大家好,又见面了,我是你们的朋友全栈君。
1、一些对内存深入理解的案例
以下列举列表,列表/字典/集合这些可变类型都是一样的原理
变量是个地址,指向存储数据的内存空间的地址,它的实质就相当于c语言里的指针。变量和数据都存放在内存里面
1.1内存相关的东西 赋值和修改要区别开来,赋值(重新定义)是重新开辟内存,修改是原内存空间内的改变
1.2修改列表元素的底层原理图解
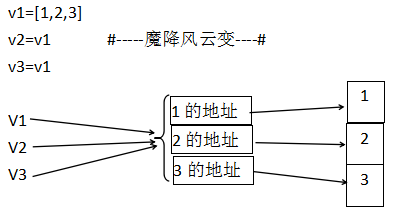
v1=[1,2,3]
v2=v1
v3=v1
v2,v3指向v1指向的地址,三者指向相同的地址。对变量做修改,修改的是同一个地址的值,三者都变化
代码验证:



>>> v1=[1,2,3] >>> v2=v1 >>> v3=v1 >>> id(v1) 45927400 >>> id(v2) 45927400 >>> id(v3) 45927400 >>> v3[0]="mcw" >>> print(v2) ['mcw', 2, 3]
View Code

1.3赋值(重新定义)列表的内存地址变化图解
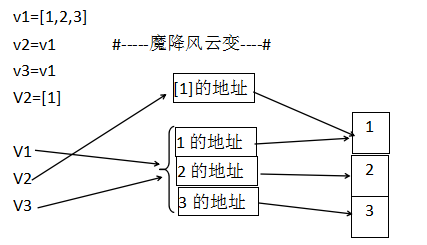
v1=[1,2,3]
v2=v1
v3=v1
v2=[1]
v2重新定义,内存地址改变
代码验证:
>>> v1=[1,2,3] >>> v2=v1 >>> v3=v1 >>> v2=[1] >>> id(v1) 46458520 >>> id(v3) 46458520 >>> id(v2) 46519160 >>> print(v2) [1] >>> id(v2[0]) #数据地址一致 504310928 >>> id(v1[0]) 504310928 >>> id(v3[0]) 504310928
View Code
1.4 字符串.upper()等没有修改原值
>>> v1="mcw" #v1指向一个地址 >>> v2=v1 #v2指向v1指向的地址 >>> v1.upper() #字符串无法修改,让v1变大写。v1.upper()后是开辟一个临时内存存储大写的但是没人接收,v1值没有被修改 'MCW' >>> print(v1,v2) mcw mcw
>>> v1=”mcw” #v1指向一个地址
>>> v2=v1 #v2指向v1指向的地址
>>> v3=v1.upper() #让v1值变大写后v3接收,但是v1值本身没有被修改,
>>> print(v1,v2,v3)
mcw mcw MCW
1.6 列表.append(元素)等修改的是原值
v1=[1,2,3] #v1指向一个地址
v2=v1 #v2指向v1指向的地址
v1.append(v2) #列表可变,可修改,v1追加后v1改变,v2也改变,地址相同
print(v1,v2)
代码验证:
>>> v1=[1,2,3] >>> v2=v1 >>> v1.append("mcw") >>> print(v1,v2) [1, 2, 3, 'mcw'] [1, 2, 3, 'mcw'] >>> id(v1) 46458880 >>> id(v2) 46458880
View Code
1.7列表中修改不可变元素代码以及图解
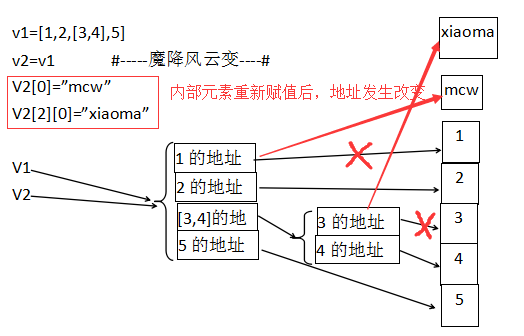
v1=[1,2,[3,4],5]
v2=v1
v2[0]=”mcw”
v2[2][0]=”xiaoma” #原v1[2][0]的值3,如果没有东西指向它,那就是废弃的垃圾,垃圾回收机制会将地址回收
代码验证:
>>> v1=[1,2,[3,4],5] >>> v2=v1 >>> print(v1,v2) [1, 2, [3, 4], 5] [1, 2, [3, 4], 5] >>> v2[0]="mcw" >>> print(v1,v2) ['mcw', 2, [3, 4], 5] ['mcw', 2, [3, 4], 5] >>> id(v2[2][0]) 504310960 >>> id(v2[2][1]) 504310976 >>> id(v2[2]) 46458800 >>> v2[2][0]="xiaoma" >>> id(v2[2][0]) #v2[2][0]地址改变 46485536 >>> id(v2[2][1]) #v2[2][1]地址没变 504310976 >>> id(v2[2]) #外层列表v2[2]地址没发生改变,但是v2[2][0]的指向了另外一个新地址 46458800 >>> print(v1,v2) ['mcw', 2, ['xiaoma', 4], 5] ['mcw', 2, ['xiaoma', 4], 5]
View Code
1.8列表中修改可变元素代码以及图解
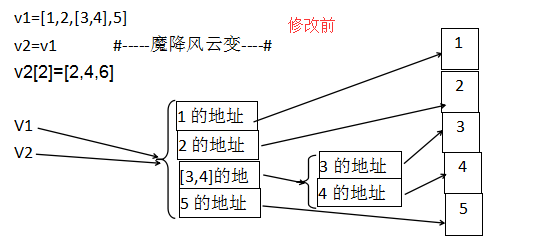
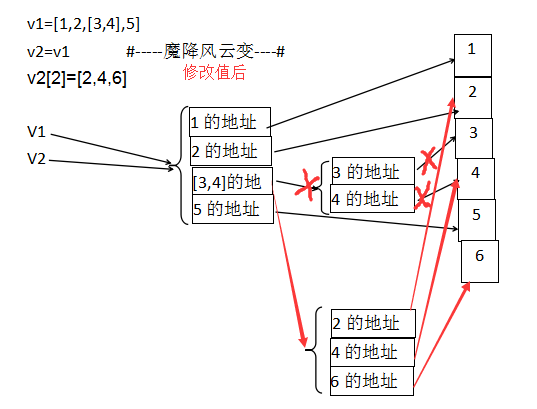
