大家好,又见面了,我是你们的朋友全栈君。

排查完全陌生的问题,完全不熟悉的系统组件,是售后工程师的一大工作乐趣,当然也是挑战。今天借这篇文章,跟大家分析一例这样的问题。排查过程中,需要理解一些自己完全陌生的组件,比如systemd和dbus。但是排查问题的思路和方法基本上还是可以复用了,希望对大家有所帮助。
问题一直在发生
I’m NotReady
阿里云有自己的Kubernetes容器集群产品。随着Kubernetes集群出货量的剧增,线上用户零星的发现,集群会非常低概率地出现节点NotReady情况。据我们观察,这个问题差不多每个月,就会有一两个客户遇到。在节点NotReady之后,集群Master没有办法对这个节点做任何控制,比如下发新的Pod,再比如抓取节点上正在运行Pod的实时信息。


需要知道的Kubernetes知识
这里我稍微补充一点Kubernetes集群的基本知识。Kubernetes集群的“硬件基础”,是以单机形态存在的集群节点。这些节点可以是物理机,也可以是虚拟机。集群节点分为Master和Worker节点。Master节点主要用来负载集群管控组件,比如调度器和控制器。而Worker节点主要用来跑业务。Kubelet是跑在各个节点上的代理,它负责与管控组件沟通,并按照管控组件的指示,直接管理Worker节点。
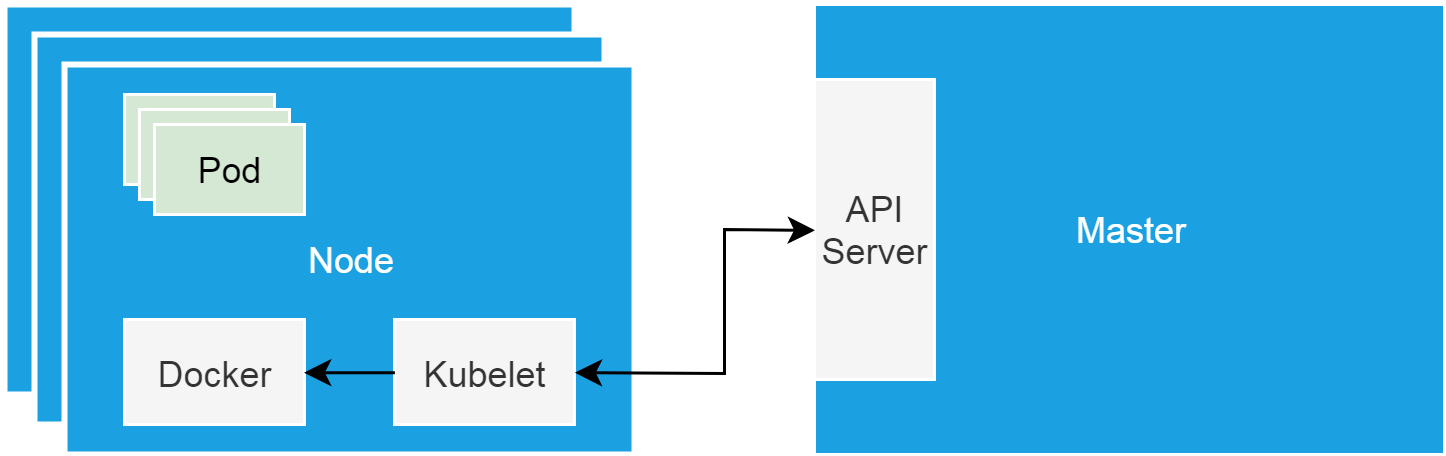
当集群节点进入NotReady状态的时候,我们需要做的第一件事情,肯定是检查运行在节点上的kubelet是否正常。在这个问题出现的时候,使用systemctl命令查看kubelet状态,发现它作为systemd管理的一个daemon,是运行正常的。当我们用journalctl查看kubelet日志的时候,发现下边的错误。

什么是PLEG
这个报错很清楚的告诉我们,容器runtime是不工作的,且PLEG是不健康的。这里容器runtime指的就是docker daemon。Kubelet通过直接操作docker daemon来控制容器的生命周期。而这里的PLEG,指的是pod lifecycle event generator。PLEG是kubelet用来检查容器runtime的健康检查机制。这件事情本来可以由kubelet使用polling的方式来做。但是polling有其成本上的缺陷,所以PLEG应用而生。PLEG尝试以一种“中断”的形式,来实现对容器runtime的健康检查,虽然实际上,它同时用了polling和”中断”两种机制。
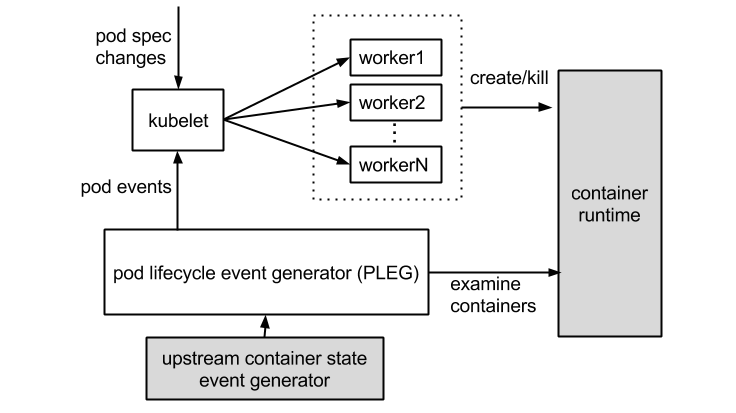
基本上看到上边的报错,我们可以确认,容器runtime出了问题。在有问题的节点上,通过docker命令尝试运行新的容器,命令会没有响应。这说明上边的报错是准确的.
