大家好,又见面了,我是你们的朋友全栈君。
本文转自:https://zhuanlan.zhihu.com/p/47838090.
本站转载已经过作者授权。如需转载,请和原作者联系。
最近两年流式计算又开始逐渐火了起来,说到流式计算主要分两种:continuous-based 和 micro-batch。最近在使用基于 micro-batch 模式的 Spark Streaming,正好结合论文介绍一下。这里说的论文是 2013 年发布的 《Discretized Streams: Fault-Tolerant Streaming Computation at Scale》,虽然是 2013 年发表的论文,但是系统的核心逻辑基本没怎么变化,对于理解 Spark Streaming 的系统设计、工作方式还是很有帮助的。注:Spark 在 2016 年推出了 Structured Streaming,后来逐渐演变成 continuous based,基于 micro-batch 这种模式的 Spark Streaming 可能将逐渐淡出吧。
0. abstract
当前(2013 年)分布式流式系统的主要问题在于错误恢复的代价非常高:热备份或者恢复时间长,而且不处理 straggler,这里的 straggler 是分布式系统某一个成员/成分运行滞后于其他组成部分,比如某个 task 节点的运行时间要明显长于其他节点。相比之下,DStream (Spark Streaming 的流式处理模式,全称 discretized streams) 错误恢复更快,而且会处理 straggler。除此之外,还有其他优点包括:提供丰富的算子、高吞吐、可以线性扩展到 100 个节点的集群规模、亚秒级延迟和压秒级故障恢复。最后,DStream 还可以和批处理、交互式查询结合使用。
1. Overview
分布式计算主要分两种:批(batch)处理和流式(streaming)计算,流式计算的主要优势在于其时效性和低延迟。而大规模流式计算系统设计的两个主要问题是错误处理和 straggler 处理。由于流式系统的实时性,错误之后如何快速恢复显得极其重要。
不幸的是,现存的流式系统在这两个点的设计上都不够好。比如 Storm 和 TimeStream 等(这个时候 flink 还没有大规模流行起来) 都是基于 continuous operator 模式,由一个持续运行、有状态的节点负责接收和处理数据。在这种模式下的错误恢复主要由两个方式:一个是 replication,也就是每个 operator 节点有一个 replication 节点;另一个是上游在某个节点失败之后对新的节点提供 replay。在大规模集群模式下,这两种方式都不太可取:replication 会耗费一倍的资源;上游 replay 会耗费一定时间。而且这两种模式都没处理 straggler: 第一种模式会由于 straggler 的存在导致 replication 的过程变慢;第二种模式会将 straggler 当成失败节点,然后进行恢复,代价比较大。