v1=[1,2,[3,4],5]
v2=v1
v2[2]=[2,4,6]
>>> v1=[1,2,[3,4],5] >>> v2=v1 >>> id(v1[2]) #[3,4] 46458880 >>> id(v1[1]) # 2 504310944 >>> id(v1[2][1]) #4 504310976 >>> >>> v2[2]=[2,4,6] >>> id(v1[2]) #[1,4,6] 46563856 >>> id(v1[2][0]) #2 504310944 >>> id(v1[2][1]) #4 504310976
2、深拷贝,浅拷贝
可结合上面一些对内存深入理解的案例进行学习
2.1#str+int+bool拷贝都是这样:
a=”mcw”
b=copy.copy(a) #浅拷贝
代码验证:
>>> import copy >>> a="mcw" >>> b=copy.copy(a) >>> c=copy.copy(a) >>> id(a) is id(b) False >>> bool(a==b) True >>> id(a[0]) is id(b[0]) False
View Code
c=copt.deepcopy(a) #深拷贝
代码验证:
>>> import copy >>> a="mcw" >>> c=copy.deepcopy(a) >>> id(a) is id(c) False >>> bool(a==c) True >>> id(a[0]) is id(c[0]) False
View Code
2.2、#list+set+dict的深浅拷贝
没有嵌套的时候:
浅拷贝:拷贝内存地址,即变量名字 只拷贝空壳
深拷贝:找到所有的可变类型数据(数据存放的内存空间)拷贝一份,不可变数据类型不拷贝,得到的结果一样
有嵌套的时候:
浅拷贝:拷贝内存地址,即变量名字,拷贝空壳
深拷贝:找到所有的可变类型数据(数据存放的内存空间)拷贝一份,不可变数据类型不拷贝,得到的结果一样。嵌套的把变化的拷贝,某层不变的就不拷贝
——–
应该每次都拷贝一份(但由于小数据池)
———————
带疑问的总结:
浅拷贝:
只拷贝第一层(疑问:拷贝列表,新的列表地址是不同的,但是新的列表里列表元素无论是否
可变,都是指向原有元素的地址?只拷贝第一层的地址指向 思考,那么只要是浅拷贝的值和地址都是
一样的吗,无论列表元素是否可变)(遇到元素无论是否可变都是拷贝的相同的指针)
深拷贝:
拷贝嵌套层次中的所有可变类型(疑问:拷贝列表,新的列表地址变了,内部不变的元素地址
指向原列表元素地址,但是可变的元素会再开辟新的内存地址(新的内存地址中的子元素如果不可变那
么指向上层的元素的地址,新的内存地址中的子元素如果可变再开辟新的地址,将它本身放在新的地址
,但是子元素的子元素需要再次做判断 #再次开辟的内存中不变的元素地址和原来还是相同?))(1
、遇到元素不可变的拷贝元素的指针,2、遇到不可变的就生成新的地址。3假如不可变的里面还有元素
,对于这里的元素继续循环执行第一步和第二部的操作)
2.3深浅拷贝特殊情况:
元组里面元素都是不可变的情况:
v1=(1,2,3,4)
浅:没有换地址
深:没有换地址
由于不可变类型,所以拷贝的时候不改变地址
元组里面元素有可变的情况:
元组里面有可变的,会把元组拷贝一下,元组改变了
v1=(1,2,[1,2,3],4)
浅:没变
深:变了
3、文件操作:
3.1文件操作简单介绍:
参考:http://www.runoob.com/python3/python3-file-methods.html
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
#创建空文件,open使用w,a,w+,a+的方式可以创建。r,r+的方式不可以创建空文件
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
3.2、只读:r 只读不能写 文件不存在报错
utf-8的文件,
# 打开文件
file_object = open(‘log.txt’,mode=’r’,encoding=’utf-8′) # 打开方式权限mode有r,read;
w,write; a,append; encoding
读取内容:
变量=打开的文件.read()
content = file_object.read()
print(content)
# 关闭文件
file_object.close()
???open() 加载到内存,write 写入数据到内存中,close将内存数据写入磁盘????
使用范例:
