大家好,又见面了,我是你们的朋友全栈君。

摘要:2017年,ofo向市场投入了一千多万辆单车,这些单车的投放、运营和调度需要大量数据的支持。本文将从ofo选择MaxCompute的理由以及数据完整性、任务调度、Proxy服务三个方面的实战应用,分享ofo 在MaxCompute的大数据开发之路。
演讲嘉宾简介:龙利民,ofo大数据,大数据副总监。
PPT材料下载地址:http://click.aliyun.com/m/1000003067/
视频地址:http://click.aliyun.com/m/1000003068/
产品地址:http://click.aliyun.com/m/1000003065/
本次分享主要包括以下内容:
一、ofo为什么选择MaxCompute
二、实战应用
1. 数据完整性
2. 任务调度
3. Proxy服务


一、 ofo为什么选择MaxCompute
首先,回顾一下2016年。当时,ofo的数据分析师还在使用Excel+MySQL这样原始的方式来制作报表。在这样的背景下,要求一名研发人员利用两周的时间开发出数据平台。

那么,如何完成这个任务呢?首先,分析一个数据平台主要包括哪些部分。其中,首要问题是集群(大数据下仅利用MySQL经常出现查挂的情况)。有了集群之后,需要进行数据的装载,这就涉及到ETL。对外界来说,他们更关心的是数据本身,因此还需要BI平台,这部分也是需要大量投入的。有了BI平台之后,就可以在平台上制作报表,且涉及到报表的调度。
