大家好,又见面了,我是你们的朋友全栈君。
今天的主要内容
3. 初识编码
ASCII 8bit 1byte
GBK 16bit 2byte
UNICODE 32bit 4byte
UTF-8 最少8位 1byte 中文24bit 3byte
3,内容编码。
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
|
Bin(二进制)
|
Oct(八进制) |
Dec(十进制)
|
Hex(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
0
|
0
|
00
|
NUL(null)
|
空字符
|
|
0000 0001
|
1
|
1
|
01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
2
|
2
|
02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
3
|
3
|
03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
4
|
4
|
04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
5
|
5
|
05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
6
|
6
|
06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
7
|
7
|
07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
10
|
8
|
08
|
BS (backspace)
|
退格
|
|
0000 1001
|
11
|
9
|
09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
12
|
10
|
0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
13
|
11
|
0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
14
|
12
|
0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
15
|
13
|
0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
16
|
14
|
0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
17
|
15
|
0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
20
|
16
|
10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
21
|
17
|
11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
22
|
18
|
12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
23
|
19
|
13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
24
|
20
|
14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
25
|
21
|
15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
26
|
22
|
16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
27
|
23
|
17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
30
|
24
|
18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
31
|
25
|
19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
32
|
26
|
1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
33
|
27
|
1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
34
|
28
|
1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
35
|
29
|
1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
36
|
30
|
1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
37
|
31
|
1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
40
|
32
|
20
|
(space)
|
空格
|
|
0010 0001
|
41
|
33
|
21
|
!
|
叹号 |
|
0010 0010
|
42
|
34
|
22
|
”
|
双引号 |
|
0010 0011
|
43
|
35
|
23
|
#
|
井号 |
|
0010 0100
|
44
|
36
|
24
|
$
|
美元符 |
|
0010 0101
|
45
|
37
|
25
|
%
|
百分号 |
|
0010 0110
|
46
|
38
|
26
|
&
|
和号 |
|
0010 0111
|
47
|
39
|
27
|
‘
|
闭单引号 |
|
0010 1000
|
50
|
40
|
28
|
(
|
开括号
|
|
0010 1001
|
51
|
41
|
29
|
)
|
闭括号
|
|
0010 1010
|
52
|
42
|
2A
|
*
|
星号 |
|
0010 1011
|
53
|
43
|
2B
|
+
|
加号 |
|
0010 1100
|
54
|
44
|
2C
|
,
|
逗号 |
|
0010 1101
|
55
|
45
|
2D
|
–
|
减号/破折号 |
|
0010 1110
|
56
|
46
|
2E
|
.
|
句号 |
|
00101111
|
57
|
47
|
2F
|
/
|
斜杠 |
|
00110000
|
60
|
48
|
30
|
0
|
数字0 |
|
00110001
|
61
|
49
|
31
|
1
|
数字1 |
|
00110010
|
62
|
50
|
32
|
2
|
数字2 |
|
00110011
|
63
|
51
|
33
|
3
|
数字3 |
|
00110100
|
64
|
52
|
34
|
4
|
数字4 |
|
00110101
|
65
|
53
|
35
|
5
|
数字5 |
|
00110110
|
66
|
54
|
36
|
6
|
数字6 |
|
00110111
|
67
|
55
|
37
|
7
|
数字7 |
|
00111000
|
70
|
56
|
38
|
8
|
数字8 |
|
00111001
|
71
|
57
|
39
|
9
|
数字9 |
|
00111010
|
72
|
58
|
3A
|
:
|
冒号 |
|
00111011
|
73
|
59
|
3B
|
;
|
分号 |
|
00111100
|
74
|
60
|
3C
|
<
|
小于 |
|
00111101
|
75
|
61
|
3D
|
=
|
等号 |
|
00111110
|
76
|
62
|
3E
|
>
|
大于 |
|
00111111
|
77
|
63
|
3F
|
?