1) file_object = open('mcw.txt',mode='r',encoding='utf-8') content = file_object.read() print(content) file_object.close() ---------------结果: FileNotFoundError: [Errno 2] No such file or directory: 'mcw.txt' 问题原因:没有这个文件 解决办法:在脚本的同一个目录下创建文件mcw.txt,并写入内容:小马过河测试。然后执行代码 2) file_object = open('mcw.txt',mode='r',encoding='utf-8') content = file_object.read() print(content) file_object.close() ----------------结果: (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc2 in position 2: invalid continuation byte 问题原因:Windows下手动创建的mcw.txt文本编码格式为ANSI, 解决办法:打开mcw.txt另存为utf-8格式的mcw.txt文件 3) file_object = open('mcw.txt',mode='r',encoding='utf-8') content = file_object.read() print(content) file_object.close() ------------------结果: 小马过河测试 机器内部似乎有个utf-8 unicode的转换,疑问
3.3、只写:w 只写权限不能读。文件不存在则新建
# 打开文件
file_object = open(‘log.txt’,mode=’w’,encoding=’utf-8′) # r,read; w,write; a,append;#只写
打开的话,会先清空,再写,需要小心。一般用于新建文件
# 写内容
变量=打开的文件.write(“”)
# file_object.write(‘mcw’)
# 关闭文件
打开的文件.close()
file_object.close()
使用范例:
1) file_object = open('mcw.txt',mode='r',encoding='utf-8') file_object.write('mcw') file_object.close() --------------结果: file_object = open('mcw.txt',mode='r',encoding='utf-8') FileNotFoundError: [Errno 2] No such file or directory: 'mcw.txt' 问题原因:没有这个文件 解决办法:在脚本的同一个目录下创建空文件mcw.txt(utf-8格式的),然后执行代码 2) file_object = open('mcw.txt',mode='r',encoding='utf-8') file_object.write('我是魔降风云变') file_object.close() ----------------结果: file_object.write('我是魔降风云变') io.UnsupportedOperation: not writable 问题原因:我的mode是"r",不是"w"模式, 解决办法:修改open的参数mode为需要的可写模式 3) file_object = open('mcw.txt',mode='w',encoding='utf-8') file_object.write('我是魔降风云变') file_object.close() -------------结果: 没有输出,没有文件。执行代码后,在脚本当前目录下创建文件mcw.txt,并写入“我是魔降风云变” 4) file_object = open('mcw.txt',mode='w',encoding='utf-8') file_object.write('我是魔降风云变') file_object.close() --------------结果: 没有输出,打开原本为空的mcw.txt文本,里面出现内容我是魔降风云变
5) file_object = open('mcw.txt',mode='w',encoding='utf-8') file_object.write('我是小马过河') file_object.close() ---------------结果: 没有输出,mcw.txt文本里面的“我是魔降风云变”原内容被新写的“我是小马过河”覆盖掉
6) file_object = open('mcw.txt',mode='w',encoding='gbk') file_object.write('我是mcw') file_object.close() -------------结果: 将上面的代码改为encoding="gbk",在Windows上还是能覆盖掉原来的内容,打开也能正常的看,没乱码 显示.