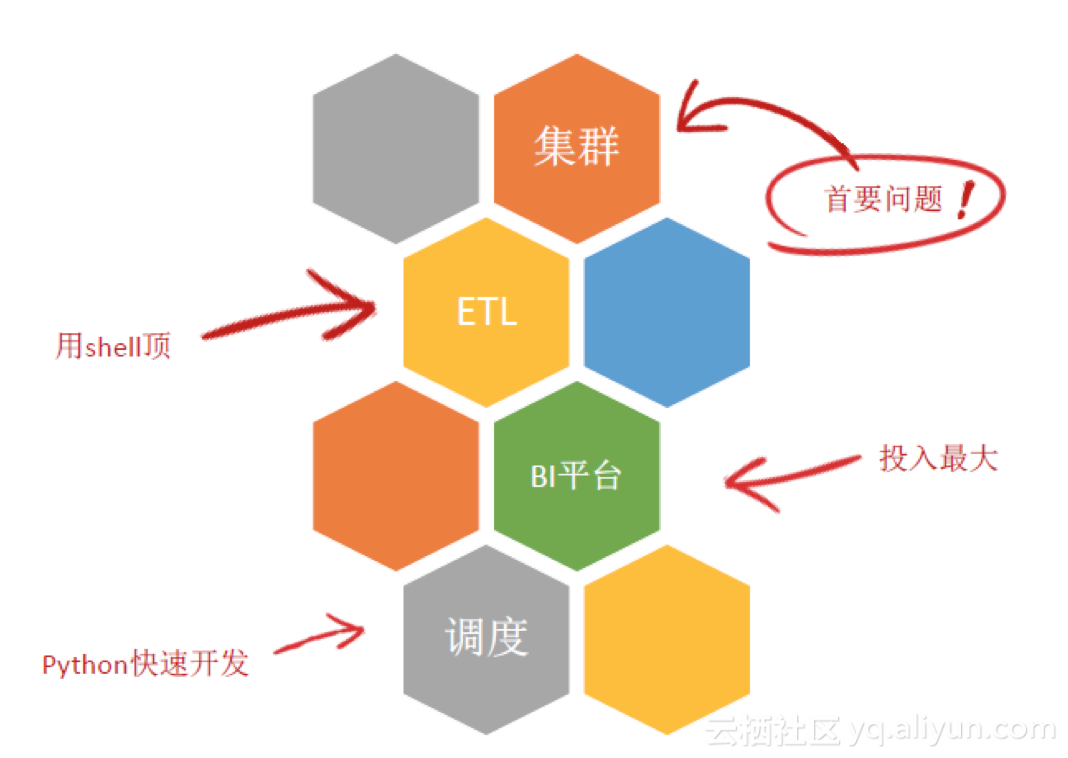
其中,最首要的问题还是集群,是自建集群还是使用云服务?在进行这一选择时,主要从以下六个维度进行考量。
· 存储:事实上,存储也决定了性能。阿里云中就使用了ORC,它是一种列式存储。而MaxCompute使用的也是列式存储。
· 计算:计算性能的要求就是减少耗时。比如,一句SQL语句执行二三十分钟,这样的计算性能显然是不可接受的。
· 费用:费用这一因素通常是不需要考虑的。对于一般小公司而言,MaxCompute按量后付费是最好的选择。
· 稳定性:稳定性需要长期使用才能得以体现,因此这里不做过分强调。
· UDF:共享单车的特性决定了在计算中涉及大量“点”的计算。这里必须用到UDF函数,因此,如果不支持UDF,则不纳入选择范围。
· 文档:MaxCompute的文档写的非常的详细。
综合了多方面的因素,我们最终选择了MaxCompute。那么,在使用了一年半后,其结果怎么样呢?下面简单介绍几个事例。
· 实锤一:某同事在ofo工作一年写的SQL,超过前5年的总和;
· 实锤二:对比自建EMR集群和MaxCompute:集群成本 2 vs 1,运维成本 6 vs 1;
· 实锤三:新孵化项目,业务运转良好的前提下,日费用不到50元。
二、 实战应用
上面介绍的是选择MaxCompute的原因,下面介绍一些在使用过程中的经验。
1. 数据完整性:数据不准的问题是数据分析师最担心的问题。但更令人担心的是,看到数据时无法得知它到底准不准!造成这个问题的一个重要原因就是数据不完整。比如,昨天共产生了100万条数据,但只上传了99万条。因此,一定要保证数据的完整性。