容器runtime
Docker Daemon调用栈分析
Docker作为阿里云Kubernetes集群使用的容器runtime,在1.11之后,被拆分成了多个组件以适应OCI标准。拆分之后,其包括docker daemon,containerd,containerd-shim以及runC。组件containerd负责集群节点上容器的生命周期管理,并向上为docker daemon提供gRPC接口。
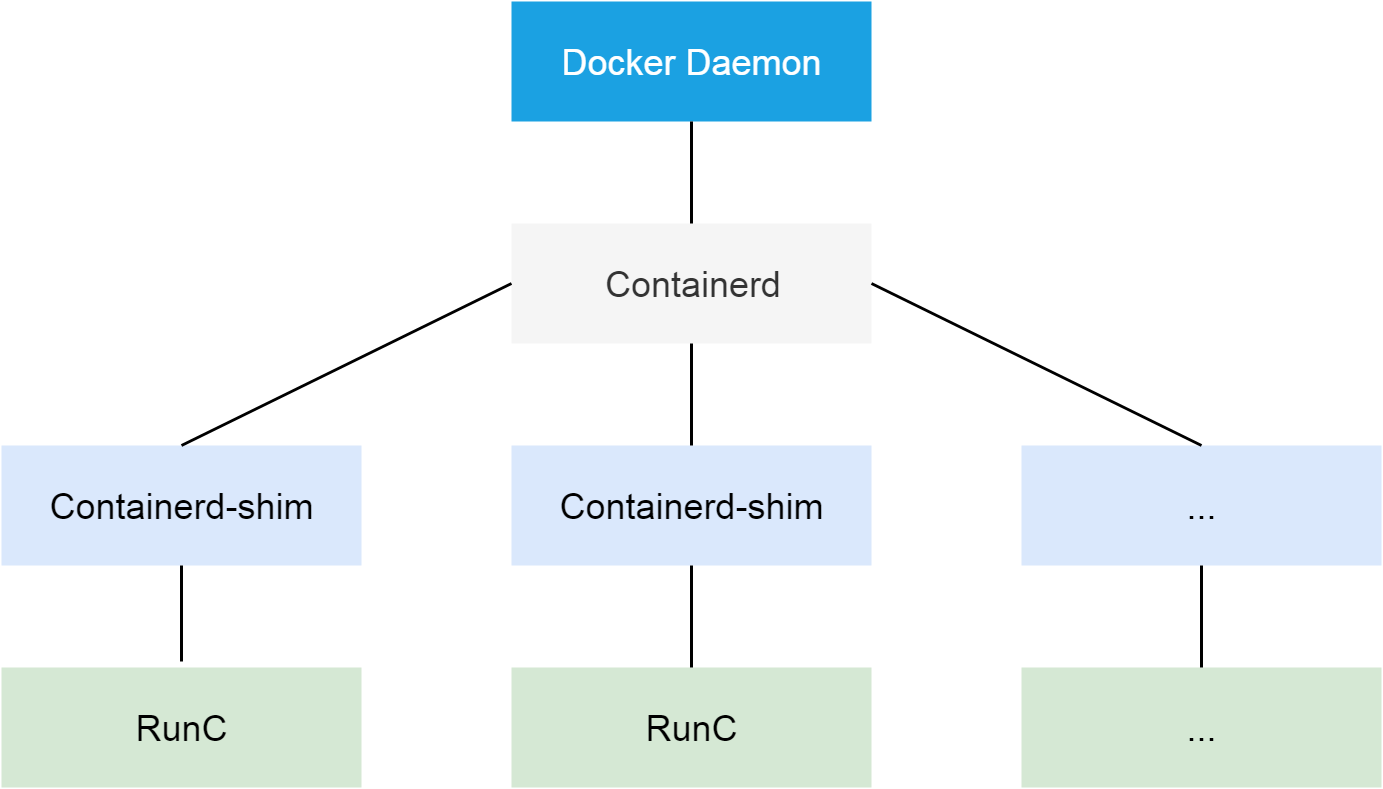
在这个问题中,既然PLEG认为容器运行是出了问题,我们需要先从docker daemon进程看起。我们可以使用kill -USR1 <pid>命令发送USR1信号给docker daemon,而docker daemon收到信号之后,会把其所有线程调用栈输出到文件/var/run/docker文件夹里。