7、没有读的权限
file_object = open('mcw.txt',mode='w',encoding='utf-8')
file_object.read()
file_object.close()
--------------------------结果:
file_object.read()
io.UnsupportedOperation: not readable
8)
file_object = open('mcw.txt',mode='w',encoding='utf-8')
file_object.close()
--------------结果:
创建一个空文件mcw.txt
3.4、 只追加:a 不能读 文件不存在则新建
open(“文件路径”,mode=”a”,encoding=”utf-8″)
追加,在文件后面添加内容
# 打开文件
file_object = open(‘logfffff.txt’,mode=’a’,encoding=’utf-8′) # r,read(只读); w,write(只写,
先清空,一般用于新建文件); a,append;
# 写内容
file_object.write(‘你好’)
# 关闭文件
file_object.close()
使用范例:
1) file_object = open('mcw.txt',mode='a',encoding='utf-8') file_object.write('我喜欢吃米饭') file_object.close() ---------------结果: 没有打印输出,没有mcw.txt文件。执行代码后,自动在脚本当前目录创建文件mcw.txt,并写入内容: “我喜欢吃米饭”
2) file_object = open('mcw.txt',mode='a',encoding='utf-8') file_object.write(' 我叫小马过河') file_object.close() ---------------结果: 已有文件mcw.txt,文件内容为“我喜欢吃米饭”.执行代码后,文件内容为“我喜欢吃米饭 我叫小马过 河”,追加了“ 我叫小马过河”
3)a没有可读权限
file_object = open('mcw.txt',mode='a',encoding='utf-8')
file_object.write('我喜欢吃米饭')
file_object.read()
file_object.close()
-------------------结果:
file_object.read()
io.UnsupportedOperation: not readable
综上:读,文件不存在会报错,写、追加文件不存在都创建
3.4、可读可写: r+
读:默认从0的光标开始读,也可以通过seek调整光标的位置
写:根据光标的位置,从当前光标位置开始进行写入操作(可能会将其他的文字覆盖)
open(“文件路径”,mode=”r+”,encoding=”utf-8″)
先读后写,先写后读,读前后有写各是什么情况呢
有一个标记,默认在最左边。如果有值,往里写一个字符,覆盖标记后一个字符。
打开的文件.seek(字节),移动标记的。
先读,读完后光标会移到最后,然后再写,不会影响文本已有的内容,相当于追加了
file_object = open(‘log.txt’,mode=’r+’,encoding=’utf-8′)
1)# file_object.seek(2) # 调整光标的位置
content = file_object.read()
file_object.write(‘浪’)
# # 读取内容
# content = file_object.read()
# print(content)
#
# file_object.write(‘666’)
# 关闭文件
file_object.close()
使用范例: 环境为:存在mcw.txt文档,里面内容为“我喜欢吃米饭 我叫小马过河”,开头没有空格 1) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.seek() content = file_object.read() print(content) --------------结果: file_object.seek() TypeError: seek() takes at least 1 argument (0 given) 问题原因:seek里面要接参数,可以接参数“字节” 2) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.seek(0) content = file_object.read() print(content) ----------------结果: ?我喜欢吃米饭 我叫小马过河 备注:似乎seek接0的时候从开头打印,打印出来的开头貌似有点空格; seek接3的时候从文本第一个字开始打印, seek接6的时候,从“喜”开始往后打印 utf-8是三个字节一个汉字 3) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.seek(0) file_object.write('mcw') content = file_object.read() print(content) file_object.close() ---------------结果: 原文档mcw.txt的内容为“我喜欢吃米饭 我叫小马过河”,打印输出内容为“我喜欢吃米饭 我叫小马过 河”,打开文件查看mcw.txt文件内容为“mcw我喜欢吃米饭 我叫小马过河”,开头增加了写入的内容“ mcw”。第二次只打印内容不写入,就会显示出“mcw我喜欢吃米饭 我叫小马过河”
4) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.seek(0) content = file_object.read() file_object.write('666') print(content) file_object.close() ----------------结果: 原文档mcw.txt的内容为“mcw我喜欢吃米饭 我叫小马过河”,打印输出内容为“mcw我喜欢吃米饭 我叫 小马过河”。打开文件查看在文件结尾加了内容“mcw我喜欢吃米饭 我叫小马过河666” 5) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.write('666') content = file_object.read() print(content) file_object.close() --------------结果: 这次没有设置光标,原文档内容“我喜欢吃米饭 我叫小马过河”,写入“666”后查看文件内容“666我 喜欢吃米饭 我叫小马过河” 这次没有设置光标,原文档内容“我喜欢吃米饭 我叫小马过河”,写入“小马”后查看文件内容“小马 喜欢吃米饭 我叫小马过河” 这次没有设置光标,并且在上次操作后不是重新修改保存的文档,原文档内容“小马喜欢吃米饭 我叫小 马过河”,写入“,”后查看文件内容“,马喜欢吃米饭 我叫小马过河” 这次没有设置光标,并且在上次操作后不是重新修改保存的文档,原文档内容“,马喜欢吃米饭 我叫小 马过河”,写入“ccccc”后查看文件内容“ccccc枩娆㈠悆绫抽キ 鎴戝彨灏忛┈杩囨渤”,乱码了 这次没有设置光标,原文档内容“我喜欢吃米饭 我叫小马过河”,写入“ cc”后(cc前有个空格)查看 文件内容“ cc我喜欢吃米饭 我叫小马过河”,没有乱码 6) file_object = open('mcw.txt',mode='r+',encoding='utf-8') file_object.seek(0) file_object.write('小') content = file_object.read() print(content) file_object.close() ---------------结果: 原文件内容“我喜欢吃米饭 我叫小马过河”,seek(0),写入“小”后,文件内容变为“小我喜欢吃米 饭 我叫小马过河” pycharm打印输出“我喜欢吃米饭 我叫小马过河” 原文件内容“我喜欢吃米饭 我叫小马过河”,seek(0),写入“小丽”后,文件内容变为“小丽喜欢吃 米饭 我叫小马过河” pycharm打印输出“喜欢吃米饭 我叫小马过河” 原文件内容“我喜欢吃米饭 我叫小马过河”,seek(0),写入“你喜欢吃面条 你叫杨舟舟”后,文件 内容变为“你喜欢吃面条 你叫杨舟舟过河”,pycharm打印输出“过河” 原文件内容“我喜欢吃米饭 我叫小马过河”,seek(2),写入“小小”后,文件内容变为“锘灏忓皬滄 鍚冪背楗?鎴戝彨灏忛┈杩囨渤”,pycharm打印输出“UnicodeDecodeError: 'utf-8' codec can't decode byte 0x9c in position 0: invalid start byte”由于seek的字节数不是3的倍数,也就是不是 一个utf-8汉字 3个字节的倍数报错。我是重新把文件转为utf-8操作才能重新用这个文件的 原文件内容“我喜欢吃米饭 我叫小马过河”,seek(0),写入“mm”后,文件内容变为“mm挎垜鍠滄 鍚冪背楗?鎴戝彨灏忛┈杩囨渤”,pycharm打印输出“UnicodeDecodeError: 'utf-8' codec can't decode byte 0x9c in position 0: invalid start byte”由于写入的字节数不是3的倍数,也就是不是 一个utf-8汉字 3个字节的倍数报错。我是重新把文件转为utf-8操作才能重新用这个文件的 原文件内容“ cc我喜999吃米饭 我叫小马过河”,seek(6),写入“666”后,文件内容变为“ cc我 666999吃米饭 我叫小马过河”,覆盖了第6个字节之后的三个字节。 pycharm打印输出“999吃米饭 我 叫小马过河”
综上:seek(字节数)或写入的字节数不是3的倍数就会出现乱码。Windows上和pycharm上操作,txt文本
前面有三个字节的空内容,可以写入内容,如果写入的大于3个字节的内容,就会开始覆盖第一个中文字
符。如果是代码操作后没有手动粘贴保存文档的话,重新对文件操作,开头没有那3个字节了。如果写入
的不够3的倍数,加空格补充到3的倍数不会乱码。seek(字节数),再写入,会从字节数之后开始覆盖。
不用seek,默认从头开始覆盖.