|
问号 |
|
01000000
|
100
|
64
|
40
|
@
|
电子邮件符号 |
|
01000001
|
101
|
65
|
41
|
A
|
大写字母A |
|
01000010
|
102
|
66
|
42
|
B
|
大写字母B |
|
01000011
|
103
|
67
|
43
|
C
|
大写字母C |
|
01000100
|
104
|
68
|
44
|
D
|
大写字母D |
|
01000101
|
105
|
69
|
45
|
E
|
大写字母E |
|
01000110
|
106
|
70
|
46
|
F
|
大写字母F |
|
01000111
|
107
|
71
|
47
|
G
|
大写字母G |
|
01001000
|
110
|
72
|
48
|
H
|
大写字母H |
|
01001001
|
111
|
73
|
49
|
I
|
大写字母I |
|
01001010
|
112
|
74
|
4A
|
J
|
大写字母J |
|
01001011
|
113
|
75
|
4B
|
K
|
大写字母K |
|
01001100
|
114
|
76
|
4C
|
L
|
大写字母L |
|
01001101
|
115
|
77
|
4D
|
M
|
大写字母M |
|
01001110
|
116
|
78
|
4E
|
N
|
大写字母N |
|
01001111
|
117
|
79
|
4F
|
O
|
大写字母O |
|
01010000
|
120
|
80
|
50
|
P
|
大写字母P |
|
01010001
|
121
|
81
|
51
|
Q
|
大写字母Q |
|
01010010
|
122
|
82
|
52
|
R
|
大写字母R |
|
01010011
|
123
|
83
|
53
|
S
|
大写字母S |
|
01010100
|
124
|
84
|
54
|
T
|
大写字母T |
|
01010101
|
125
|
85
|
55
|
U
|
大写字母U |
|
01010110
|
126
|
86
|
56
|
V
|
大写字母V |
|
01010111
|
127
|
87
|
57
|
W
|
大写字母W |
|
01011000
|
130
|
88
|
58
|
X
|
大写字母X |
|
01011001
|
131
|
89
|
59
|
Y
|
大写字母Y |
|
01011010
|
132
|
90
|
5A
|
Z
|
大写字母Z |
|
01011011
|
133
|
91
|
5B
|
[
|
开方括号 |
|
01011100
|
134
|
92
|
5C
|
\
|
反斜杠 |
|
01011101
|
135
|
93
|
5D
|
]
|
闭方括号 |
|
01011110
|
136
|
94
|
5E
|
^
|
脱字符 |
|
01011111
|
137
|
95
|
5F
|
_
|
下划线 |
|
01100000
|
140
|
96
|
60
|
`
|
开单引号 |
|
01100001
|
141
|
97
|
61
|
a
|
小写字母a |
|
01100010
|
142
|
98
|
62
|
b
|
小写字母b |
|
01100011
|
143
|
99
|
63
|
c
|
小写字母c |
|
01100100
|
144
|
100
|
64
|
d
|
小写字母d |
|
01100101
|
145
|
101
|
65
|
e
|
小写字母e |
|
01100110
|
146
|
102
|
66
|
f
|
小写字母f |
|
01100111
|
147
|
103
|
67
|
g
|
小写字母g |
|
01101000
|
150
|
104
|
68
|
h
|
小写字母h |
|
01101001
|
151
|
105
|
69
|
i
|
小写字母i |
|
01101010
|
152
|
106
|
6A
|
j
|
小写字母j |
|
01101011
|
153
|
107
|
6B
|
k
|
小写字母k |
|
01101100
|
154
|
108
|
6C
|
l
|
小写字母l |
|
01101101
|
155
|
109
|
6D
|
m
|
小写字母m |
|
01101110
|
156
|
110
|
6E
|
n
|
小写字母n |
|
01101111
|
157
|
111
|
6F
|
o
|
小写字母o |
|
01110000
|
160
|
112
|
70
|
p
|
小写字母p |
|
01110001
|
161
|
113
|
71
|
q
|
小写字母q |
|
01110010
|
162
|
114
|
72
|
r
|
小写字母r |
|
01110011
|
163
|
115
|
73
|
s
|
小写字母s |
|
01110100
|
164
|
116
|
74
|
t
|
小写字母t |
|
01110101
|
165
|
117
|
75
|
u
|
小写字母u |
|
01110110
|
166
|
118
|
76
|
v
|
小写字母v |
|
01110111
|
167
|
119
|
77
|
w
|
小写字母w |
|
01111000
|
170
|
120
|
78
|
x
|
小写字母x |
|
01111001
|
171
|
121
|
79
|
y
|
小写字母y |
|
01111010
|
172
|
122
|
7A
|
z
|
小写字母z |
|
01111011
|
173
|
123
|
7B
|
{
|
开花括号 |
|
01111100
|
174
|
124
|
7C
|
|
|
垂线 |
|
01111101
|
175
|
125
|
7D
|
}
|
闭花括号 |
|
01111110
|
176
|
126
|
7E
|
~
|
波浪号 |
|
01111111
|
177
|