Spark Streaming 的模式是 discretized streams (D-Streams),这种模式不存在一直运行的 operator,而是将每一个时间间隔的数据通过一系列无状态、确定性(deterministic)的批处理来处理。比如对每一秒的数据通过 MapReduce 计算 count。类似的,也可以叠加计算多个批次的数据的 count。简而言之,DStream 模式下,一旦 input 给定,输出状态就是确定的;下面我们会详细说明为什么 DStream 的失败恢复模式要优于前面两种模式。
DStream 的实现难点主要由两个:低延迟和快速错误恢复(包括 straggler)。传统的批处理系统,比如 Hadoop,一般运行的比较慢,主要是因为中间结果要进行持久化(注:这种也代表容错性比较好)。DStream 使用弹性分布式数据集(Resilient Distributed Datasets),也就是 RDD,来进行批处理(注:RDD 可以将数据保存到内存中,然后通过 RDD 之间的依赖关系快速计算)。这个过程一般是亚秒级的,对于大部分场景都是可以满足的。
快速错误恢复主要是通过 DStream 的确定性来提供一种新的恢复机制:par- allel recovery。当一个节点失败之后,我们通过集群的其他节点来一起快速重建出失败节点的 RDD 数据。这种恢复模式相比之前的 replication 和 upstream replay 都要快。这里 straggler 的处理因为我们可以获取到一个批处理 task 的运行时间,所以我们可以通过推测 task 的运行时间判断是不是 straggler。
DStream 的实现系统是 Spark Streaming,基于 Spark 引擎。这个系统可以在 100 个节点的集群上每秒处理 6kw 条数据,并保证亚秒级的延迟,错误恢复也可以保证在亚秒级。当然这些评测数据都是 2013 年,也就是 5 年前。论文继续列举了一些对比数据,这里就不赘述了,总之结论就是 Spark Streaming 的吞吐和线性扩展要优于时下的其他流式计算系统。
最后值得一提的是,因为 Spark Streaming 使用的 RDD model 和批处理相同,所以用户可以将 Spark Streaming 和批处理和交互式出现结合起来。或者将历史 RDD 数据结合 Spark Streaming 一起来用(注:这里的一个场景是线下训练模型,然后通过 Spark Streaming 运用到实时数据上)。
2. Backgroud
很多分布式流式计算系统使用的是 continuous operator 模式,这种模式下会有多个持续运行的 operator,每个 operator 接收自己的数据然后并更新状态。尽管这种方式可以减小延迟,但是因为 operator 本身是有状态的,导致错误恢复起来特别麻烦,如前所述,要么通过 replication,要么通过 upstream backup 和 replay。而这两种方式的缺点也很明显:资源浪费;恢复时间长。