3.5、w+写读: w+ 不同于读写
读:默认光标永远在写入的最后或0,也可以通过 seek 调整光标的位置。
写:写入时会将文件清空,读取时需要调整光标到想读的位置(光标默认在最后,到开头seek(0))
open(“文件路径”,mode=”w+”,encoding=”utf-8″)
file_object = open(‘mcw.txt’,mode=’w+’,encoding=’utf-8′)
data = file_object.read()
print(data)
file_object.write(‘小马过河’)
file_object.seek(0)
data = file_object.read()
print(data)
file_object.close()
实验案例: 1) file_object = open('mcw.txt',mode='w+',encoding='utf-8') data = file_object.read() print(data) ------------------结果: mcw.txt中有内容,执行代码之后情况,没有读出内容,即使在读之前添加seek也不行。执行写入时会将文件清空 2) file_object = open('mcw.txt',mode='w+',encoding='utf-8') file_object.write("魔降风云变") data = file_object.read() print(data) ------------------结果: mcw.txt中有内容“小马过河”,多次执行代码都是写入了“魔降风云变”,并将之前的已有的内容清空了。pycharm没有打印出内容。
3) file_object = open('mcw.txt',mode='w+',encoding='utf-8') file_object.write("小马过河") file_object.seek(6) data = file_object.read() print(data) file_object.close() ----------------------结果: mcw.txt中有内容“魔降风云变”,多次执行代码都是写入了“小马过河”,写完后seek(6),读取到第6个字节之后的内容“过河”并在pycharm打印出来。,每次执行都将之前已有的内容清空了。
3.6、a+
- 读:默认光标在最后,也可以通过 seek 调整光标的位置。然后再去读取。
- 写:永远写到最后。
pen(“文件路径”,mode=”a+”,encoding=”utf-8″)
光标默认放在最后。想读先要移动光标到开头)(seek(0))。a+ 不存在修改,不会在光标处往后覆盖.只要一写,无论光标在哪里都会立即跳到
最后然后进行追加内容。
文件打开方式
file_object = open(‘mcw.txt’,mode=’a+’,encoding=’utf-8′)
# file_object.seek(0)
# data = file_object.read()
# print(data)
file_object.seek(0)
file_object.write(‘666’)
file_object.close()
实验案例: 1) file_object = open('mcw.txt',mode='a+',encoding='utf-8') file_object.write("小马过河") file_object.close() -------------结果: mcw.txt文件不存在就会创建,并写入内容“小马过河” 2) file_object = open('mcw.txt',mode='a+',encoding='utf-8') file_object.seek(0) data = file_object.read() print(data) -----------------结果: 如果没有file_object.seek(0),光标默认在最后,没有读出内容。设置光标在开头才读出了内容,注意:读内容需要有变量去接收内容并将它打印,才能显示出来 3) file_object = open('mcw.txt',mode='a+',encoding='utf-8') file_object.write("下午,你好呀!") file_object.seek(0) data=file_object.read() print(data) -----------------结果: 原文件内容为“小马过河”,执行后,文件后面追加了“下午,你好呀”,文件内容变为“小马过河下午,你好呀!”,pycharm打印输出“小马过河下午,你好呀!”
4) file_object = open('mcw.txt',mode='a+',encoding='utf-8') file_object.seek(0) file_object.write("我很好") file_object.close() --------------结果: 后面追加内容了。即使光标移到最前面,只要一写,无论光标在哪里都会立即跳到最后然后进行追加内容。试验表明,追加之后光标在最后需要重新seek调整,不然读不到内容。
小点: r** w** a* r+ w+ a+ 使用频率
读取文件内容到内存,在内存中修改,点击保存才会重新将修改的内容写入磁盘 打开的文件.read(字符个数,默认为所有似乎)
3.7、文件读操作:
文件读操作:
设置光标位置,往后读取几个字符
file_object = open(‘mcw.txt’,mode=’r’,encoding=’utf-8′)
1)读取文件的所有内容到内存。
如果文件大于内存,那么内存装不下全部内容。所以如果以后读取一个特别大的文件,那就一点一点的
读
data = file_object.read()
file_object = open('mcw.txt',mode='r',encoding='utf-8') data = file_object.read() print(data) file_object.close() --------------结果: read要有变量接收并打印
2)# 读取文件的所有内容到内存,并按照每一行进行分割到列表中。#可对每行去掉\n,在做操作
# data_list = file_object.readlines()
# print(data_list)
file_object = open('mcw.txt',mode='r',encoding='utf-8') data_list = file_object.readlines() print(data_list) file_object.close() ---------------结果: ['\ufeff我叫小马过河\n', '我来自虚空深处。\n', '我来了,可是地球人说,魔降风云变。']
with open("mcw.txt",mode="r",encoding="utf-8") as f:
content = f.read()
row_list=content.split("\n") #将文件都读出来,然后去掉每行的换行符形成的列表
print(row_list)
--------------------结果:
['\ufeff我叫小马过河', '明天,你好']