127
|
7F
|
DEL (delete)
|
删除
|
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python
print "你好,世界"
|
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print "你好,世界"
|
4,注释。
当行注释:# 被注释内容
多行注释:”’被注释内容”’,或者”””被注释内容”””
1. 格式化输出
%s 字符串
%d 数字
%% 转义 %
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式


------------ info of Alex Li ----------- Name : Alex Li Age : 22 job : Teacher Hobbie: girl ------------- end -----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobbie = input("Hobbie:")
info = '''
------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name
Name : %s #代表 name
Age : %s #代表 age
job : %s #代表 job
Hobbie: %s #代表 hobbie
------------- end -----------------
''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来
print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d
我们运行一下,但是发现出错了。。。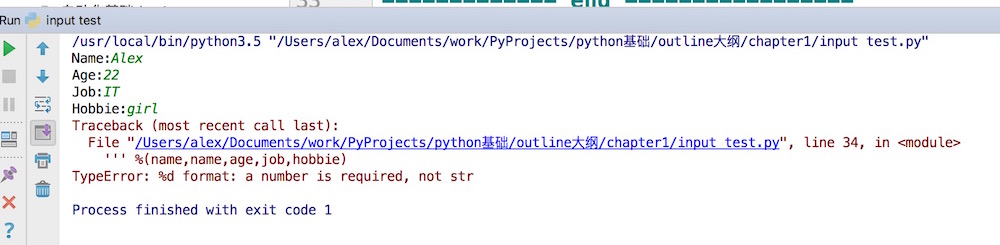
说%d需要一个数字,而不是str, what? 我们明明输入的是数字呀,22,22呀。
不用担心 ,不要相信你的眼睛我们调试一下,看看输入的到底是不是数字呢?怎么看呢?查看数据类型的方法是什么来着?type()
name = input("Name:")
age = input("Age:")
print(type(age))
执行输出是
Name:Alex
Age:22
<class 'str'> #怎么会是str
Job:IT
让我大声告诉你,input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") )
print(type(age))
肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,str( yourStr )
问题:现在有这么行代码
msg = "我是%s,年龄%d,目前学习进度为80%"%('金鑫',18)
print(msg)
这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('金鑫',18)
print(msg)
这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。
2. 运算符
// 整除
% 计算余数
** 求次幂
a+=b => a = a + b
and 两边都是真. 结果才是真,
or 有一个是真. 结果就是真,
not 非真既假. 非假既真
10,基本运算符。
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算数运算
以下假设变量:a=10,b=20

比较运算
以下假设变量:a=10,b=20

赋值运算
以下假设变量:a=10,b=20

逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
1,3>4 or 4<3 and 1==1 2,1 < 2 and 3 < 4 or 1>2 3,2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 4,1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 5,1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
6,not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。

例题:求出下列逻辑语句的值。
8 or 4 0 and 3 0 or 4 and 3 or 7 or 9 and 6
in,not in :
判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
11,流程控制之–if。
假如把写程序比做走路,那我们到现在为止,一直走的都是直路,还没遇到过分叉口,想象现实中,你遇到了分叉口,然后你决定往哪拐必然是有所动机的。你要判断那条岔路是你真正要走的路,如果我们想让程序也能处理这样的判断怎么办? 很简单,只需要在程序里预设一些条件判断语句,满足哪个条件,就走哪条岔路。这个过程就叫流程控制。
if…else 语句
单分支
if 条件:
满足条件后要执行的代码
双分支
"""
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
"""
AgeOfOldboy = 48
if AgeOfOldboy > 50 :
print("Too old, time to retire..")
else:
print("还能折腾几年!")
缩进
这里必须要插入这个缩进的知识点
你会发现,上面的if代码里,每个条件的下一行都缩进了4个空格,这是为什么呢?这就是Python的一大特色,强制缩进,目的是为了让程序知道,每段代码依赖哪个条件,如果不通过缩进来区分,程序怎么会知道,当你的条件成立后,去执行哪些代码呢?