replication 除了成本问题还有数据一致性的问题,如何保证两个节点收到的数据是一致,所以还需要引入分布式协议,比如 Flux 或者 Borealis’s DPC。
upstream backup 模式下,当某个 operator 节点 fail 之后,upstream 将之前发送给失败 operator 节点的数据从某个 checkpoint 重新发送给新的替代节点,这样就会导致恢复时间比较长。论文这里没有说 operator 的状态保存问题,实际上 operator 的状态也是要保存的,而且 checkpoint 要和 upstream 的 checkpoint 一致。
除此之后,straggler 不管在 replication 模式还是 upstream backup 模式都不能很好的处理。
3. DStream
如上所述,DStream 通过一系列小的批处理作业来代替 operator 从而达到快速错误恢复的目的。
3.1 computation model
DStream 将批处理分解成多个一定时间间隔的批处理。在每个时间间隔的数据会被存储成一系列的 RDD,然后通过一系列的算子,比如 map, reduce, group 等进行并行计算,最后将结果输出成新的 RDD 或者输出到系统外(比如 stdout, 文件系统,网络等)。

论文给了一个计算网站 pv 的例子,伪代码如下
pageViews = readStream("http://...", "1s")
ones = pageViews.map(event => (event.url, 1))
counts = ones.runningReduce((a, b) => a + b)
对应的数据流如下图
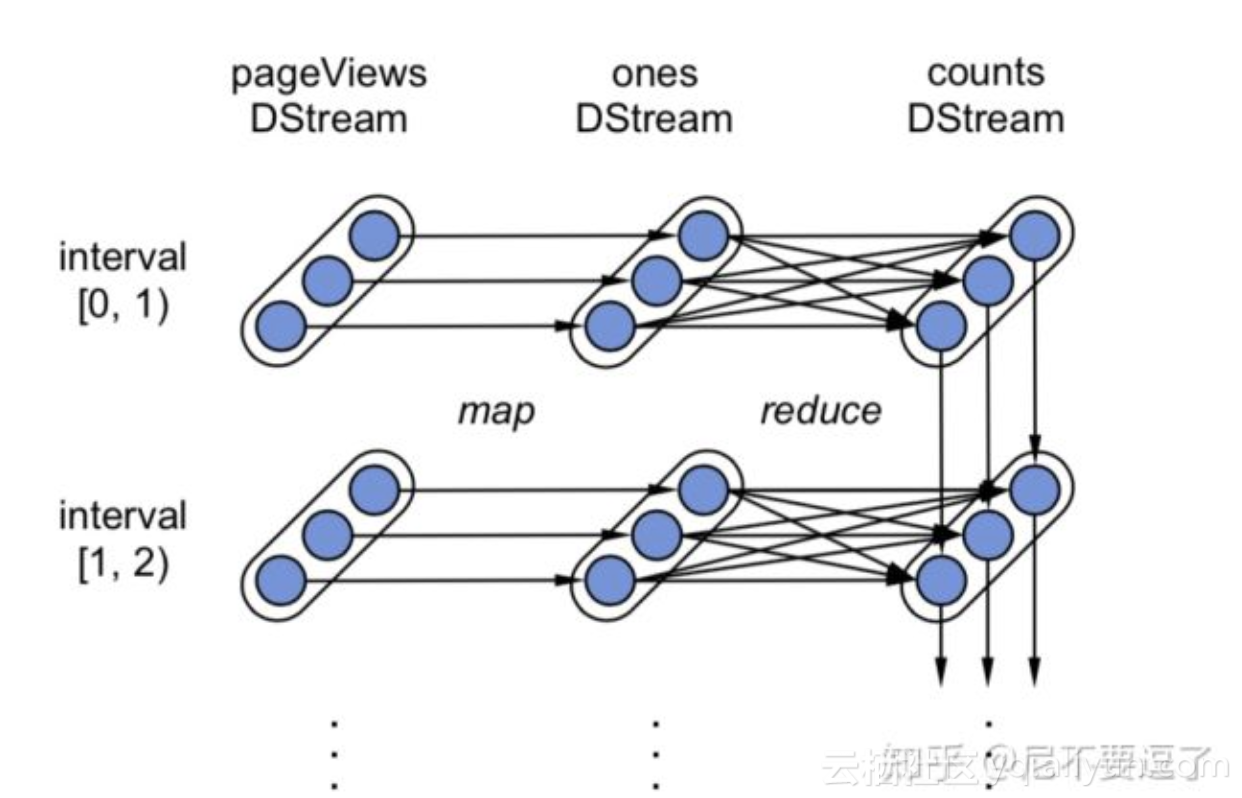
执行过程简单描述如下:
- Spark Streaming 持续不断接收 http url 的 view 数据 pageViews
- 将 pageViews 按 1s 间隔拆分成一系列的 RDD 数据(每个时间间隔也会包含多个 RDD 数据)
- 对 2 中的数据进行 map, reduce 等处理。
系统错误处理通过 DStream 和 RDD 的依赖关系来恢复。依赖关系的维度是 partition,也就是说每个 RDD 可能会分成多个 partition 然后分布在集群的不同机器上,这样当某个机器上的 RDD 数据丢失的时候就可以通过 RDD 的依赖关系从多个机器上来并行的回复数据了。上图中的 DStream 就表示有 3 个 partition。除此之后,如果各个时间间隔没有时序关系,那么每个时间间隔的 RDD 数据也可并行恢复。这正是 DStream 快速错误恢复的关键所在。
