
大家好,又见面了,我是全栈君。
首先声明一下,本文只对十种排序算法做简单总结,并参照一些资料给出自己的代码实现,并没有对某种算法理论讲解,更详细的
了解可以参考以下资料(本人参考):
1、《data structure and algorithm analysis in c 》
2、《大话数据结构》
3、http://blog.csdn.net/morewindows/article/details/7961256
4、http://www.cs.usfca.edu/~galles/visualization/Algorithms.html
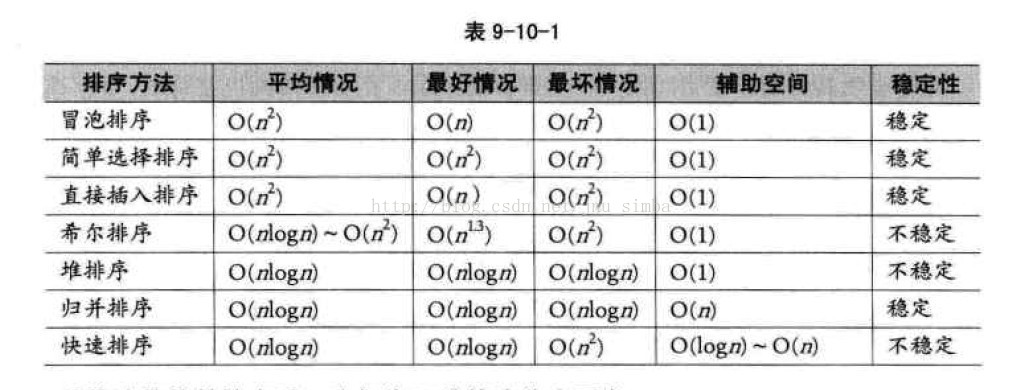
一、冒泡排序
基本思想是:两两比较相邻记录的关键字,如果反序则交换
冒泡排序时间复杂度最好的情况为O(n),最坏的情况是O(n^2)
改进思路1:设置标志位,明显如果有一趟没有发生交换(flag = false),说明排序已经完成
改进思路2:记录一轮下来标记的最后位置,下次从头部遍历到这个位置就Ok
二、直接插入排序
将一个记录插入到已经排好序的有序表中, 从而得到一个新的,记录数增1的有序表
时间复杂度也为O(n^2), 比冒泡法和选择排序的性能要更好一些
三、简单选择排序
通过n-i次关键字之间的比较,从n-i+1 个记录中选择关键字最小的记录,并和第i(1<=i<=n)个记录交换之
尽管与冒泡排序同为O(n^2),但简单选择排序的性能要略优于冒泡排序
四、希尔排序
先将整个待排元素序列分割成若干子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排
序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序(增量为1)。其时间复杂度为O(n^3/2),要好于直接
插入排序的O(n^2)
五、归并排序
假设初始序列含有n个记录,则可以看成n个有序的子序列,每个子序列的长度为1,然后两两归并,得到(不小于n/2的最小整数)个长度为2
或1的有序子序列,再两两归并,…如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序。 时间复杂度为
O(nlogn),空间复杂度为O(n+logn),如果非递归实现归并,则避免了递归时深度为logn的栈空间 空间复杂度为O(n)
六、堆排序
堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆;或者每个节点的值都小于或等于其左
右孩子节点的值,称为小顶堆。
堆排序就是利用堆进行排序的方法.基本思想是:将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶 的根结点.将它移
走(其实就是将其与堆数组的末尾元素交换, 此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元
素的次大值.如此反复执行,便能得到一个有序序列了。 时间复杂度为 O(nlogn),好于冒泡,简单选择,直接插入的O(n^2)
七、快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。时间复杂度为O(nlogn)
下文没有给出快速排序的实现,参考以前的文章。
代码实现:(含3种swap交换函数,6个排序算法,不含快速排序)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 |
#include<iostream> using namespace std; void swap1(int *left, int *right) void swap2(int &left, int &right) void swap3(int &left, int &right) /*****************************************************************/ void BubbleSort1(int arr[], int num) // 改进思路:设置标志位,明显如果有一趟没有发生交换(flag = flase),说明排序已经完成. /**************************************************************************/ void InsertionSort(int arr[], int num) /****************************************************************************/ /*希尔排序:先将整个待排元素序列分割成若干子序列(由相隔某个“增量”的元素组成的)分别进行 } /**************************************************************************/ /* 简单选择排序(simple selection sort) 就是通过n-i次关键字之间的比较,从n-i+1 void SelectSort(int arr[], int num) swap1(&arr[i], &arr[Mindex]); /********************************************************************************/ /*lpos is the start of left half, rpos is the start of right half*/ leftn = rpos – 1; /*main loop*/ while (lpos <= leftn) /*copy rest of the first part*/ /*copy array back*/ void msort(int a[], int tmp_array[], int left, int right) if (left < right) void merge_sort(int a[], int n) if (tmp_array != NULL) else /************************************************************************************/ /*堆排序就是利用堆进行排序的方法.基本思想是:将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶 // 构造大顶堆 void percDown(int *arr, int i, int N) void HeapSort(int *arr, int N) int main(void) |
注:上述7种都是比较排序,下面3种都是非比较排序,理论上可以达到O(n),比比较排序要快,但是这3种都是有其应用背景才能发挥作用的,否则适得其反。
八:计数排序
计数排序(Counting sort)是一种稳定的排序算法。计数排序使用一个额外的数组C,其中第i个元素是待排序数组A中值等于i的元素的个数。然后根据数组C来将A中的元素排到正确的位置。
算法的步骤如下:
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- 对所有的计数累加(从C中的位置为1的元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。
九:桶排序
桶排序 (Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
桶排序以下列程序进行:
- 设置一个定量的数组当作空桶子。
- 寻访串行,并且把项目一个一个放到对应的桶子去。(hash)
- 对每个不是空的桶子进行排序。
- 从不是空的桶子里把项目再放回原来的串行中。
十:基数排序
基数排序(英语:Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 |
#include<stdio.h> #include<string.h> #include<algorithm> using namespace std; /*****************计数排序*******************************/ //记录排序计数,每出现一次在对应位置加1 //确定不比该位置大的数据个数 int *pSort = (int *)malloc(sizeof(int) * num); //从末尾开始拷贝是为了重复数据首先出现的排在前面,即稳定排序 free(pCount); } /*****************桶排序*****************************/ #define bucket_size 10 //与数组元素个数相等 void buck_sort(int arr[], int num) //建立每一个头节点,头节点的key保存当前桶的数据量 for (int j = 0; j < num; j++) //映射函数计算桶号 } } //将桶中的数据拷贝回原数组 //释放分配的动态空间 } } /****************************************************/ /******************** 基数排序LSD*********************/ void base_sort_ISD(int *arr, int num) memset(buck, 0, sizeof(buck)); for(low = 1; high = low * 10, low < MaxValue; low *= 10) //接到末尾 } memset(tail, 0, sizeof(buck)); } } int main(void) int arr1[] = { int arr2[] = { |
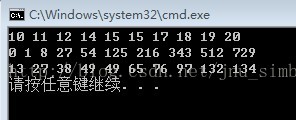
输出为:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107697.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...