3)指定单词读取文件的字符个数,连续读取出来
start=0
whle True:用
date=对象.read(字符个数) #很少
file_object = open('mcw.txt',mode='r',encoding='utf-8') while True: data=file_object.read(2) print(data) -----------结果: 文件内容死循环从里面每次打印两个字符的大小。文件内容循环结束,打印空的内容
4)# 指定读取当前光标所在的位置后的字符个数
# data = file_object.read(4)
file_object = open('mcw.txt',mode='r',encoding='utf-8') data = file_object.read(4) print(data) file_object.close() ----------结果: ”打印出“我叫小”,由于开头有一个特殊字符,所以显示少了一个
5)# 如果以后读取一个特别大的文件 (用的最多)
如果有换行符号\n,也可以用strip去符号
方法一:
for 变量line in 打开的文件:
line=line.strip()
# for line in file_object:
# line = line.strip()
# print(line)
# file_object.close()
file_object = open('mcw.txt',mode='r',encoding='utf-8') for line in file_object: line=line.strip() print(line) file_object.close() ----------------结果: 我叫小马过河 我来自虚空深处。 我来了,可是地球人说,魔降风云变。
或者:
# data_list = file_object.readlines()
# print(data_list)
file_object = open('mcw.txt',mode='r',encoding='utf-8') data_list = file_object.readlines() print(data_list) file_object.close() -----------结果: ['\ufeff我叫小马过河\n', '我来自虚空深处。\n', '我来了,可是地球人说,魔降风云变。'] strip去掉\n的换行符 li=[] file_object = open('mcw.txt',mode='r',encoding='utf-8') data_list = file_object.readlines() for i in data_list: li.append(i.strip()) print(li) file_object.close() -------------------结果: ['\ufeff我叫小马过河', '我来自虚空深处。', '我来了,可是地球人说,魔降风云变。']
3.8、文件写操作:
open(“文件路径”,mode=”w”,encoding=”utf-8″)
写,往后写,换行\n。写完要关闭,写的在内存,当关闭的时候强制刷到硬盘里面
file_object = open(‘mcw.txt’,mode=’w’,encoding=’utf-8′)
file_object.write(‘asdfadsfasdf\n’)
file_object.write(‘asdfasdfasdfsadf’)
file_object.close()
file_object = open('mcw.txt',mode='w',encoding='utf-8') file_object.write('abc\ndef') file_object.close() -----------结果: 覆盖了之前的内容。\n换行符生效,起到换行作用
3.9将多个windows目录下的文件内容统一写到一个文件,并增加文件名字分隔开来
import os from datetime import datetime basedir="D:\BaiduNetdiskDownload\XXX从入门到精通PPT\课本源代码" bb=os.walk(basedir) for a,b,c in bb: for i in c: filep=os.path.join(a,i) li=[] with open(filep,mode="rb") as f: for line in f: li.append(line) with open('mcw.txt', mode="ab") as f: # f.write(("\n----------------------------开始-%s------------------------------\n"%i).encode("gbk")) f.write('\r\n'.encode()) f.write('\r\n'.encode()) f.write('\r\n'.encode()) f.write(("-------开始-%s----收集by小马过河-----"%i).encode("gbk")) f.write('\r\n'.encode()) f.write('\r\n'.encode()) # f.write(('\n--------------------------------------------------------------\n').encode("gbk")) for j in li: f.write(j) f.write('\r\n'.encode()) f.write(("-------结束-%s----收集by魔降风云变-----"%i).encode("gbk")) f.write(datetime.now().strftime("%Y_%m_%d %H:%M:%S").encode('gbk')) f.write('\r\n'.encode()) print(filep)
注意点:
1)rb读取,ab追加。Windows里追加用gbk不会乱码。
2)这里加入\n不换行,加入\r\n才换行
3.10、使用seek定位行内容的案例