3.2 Consistency Semantics
基于 continuous operator 的流处理系统当多个 operator 由于各自的负载不同可能导致某些 operator 滞后,这样整个系统的某个时间点的 snapshot 数据就是不准确的。针对这个问题,Borealis 对不同节点进行同步来避免这个问题;而 storm 直接忽略这个问题。
对于 DStream,由于时间被自然的离散化,而每个时间 interval 对应的 RDDs 都是容错不可变且计算确定性的,所以 DStream 是满足 exactly-once 语义的。
感觉这里有一个前提,论文没有点出来,就是 upstream 的数据是可靠的。
4. System Architecture
系统架构的主题变化不大,但是实现细节再讨论感觉意义不大。Spark Streaming 主要包括三个部分:
- master: 负责记录 DStream 的依赖图(lineage graph)和 task 的调度。我们现在也叫 driver。
- worker: 负责接收数据,存储数据以及执行 task。我们现在也叫 executor。
- client library。
-
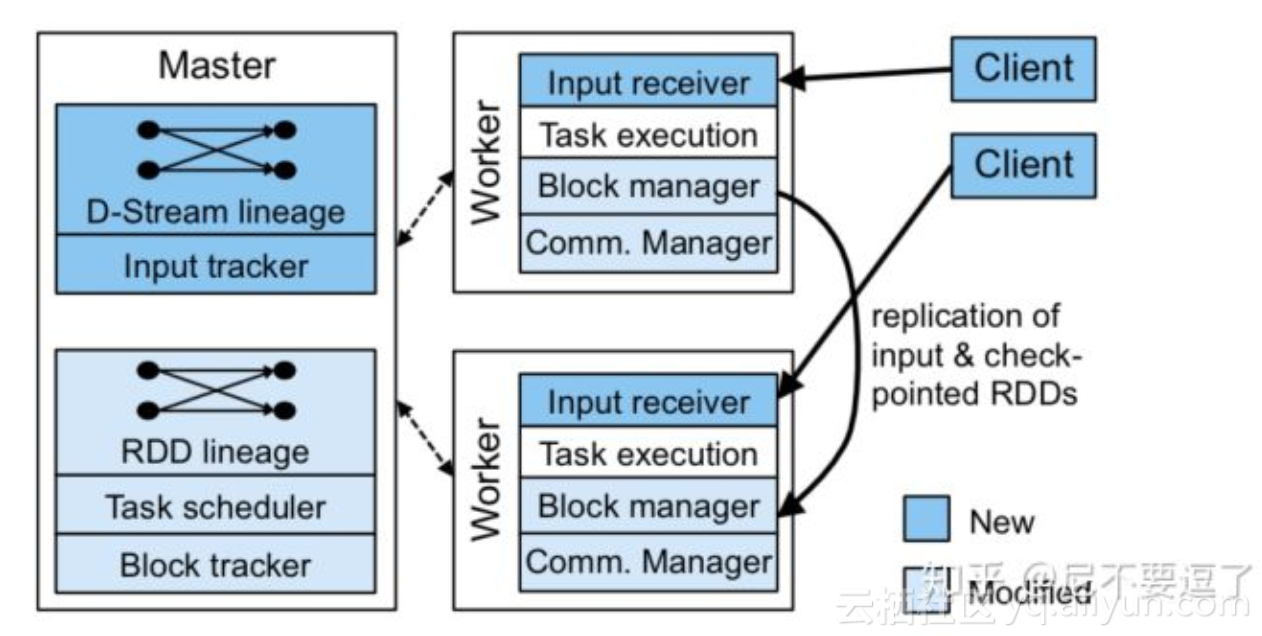
Spark Streaming 的无状态的 task 可以运行在任意节点,相比于传统的流式系统的固定拓扑结构(注:不太确定目前还是不是都是这样),扩展起来会更加的容易。
Spark Streaming 的所有状态都存储在 RDD 中,同时 RDD 的 partition 可以存储到任意节点或者通过多个节点计算。task 计算会考虑数据局部性,比如处理 parition A 的 task 会优先分配到 partition A 所在的节点运行。
下面的实现的一些细节部分不再讨论。
5. Fault and Straggler Recovery
Parallel Recovery 前面已经说过了,这里就不赘述了。这里在补充一下 straggler 的处理。
straggler 的判断非常简单,由于很多 task 都是很快结束,如果一个 task 明显比其他 task 长就可以认为是 straggler。straggler 可以进行迁移,也就是将 task 迁移到其他机器上。
这篇论文虽然很久了,但是对于理解 Spark Streaming 的设计初衷或者设计思路还是很有帮助的。最后,对于论文中其他部分,或者略显陈旧,或者启发意义不大,这里就不再赘述了。对于文章中有失偏颇的地方,还希望多多指教。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/107171.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
