大家好,又见面了,我是你们的朋友全栈君。
摘要: Logstash三个组件的第二个组件,也是真个Logstash工具中最复杂,最蛋疼的一个组件,当然,也是最有作用的一个组件。Logstash三个组件的第二个组件,也是真个Logstash工具中最复杂,最蛋疼的一个组件,当然,也是最有作用的一个组件。
一、grok插件
grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病。
filter{
grok{
#只说一个match属性,他的作用是从message 字段中吧时间给抠出来,并且赋值给另个一个字段logdate。
#首先要说明的是,所有文本数据都是在Logstash的message字段中中的,我们要在过滤器里操作的数据就是message。
#第二点需要明白的是grok插件是一个十分耗费资源的插件,这也是为什么我只打算讲解一个TIMESTAMP_ISO8601正则表达式的原因。
#第三点需要明白的是,grok有超级多的预装正则表达式,这里是没办法完全搞定的,也许你可以从这个大神的文章中找到你需要的表达式
#http://blog.csdn.net/liukuan73/article/details/52318243
#但是,我还是不建议使用它,因为他完全可以用别的插件代替,当然,对于时间这个属性来说,grok是非常便利的。
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}
}二、mutate插件
mutate插件是用来处理数据的格式的,你可以选择处理你的时间格式,或者你想把一个字符串变为数字类型(当然需要合法),同样的你也可以返回去做。可以设置的转换类型 包括: “integer”, “float” 和 “string”。
filter {
mutate {
#接收一个数组,其形式为value,type
#需要注意的是,你的数据在转型的时候要合法,你总是不能把一个‘abc’的字符串转换为123的。
convert => [
#把request_time的值装换为浮点型
"request_time", "float",
#costTime的值转换为整型
"costTime", "integer"
]
}
}三、ruby插件
官方对ruby插件的介绍是——无所不能。ruby插件可以使用任何的ruby语法,无论是逻辑判断,条件语句,循环语句,还是对字符串的操作,对EVENT对象的操作,都是极其得心应手的。
filter {
ruby {
#ruby插件有两个属性,一个init 还有一个code
#init属性是用来初始化字段的,你可以在这里初始化一个字段,无论是什么类型的都可以,这个字段只是在ruby{}作用域里面生效。
#这里我初始化了一个名为field的hash字段。可以在下面的coed属性里面使用。
init => [field={}]
#code属性使用两个冒号进行标识,你的所有ruby语法都可以在里面进行。
#下面我对一段数据进行处理。
#首先,我需要在把message字段里面的值拿到,并且对值进行分割按照“|”。这样分割出来的是一个数组(ruby的字符创处理)。
#第二步,我需要循环数组判断其值是否是我需要的数据(ruby条件语法、循环结构)
#第三步,我需要吧我需要的字段添加进入EVEVT对象。
#第四步,选取一个值,进行MD5加密
#什么是event对象?event就是Logstash对象,你可以在ruby插件的code属性里面操作他,可以添加属性字段,可以删除,可以修改,同样可以进行树脂运算。
#进行MD5加密的时候,需要引入对应的包。
#最后把冗余的message字段去除。
code => "
array=event。get('message').split('|')
array.each do |value|
if value.include? 'MD5_VALUE'
then
require 'digest/md5'
md5=Digest::MD5.hexdigest(value)
event.set('md5',md5)
end
if value.include? 'DEFAULT_VALUE'
then
event.set('value',value)
end
end
remove_field=>"message"
"
}
}四、date插件
这里需要合前面的grok插件剥离出来的值logdate配合使用(当然也许你不是用grok去做)。
filter{
date{
#还记得grok插件剥离出来的字段logdate吗?就是在这里使用的。你可以格式化为你需要的样子,至于是什么样子。就得你自己取看啦。
#为什什么要格式化?
#对于老数据来说这非常重要,应为你需要修改@timestamp字段的值,如果你不修改,你保存进ES的时间就是系统但前时间(+0时区)
#单你格式化以后,就可以通过target属性来指定到@timestamp,这样你的数据的时间就会是准确的,这对以你以后图表的建设来说万分重要。
#最后,logdate这个字段,已经没有任何价值了,所以我们顺手可以吧这个字段从event对象中移除。
match=>["logdate","dd/MMM/yyyy:HH:mm:ss Z"]
target=>"@timestamp"
remove_field => 'logdate'
#还需要强调的是,@timestamp字段的值,你是不可以随便修改的,最好就按照你数据的某一个时间点来使用,
#如果是日志,就使用grok把时间抠出来,如果是数据库,就指定一个字段的值来格式化,比如说:"timeat", "%{TIMESTAMP_ISO8601:logdate}"
#timeat就是我的数据库的一个关于时间的字段。
#如果没有这个字段的话,千万不要试着去修改它。
}
}五、json插件
这个插件也是极其好用的一个插件,现在我们的日志信息,基本都是由固定的样式组成的,我们可以使用json插件对其进行解析,并且得到每个字段对应的值。
filter{
#source指定你的哪个值是json数据。
json {
source => "value"
}
#注意:如果你的json数据是多层的,那么解析出来的数据在多层结里是一个数组,你可以使用ruby语法对他进行操作,最终把所有数据都装换为平级的。
}json插件还是需要注意一下使用的方法的,下图就是多层结构的弊端: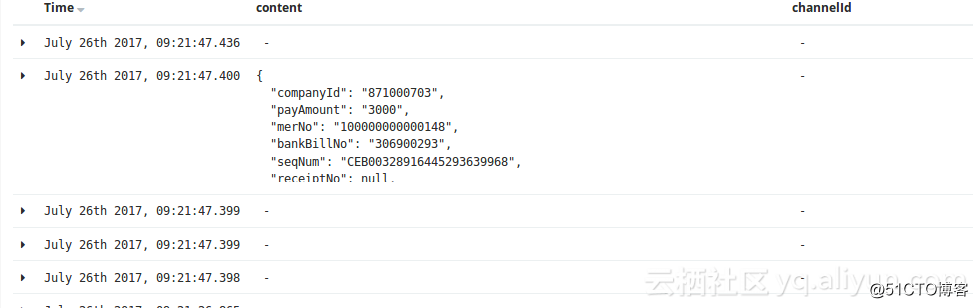

对应的解决方案为:
ruby{
code=>"
kv=event.get('content')[0]
kv.each do |k,v|
event.set(k,v)
end"
remove_field => ['content','value','receiptNo','channelId','status']
}Logstash filter组件的插件基本介绍到这里了,这里需要明白的是:
add_field、remove_field、add_tag、remove_tag 是所有 Logstash 插件都有。相关使用反法看字段名就可以知道。不如你也试试吧。。。。
本文出自:https://yq.aliyun.com/articles/154341?utm_content=m_27283
转载于:https://blog.51cto.com/qiangsh/2157338
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107369.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