· 数据完整性的定义:程序计算的时候确保T+1天的数据是完整的,非割裂的,即原子的;
· 不注重数据完整性的做法:通过时间来约定计算,数据间的计算依赖也是基于时间;
不注重数据完整性的后果:很难发现数据的错误,需要人力来排查问题;如果不在逻辑上解决掉,会重复出现。
期望中的数据完整性只存在两种情况,要么有数据,且一定是对的,要么就没有数据。
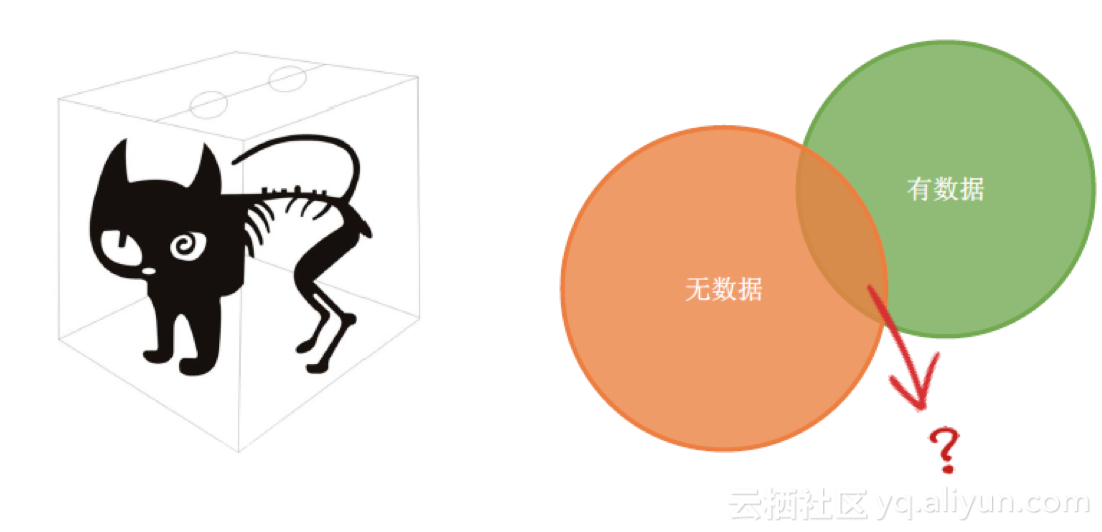
在实际应用中,如何解决数据完整性的问题呢?解决方案主要包括以下几点。
· 用命令的 tunnel upload上传数据,不用SDK;(利用tunnel upload上传数据时,对文件来说,它是具有原子性的,不会存在文件只上传了一半的情况。而SDK是行级上传的。)
· 维护数据标记。(当数据被上传到MaxCompute之后要对数据进行标记,比如当天的数据是否传完,后续的计算也会基于这一标记进行,不会对未ready的数据进行计算。)
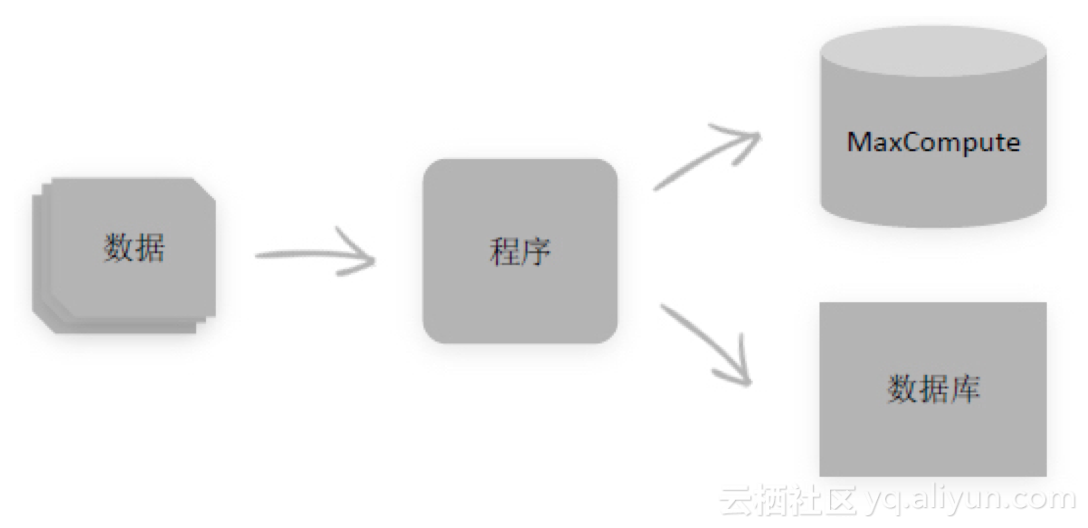
做到这几点后,在实际应用中起到了非常显著的效果:没有出现一起,因为数据不完整导致的数据不准的情况。
在程序上保证了数据完整性后,还要思考另一个问题:自发查询的数据完整性如何解决。比如在HUE中查询时,用户不知道数据是否是完整的。关于解决方案,这里先埋个伏笔,后面会进行详细介绍。