# 1.有一个文件,这个文件中有20000行数据,开启一个线程池,为每100行创建一个任务,打印这100行数据。 # import time # from threading import Thread # from concurrent.futures import ThreadPoolExecutor # # # with open('mcw.txt',mode="a",encoding="utf-8") as f : # # for i in range(0,20000): # # f.write("魔降风云变-%s\n"%i) # shang=int(20000/100) # li=[] # with open('mcw.txt',mode="r",encoding="utf-8") as f : # for line in f: # line=line.strip() # li.append(line) # index_li=[] # for i in range(shang): # start_index=i*100 # end_index=(i+1)*100 # index=(start_index,end_index) # index_li.append(index) # def func(li,index): # print("\n".join(li[index[0]:index[1]])) # tp=ThreadPoolExecutor(10) # for i in index_li: # t=Thread(target=func,args=(li,i,)) # t.start() # tp.shutdown() # 方法二: import time from threading import Thread from concurrent.futures import ThreadPoolExecutor # with open('mcw.txt',mode="a",encoding="utf-8") as f : # for i in range(0,20000): # f.write("魔降风云变-%s\n"%i) num_li=[i for i in range(0,20001,100)]#[0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000] cur_li=[] with open('mcw.txt',mode="rb") as f : for i in range(0,20000): #i是0的时候还没读取游标是0,i是第100行(这行还没读取)的时候游标是1990, if i in num_li: cur=[i,f.tell()] cur_li.append(cur) print(f.tell()) data = f.readline()#.strip() # data=f.readlines() # print(data) print(cur_li) #[[0, 0], [100, 1990], [200, 4090], [300, 6190], [400, 8290], [500, 10390], [600, 12490], [1800, 38490], [1900, 40690]] cur_li_new=[ { "第几行到第几行:":"%s到%s行:"%(cur_li[i][0],cur_li[i+1][0]),"seek起始位置:":cur_li[i][1],"read读取字节:":cur_li[i+1][1]-cur_li[i][1]} for i in range(len(cur_li)) if i<len(cur_li)-1] #,cur_li[i+1][1]-cur_li[i][0]-1): cur_li_new.append({ "第几行到第几行:":"%s到%s行:"%(cur_li[-1][0],cur_li[-1][0]+100),"seek起始位置:":cur_li[-1][1],"read读取字节:":None}) print(cur_li_new) def func(i): print("-----------%s开始读取----------------" % i['第几行到第几行:']) f.seek(i['seek起始位置:']) data = f.read(i['read读取字节:']) print(data.decode()) time.sleep(0.1) print("-----------%s已经结束----------------" % i['第几行到第几行:']) start=time.time() with open('mcw.txt',mode="rb") as f : # tp=ThreadPoolExecutor(10) for i in cur_li_new: #单个i元素:{ '第一行到第几行:': '0到100行:', 'seek起始位置:': 0, 'read读取字节:': 1990} { '第一行到第几行:': '100到200行:', 'seek起始位置:': 1990, 'read读取字节:': 2100}, { '第一行到第几行:': '200到300行:', 'seek起始位置:': 4090, 'read读取字节:': 2100}, func(i) # Thread(target=func, args=(i,)).start() # tp.shutdown() print(time.time()-start) # [200, 4090], [300, 6190] seek到4090,read(6190-4090) #1[0, 0],2 [100, 1990],3 [200, 4090],4 [300, 6190] # --------------- #0.0500028133392334 函数执行 #20.00814437866211 线程池执行 #由上可知,实现了线程池效果
seek定位原理:
1)读取第三行,条件一是:需要seek到第三行第一个字节之前,这个字节数为第三行之前的字节总数,即第一第二行的字节总数,条件二是:我需要读取的第三行字节数量
2)我for循环读取行数,每次循环f.tell()获得字节大小,即读到第二行获得第二行之前总的字节数,读完第三行获得第三行及之前的字节数。由此获得了条件一
3)我用前三行的字节数减去前两行的字节数获得条件2
4)readline()读行 tell()获取读取了多少字节 read(字节数) seek(字节数)
注意点:rb读 保持正确的字节数。
3.11、tell()获取第一行字节数,然后从开头read这个字节数获取内容超过一行的问题
with open('mcw.txt',mode="r",encoding="utf-8") as f :
# data = f.readline()
# print(data)
# print(f.tell())
# -----结果:
# 魔降风云变-0
#
# 19
# 要点一(问题): # f.seek(0) # data = f.read(19) # print(data) # print(f.tell()) # -------------------结果: # 魔降风云变-0 # 魔降风云变-1 # 魔降风 # 47 # 试了试两段代码,第一段代码是读取文件第一行得到第一行总共19个字节, # 然后我seek(0),f.read(19) # 往后读取19个字节,预期只读取到第一行 # 结果和预期只打印第一行不同,多打印了47 - 19 = 28 # 个字节,这是什么原因呢? # 是read有问题么?怎么看都不想说只读取了,难道是编码问题 # 解答:编码问题,rb读取就可以了,想打印就数据.decode()
with open('mcw.txt',mode="rb") as f
3.12、f.read(None)
# 要点二: # f.read(None)从当前指针位置读取文件内容到最后
转载于:https://www.cnblogs.com/machangwei-8/p/10655338.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106887.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