在其它的语言里,大多通过{}来确定代码块,比如C,C++,Java,Javascript都是这样,看一个JavaScript代码的例子
var age = 56
if ( age < 50){
console.log("还能折腾")
console.log('可以执行多行代码')
}else{
console.log('太老了')
}
在有{}来区分代码块的情况下,缩进的作用就只剩下让代码变的整洁了。
Python是门超级简洁的语言,发明者定是觉得用{}太丑了,所以索性直接不用它,那怎么能区分代码块呢?答案就是强制缩进。
Python的缩进有以下几个原则:
- 顶级代码必须顶行写,即如果一行代码本身不依赖于任何条件,那它必须不能进行任何缩进
- 同一级别的代码,缩进必须一致
- 官方建议缩进用4个空格,当然你也可以用2个,如果你想被人笑话的话。
多分支
回到流程控制上来,if…else …可以有多个分支条件
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
写个猜年龄的游戏吧
age_of_oldboy = 48
guess = int(input(">>:"))
if guess > age_of_oldboy :
print("猜的太大了,往小里试试...")
elif guess < age_of_oldboy :
print("猜的太小了,往大里试试...")
else:
print("恭喜你,猜对了...")
上面的例子,根据你输入的值不同,会最多得到3种不同的结果
再来个匹配成绩的小程序吧,成绩有ABCDE5个等级,与分数的对应关系如下
A 90-100
B 80-89
C 60-79
D 40-59
E 0-39
要求用户输入0-100的数字后,你能正确打印他的对应成绩
score = int(input("输入分数:"))
if score > 100:
print("我擦,最高分才100...")
elif score >= 90:
print("A")
elif score >= 80:
print("B")
elif score >= 60:
print("C")
elif score >= 40:
print("D")
else:
print("太笨了...E")
这里有个问题,就是当我输入95的时候 ,它打印的结果是A,但是95 明明也大于第二个条件elif score >=80:呀, 为什么不打印B呢?这是因为代码是从上到下依次判断,只要满足一个,就不会再往下走啦,这一点一定要清楚呀!
12,流程控制之–while循环。
12.1,基本循环
while 条件:
# 循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
|
12.2,循环中止语句
如果在循环的过程中,因为某些原因,你不想继续循环了,怎么把它中止掉呢?这就用到break 或 continue 语句
- break用于完全结束一个循环,跳出循环体执行循环后面的语句
- continue和break有点类似,区别在于continue只是终止本次循环,接着还执行后面的循环,break则完全终止循环
例子:break
count = 0
while count <= 100 : #只要count<=100就不断执行下面的代码
print("loop ", count)
if count == 5:
break
count +=1 #每执行一次,就把count+1,要不然就变成死循环啦,因为count一直是0
print("-----out of while loop ------")
输出
loop 0 loop 1 loop 2 loop 3 loop 4 loop 5 -----out of while loop ------
例子:continue
count = 0
while count <= 100 :
count += 1
if count > 5 and count < 95: #只要count在6-94之间,就不走下面的print语句,直接进入下一次loop
continue
print("loop ", count)
print("-----out of while loop ------")
输出
loop 1 loop 2 loop 3 loop 4 loop 5 loop 95 loop 96 loop 97 loop 98 loop 99 loop 100 loop 101 -----out of while loop ------
12.3,while … else ..
与其它语言else 一般只与if 搭配不同,在Python 中还有个while …else 语句
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出
Loop 1 Loop 2 Loop 3 Loop 4 Loop 5 Loop 6 循环正常执行完啦 -----out of while loop ------
如果执行过程中被break啦,就不会执行else的语句啦
count = 0
while count <= 5 :
count += 1
if count == 3:break
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出
Loop 1 Loop 2 -----out of while loop ------
四,相关练习题。
1、使用while循环输入 1 2 3 4 5 6 8 9 10
2、求1-100的所有数的和
3、输出 1-100 内的所有奇数
4、输出 1-100 内的所有偶数
5、求1-2+3-4+5 … 99的所有数的和
6、用户登陆(三次机会重试)
转载于:https://www.cnblogs.com/jjy9797/p/9216359.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107457.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