2. 任务调度:每天有近千张报表需要调度计算,报表间的关系会存在相互依赖的问题。如何有效的协作,是任务调度需要解决的问题。
任务调度主要分为下面三种。
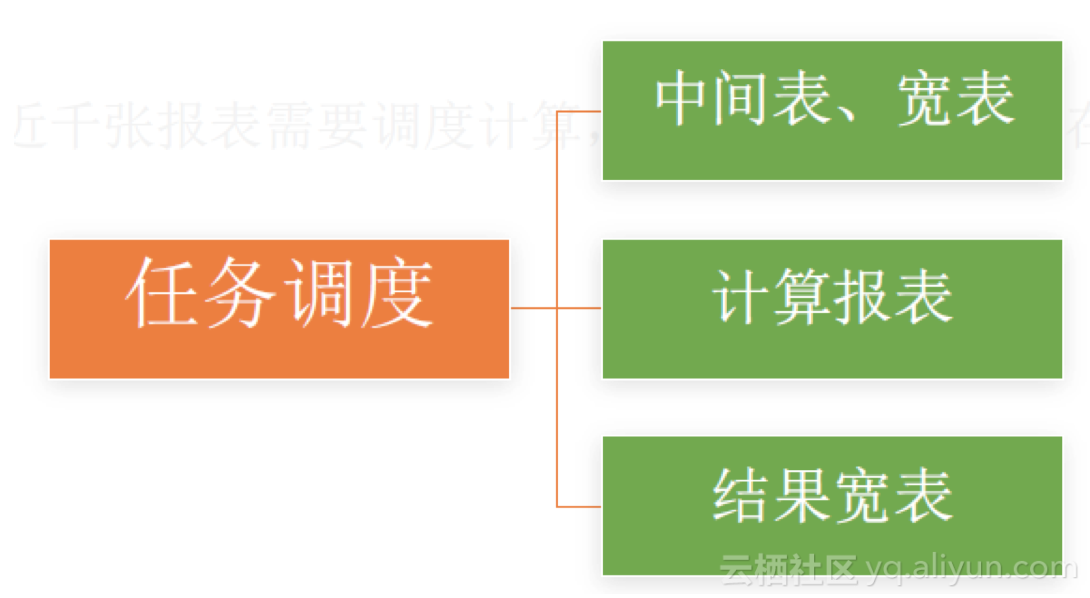
中间表、宽表:我们将最原始的数据表称为原表,比如每天产生的订单表、优惠券表等。但在实际查询中需要将这些表进行关联。比如,想要查询某个订单中的优惠券信息,如果不建立宽表则每次查询都需要写join语句。
计算报表:计算后用于统计的表。
结果宽表:计算报表会存入数据库,这样就会导致数据库中存在非常大量的表。建立结果宽表以便于分析师找到想要分析的指标。
下图展示了对任务调度的期望。

第一,并发,多机多进程,以减少进程挂掉服务器挂掉带来的影响。
第二,协作,要求能建立依赖关系。比如先计算完某张表后再计算依赖它的表。
第三,可监控,当出现故障时能及时报警。
第四,可扩展性,在任务调度中写的语句不仅是SQL,也有可能是python脚本或shell等。第五,资源隔离,在资源调度中要注意,不能让大的SQL把资源全部占用,一旦资源被全部占用,整个计算都会卡住。
下面介绍在实际应用中使用的任务调度技术框架。数据库中存储了每天要计算的任务,生产者从数据库中取数据,并核实数据完整性和依赖关系,核实状态是否为ready,核实完成后进入队列,状态变为waiting,消费者从队列中获取数据并将状态改为running,最后将状态写回数据库。在这一过程中,每个任务都需要将其心跳的状态同步到数据库中,比如某个生产者挂掉之后,如果没有心跳机制,那么它获取的任务将有可能永远在waiting状态。
