了在其它事件被处理其中发生的事件受到应有的注意. 这个做法也同意一个 tasklet 又一次调度它自己 tasklet_hi_schedule(struct tasklet_struct *t) //和tasklet_schedule相似,仅仅是在更高优先级运行。当软中断处理运行时, 它处理高优先级 tasklet 在其它软中断之前,仅仅有具有低响应周期要求的驱动才应使用这个函数, 可避免其它软件中断处理引入的附加周期. tasklet_kill(struct tasklet_struct *t) //确保了 tasklet 不会被再次调度来运行,通常当一个设备正被关闭或者模块卸载时被调用。假设 tasklet 正在运行, 这个函数等待直到它运行完毕。
若 tasklet 又一次调度它自己,则必须阻止在调用 tasklet_kill 前它又一次调度它自己,如同使用 del_timer_sync
实现原理
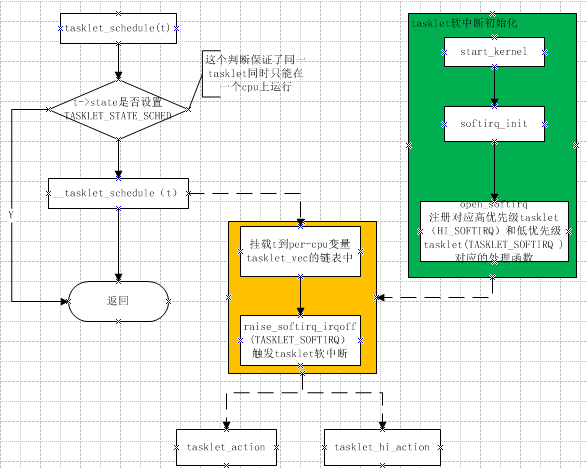
- 调度原理
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);//加入低优先级列表
raise_softirq_irqoff(TASKLET_SOFTIRQ);//触发软中断
local_irq_restore(flags);
}- tasklet运行过程
TASKLET_SOFTIRQ相应运行函数为tasklet_action。HI_SOFTIRQ为tasklet_hi_action,以tasklet_action为例说明。tasklet_hi_action大同小异。
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
list = __get_cpu_var(tasklet_vec).head;
__get_cpu_var(tasklet_vec).head = NULL;
__get_cpu_var(tasklet_vec).tail = &__get_cpu_var(tasklet_vec).head;//取得tasklet链表
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
//运行tasklet
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
//假设t->count的值不等于0,说明这个tasklet在调度之后。被disable掉了。所以会将tasklet结构体又一次放回到tasklet_vec链表。并又一次调度TASKLET_SOFTIRQ软中断,在之后enable这个tasklet之后又一次再运行它
local_irq_disable();
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
工作队列
从上面的介绍看以看出,软中断运行在中断上下文中。因此不能堵塞和睡眠。而tasklet使用软中断实现。当然也不能堵塞和睡眠。但假设某延迟处理函数须要睡眠或者堵塞呢?没关系工作队列就能够如您所愿了。
把推后运行的任务叫做工作(work),描写叙述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct 。而工作线程就是负责运行工作队列中的工作。系统默认的工作者线程为events。
工作队列(work queue)是第二种将工作推后运行的形式。
工作队列能够把工作推后,交由一个内核线程去运行—这个下半部分总是会在进程上下文运行,但由于是内核线程,其不能訪问用户空间。最重要特点的就是工作队列同意又一次调度甚至是睡眠。
通常。在工作队列和软中断/tasklet中作出选择很easy。可使用以下规则:
– 假设推后运行的任务须要睡眠,那么仅仅能选择工作队列。
– 假设推后运行的任务须要延时指定的时间再触发,那么使用工作队列。由于其能够利用timer延时(内核定时器实现)。
– 假设推后运行的任务须要在一个tick之内处理。则使用软中断或tasklet。由于其能够抢占普通进程和内核线程。同一时候不可睡眠。
– 假设推后运行的任务对延迟的时间没有不论什么要求。则使用工作队列,此时通常为无关紧要的任务。
实际上。工作队列的本质就是将工作交给内核线程处理,因此其能够用内核线程替换。
可是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
相关数据结构
- 正常工作结构体
struct work_struct {
atomic_long_t data; //传递给工作函数的參数
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; //链表结构。链接同一工作队列上的工作。
work_func_t func; //工作函数,用户自己定义实现
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
//工作队列运行函数的原型:
void (*work_func_t)(struct work_struct *work);
//该函数会由一个工作者线程运行,因此其在进程上下文中。能够睡眠也能够中断。但仅仅能在内核中运行,无法訪问用户空间。
- 延迟工作结构体(延迟的实现是在调度时延迟插入相应的工作队列)
struct delayed_work {
struct work_struct work;
struct timer_list timer; //定时器。用于实现延迟处理
};- 工作队列结构体
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq; //指针数组,其每一个元素为per-cpu的工作队列
struct list_head list;
const char *name;
int singlethread; //标记是否仅仅创建一个工作者线程