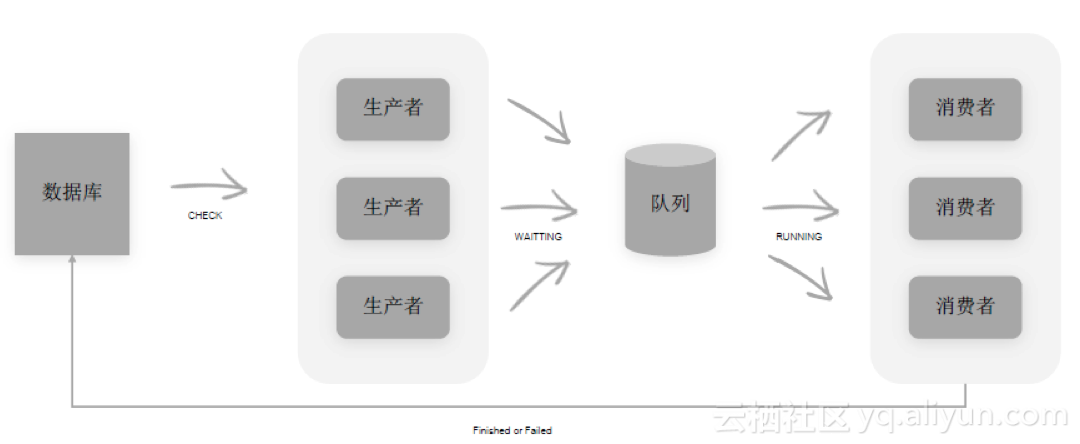
任务调度资源优化和隔离
MaxCompute主要包括两种使用方式:预付费和后付费。预付费,有一个单独的资源池,其中的资源可使用但有上限,并且已经提前付费。后付费,有一个共享的资源池,大家需要抢占资源。
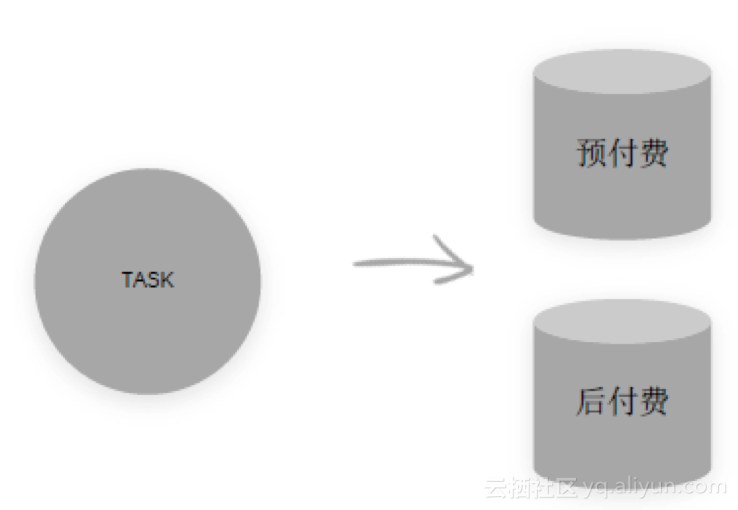
在实际应用中包括以下规则:
· 大任务使用后付费
· 优先级高任务使用预付费
· 优先把预付费填满
· 预付费队列满了,使用后付费
3. Proxy服务
下图展示了Proxy endpoint可以解决的问题。
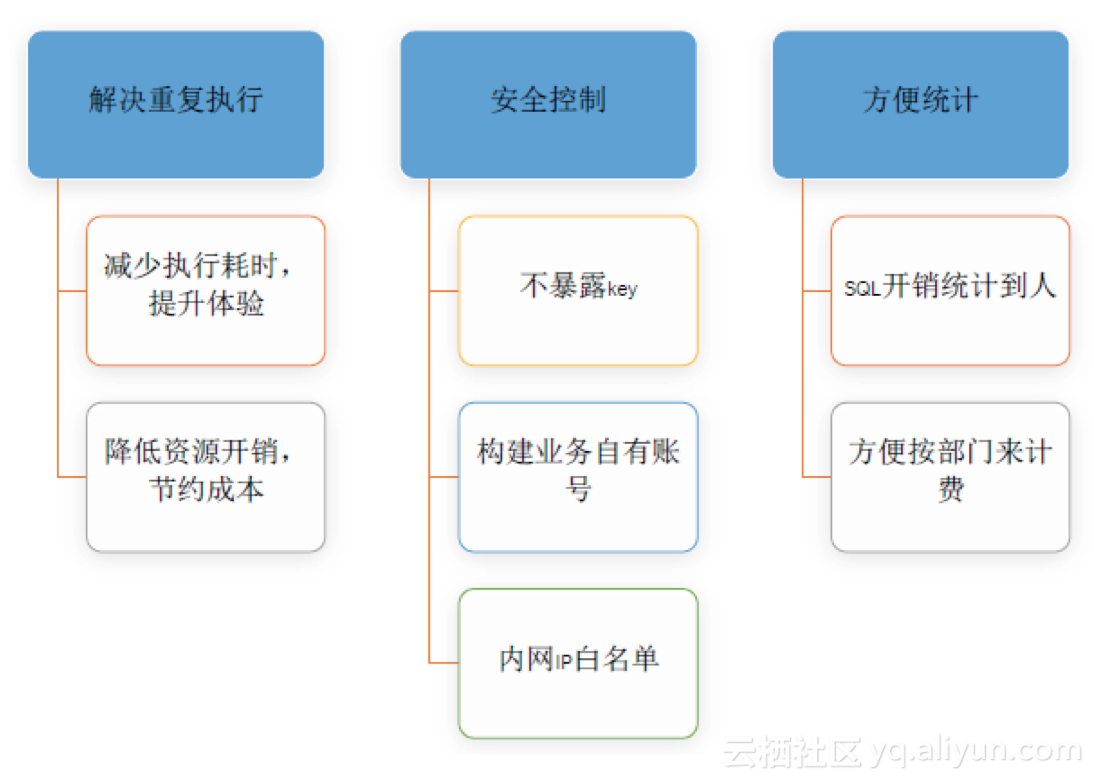
· 解决重复执行:比如两个人重复执行了一样的SQL语句,且数据没有更新。那么第二次执行的时候,会直接返回上一次的结果。这样,第二次查询的过程不会占用MaxCompute的资源。这样,就可以减少执行耗时,提升体验。同时,降低资源开销,节约成本。
· 安全控制:不再对外暴露key,构建业务自由账号,不同的人会拥有不同的账号。同时,构建内网的IP白名单。MaxCompute的白名单是针对外网的,而在内网中也会有很多台机器,如果所有内网机器都拥有访问权限,也是不安全的。
· 方便统计:SQL开销统计到人,并且也可以方便地按部分来计费。
那么,在实际应用中应该如何做呢?总体来讲分为下图两种方案。
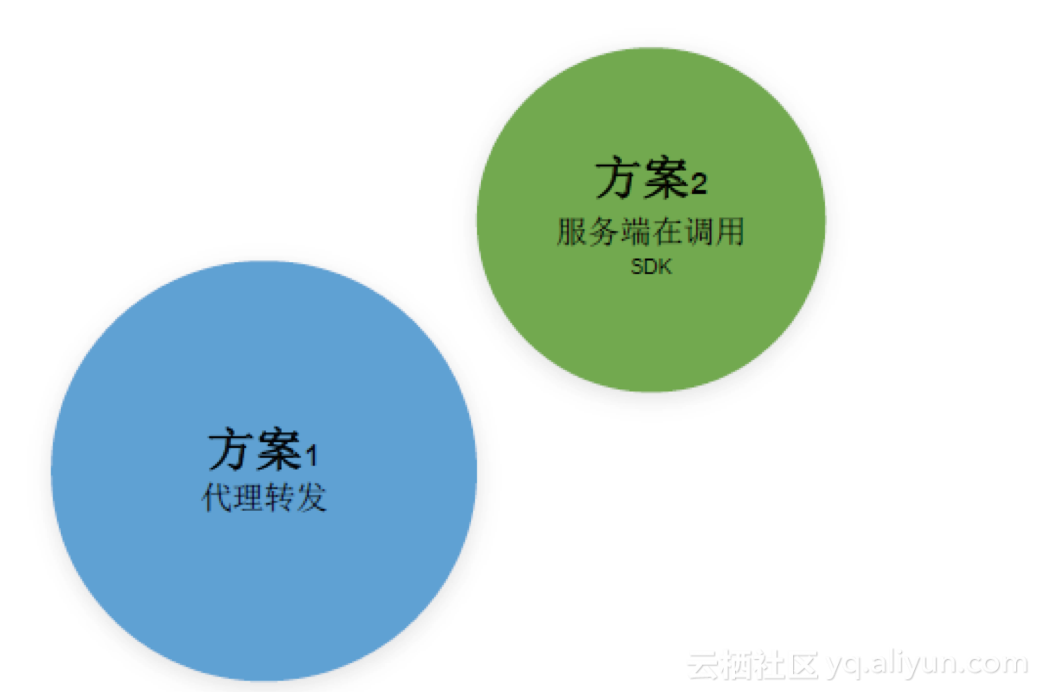
方案一:代理转发。收到数据后转发到MaxCompute然后再通过response返回。
方案二:服务端在调用SDK。利用MaxCompute SDK,每次获得请求后,解析请求中的参数,再返回给SDK。
由于方案二的工作量较大,我们选择了方案一,它具有以下优点。
· 开发工作量小
· Pyodps升级也不影响
· 对于潜在的API接口具有兼容性
· 只实现我们自由账号体系
· ip白名单控制
下图展示了其核心代码。
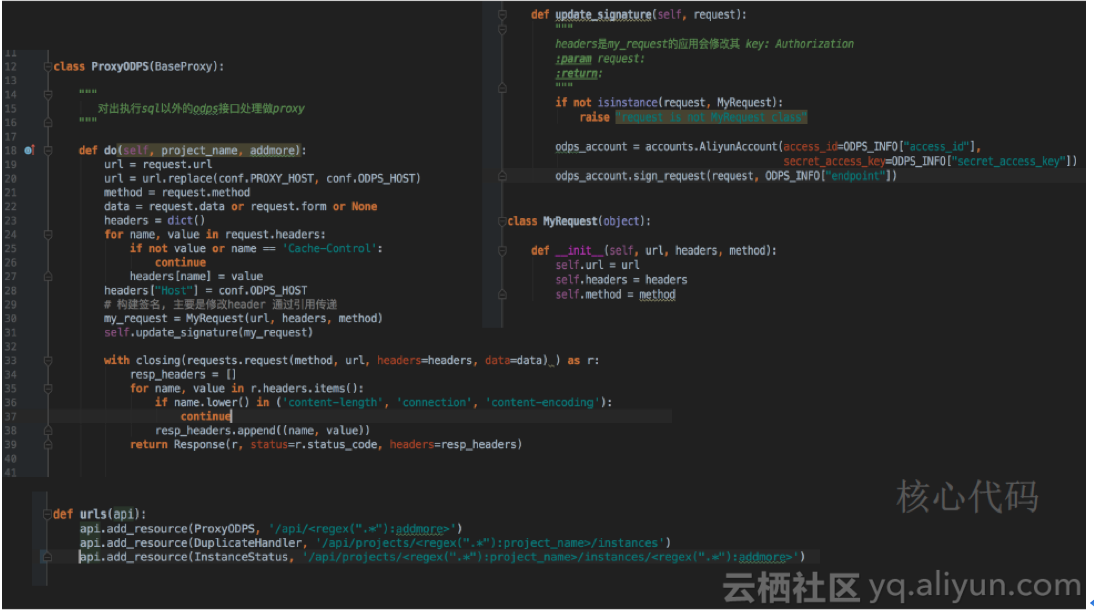
下面简单介绍其中的部分代码。

对所有url进行规则判断,正则表达式中写的越多就会越优先命中。

主要是用于解决SQL代码重复执行的问题。

主要解决命令行的问题。MaxCompute主要分为两个入口,一个是SDK,另一个是命令行。SDK是比较易于实现的。而命令行中会自己生成taskname,每一次请求都会check其taskname。
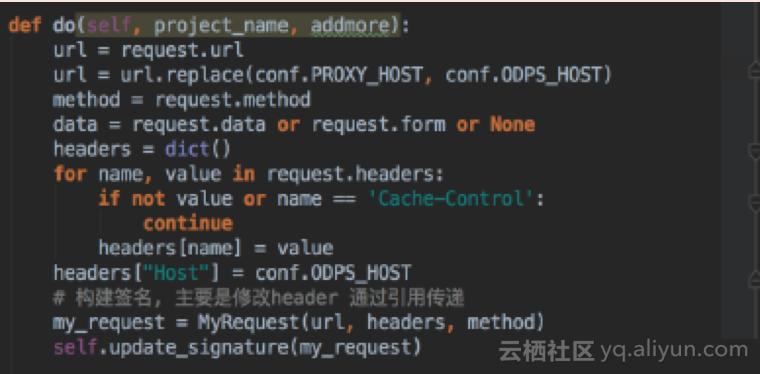
另外,构建安全控制时,一定要有自己的签名。不能使用客户端上传的签名,我们只能使用客户端上传的SSID的前缀。
上面的代码中实现了总体的流程,但具体实现过程中还存在一些问题。
难点1:如何确保优化后结果和实际执行结果一致?
· 从SQL中提取表信息和分区信息
· 在一定延时内,获取表数据的更新信息
解决方案:
· 构建SQL语法树,提取出表,目前还没解决分区
· 另起新进程,捕获表和分区的最后一次修改时间
难点2:命令行返回的适配,为什么呢?
· task name 由客户端生成,例如:console_query_task_152696399361
· taskstatus和instanceprogress都会去校对服务端返回的信息中的task name, 一旦和客户端的task name不一致,会出现:FAILED: task status unknown
解决方案:客户端会从server的所有task name中查找到和自己一样的task name。
· 保存历史所有请求的task name
· 返回所有的task name
通过Proxy服务,取得了不错的效果:
· 提升了体验,具体例子:第一次sql执行耗时的70秒,再次执行不只需要0.9秒;
· 减低了费用,整体费用减低了一半;
· 提升了安全的可控性,不暴露sercret_key给同事;
· 每个业务分配1个账号,能方便统计费用;
· 解决了前面提到的数据完整性问题。
目前,ofo使用的ODPS Proxy,任务调度和数据处理核心代码都已经开源。

转载于:https://my.oschina.net/u/3735980/blog/1833577
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107459.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