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};- 每cpu工作队列(每cpu都相应一个工作者线程worker_thread)
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
} ____cacheline_aligned;相关API
- 缺省工作队列
静态创建
DECLARE_WORK(name,function); //定义正常运行的工作项
DECLARE_DELAYED_WORK(name,function);//定义延后运行的工作项
动态创建
INIT_WORK(_work, _func) //创建正常运行的工作项
INIT_DELAYED_WORK(_work, _func)//创建延后运行的工作项
调度默认工作队列
int schedule_work(struct work_struct *work)
//对正常运行的工作进行调度,即把给定工作的处理函数提交给缺省的工作队列和工作者线程。工作者线程本质上是一个普通的内核线程。在默认情况下。每一个CPU均有一个类型为“events”的工作者线程,当调用schedule_work时,这个工作者线程会被唤醒去运行工作链表上的全部工作。
系统默认的工作队列名称是:keventd_wq,默认的工作者线程叫:events/n。这里的n是处理器的编号,每一个处理器相应一个线程。比方。单处理器的系统仅仅有events/0这样一个线程。而双处理器的系统就会多一个events/1线程。
默认的工作队列和工作者线程由内核初始化时创建: start_kernel()-->rest_init-->do_basic_setup-->init_workqueues 调度延迟工作 int schedule_delayed_work(struct delayed_work *dwork,unsigned long delay) 刷新缺省工作队列 void flush_scheduled_work(void) //此函数会一直等待。直到队列中的全部工作都被运行。 取消延迟工作 static inline int cancel_delayed_work(struct delayed_work *work) //flush_scheduled_work并不取消不论什么延迟运行的工作,因此。假设要取消延迟工作,应该调用cancel_delayed_work。
以上均是採用缺省工作者线程来实现工作队列。其长处是简单易用,缺点是假设缺省工作队列负载太重。运行效率会很低。这就须要我们创建自己的工作者线程和工作队列。
- 自己定义工作队列
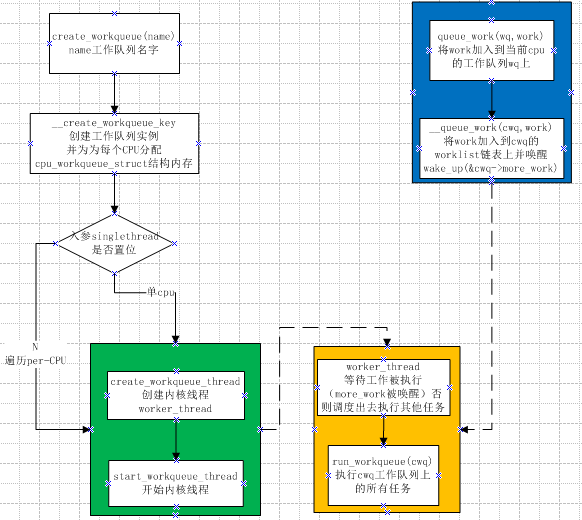
create_workqueue(name)
//宏定义 返回值为工作队列,name为工作线程名称。创建新的工作队列和相应的工作者线程,name用于该内核线程的命名。
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
//相似于schedule_work。差别在于queue_work把给定工作提交给创建的工作队列wq而不是缺省队列。
int queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork, unsigned long delay)
//调度延迟工作。
void flush_workqueue(struct workqueue_struct *wq)
//刷新指定工作队列。 void destroy_workqueue(struct workqueue_struct *wq) //释放创建的工作队列。
实现原理
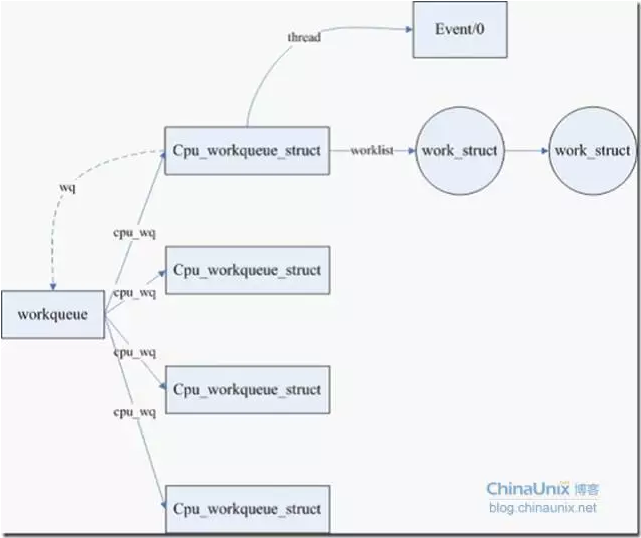
- 工作队列的组织结构
即workqueue_struct、cpu_workqueue_struct与work_struct的关系。
一个工作队列相应一个work_queue_struct。工作队列中每cpu的工作队列由cpu_workqueue_struct表示,而work_struct为其上的详细工作。
关系例如以下图所看到的:
2.工作队列的工作过程 - 应用实例
linux各个接口的状态(up/down)的消息须要通知netdev_chain上感兴趣的模块同一时候上报用户空间消息。这里使用的就是工作队列。
详细流程图例如以下所看到的:
- 是否处于中断中在Linux中是通过preempt_count来判断的,详细例如以下: 在linux系统的进程数据结构里,有这么一个数据结构:
#define preempt_count() (current_thread_info()->preempt_count)
利用preempt_count能够表示是否处于中断处理或者软件中断处理过程中,例如以下所看到的:
# define hardirq_count() (preempt_count() & HARDIRQ_MASK)
#define softirq_count() (preempt_count() & SOFTIRQ_MASK)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK))
#define in_irq() (hardirq_count())
#define in_softirq() (softirq_count())
#define in_interrupt() (irq_count())
preempt_count的8~23位记录中断处理和软件中断处理过程的计数。假设有计数,表示系统在硬件中断或者软件中断处理过程中。 ↩

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/108223.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