Docker daemon进程的调用栈相对是比较容易分析的。稍微留意,我们会发现大多数的调用栈都类似下图中的样子。通过观察栈上每个函数的名字,以及函数所在的文件(模块)名称,我们可以看到,这个调用栈下半部分,是进程接到http请求,做请求路由的过程;而上半部分则进入实际的处理函数。最终处理函数进入等待状态,等待的是一个mutex实例。
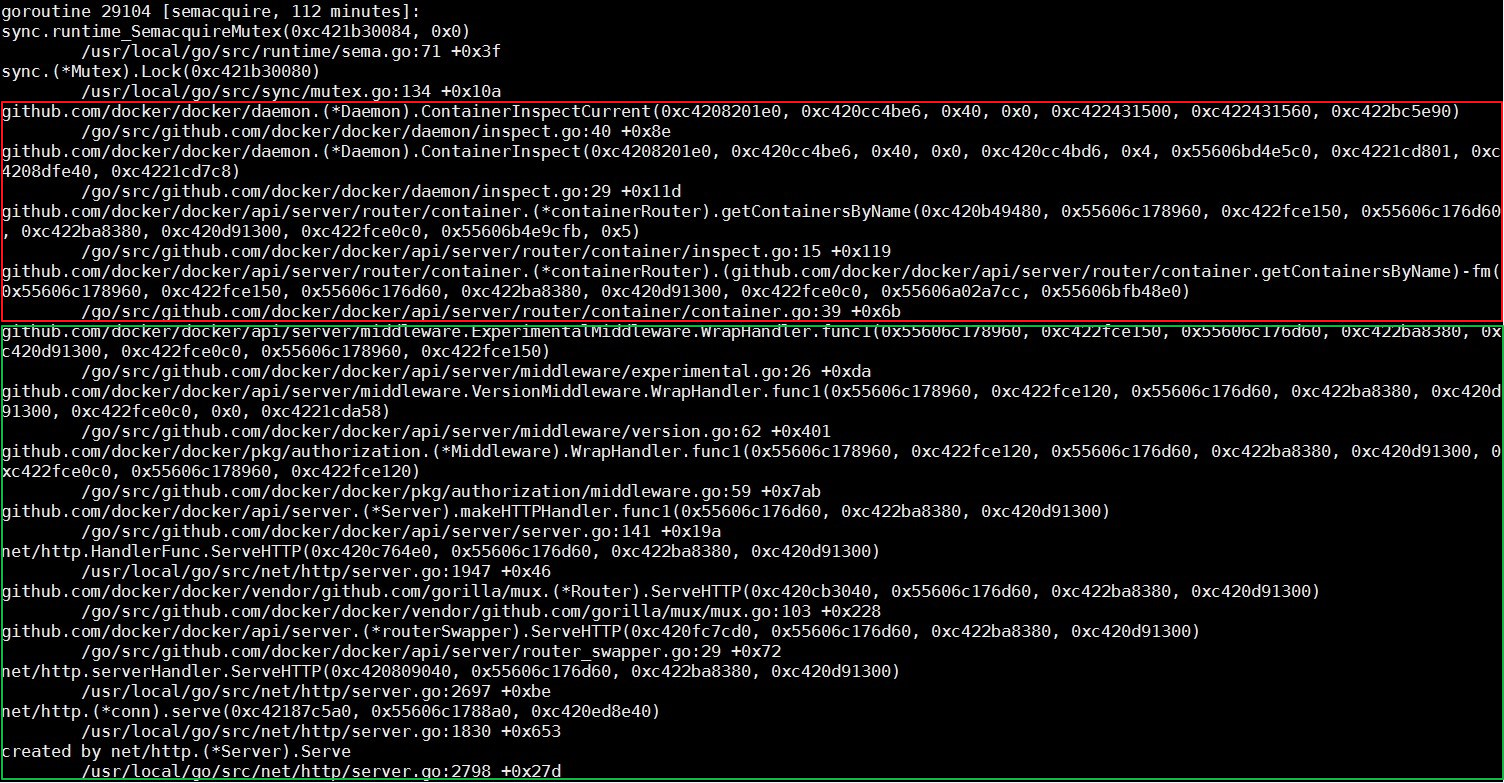
到这里,我们需要稍微看一下ContainerInspectCurrent这个函数的实现,而最重要的是,我们能搞明白,这个函数的第一个参数,就是mutex的指针。使用这个指针搜索整个调用栈文件,我们会找出,所有等在这个mutex上边的线程。同时,我们可以看到下边这个线程。
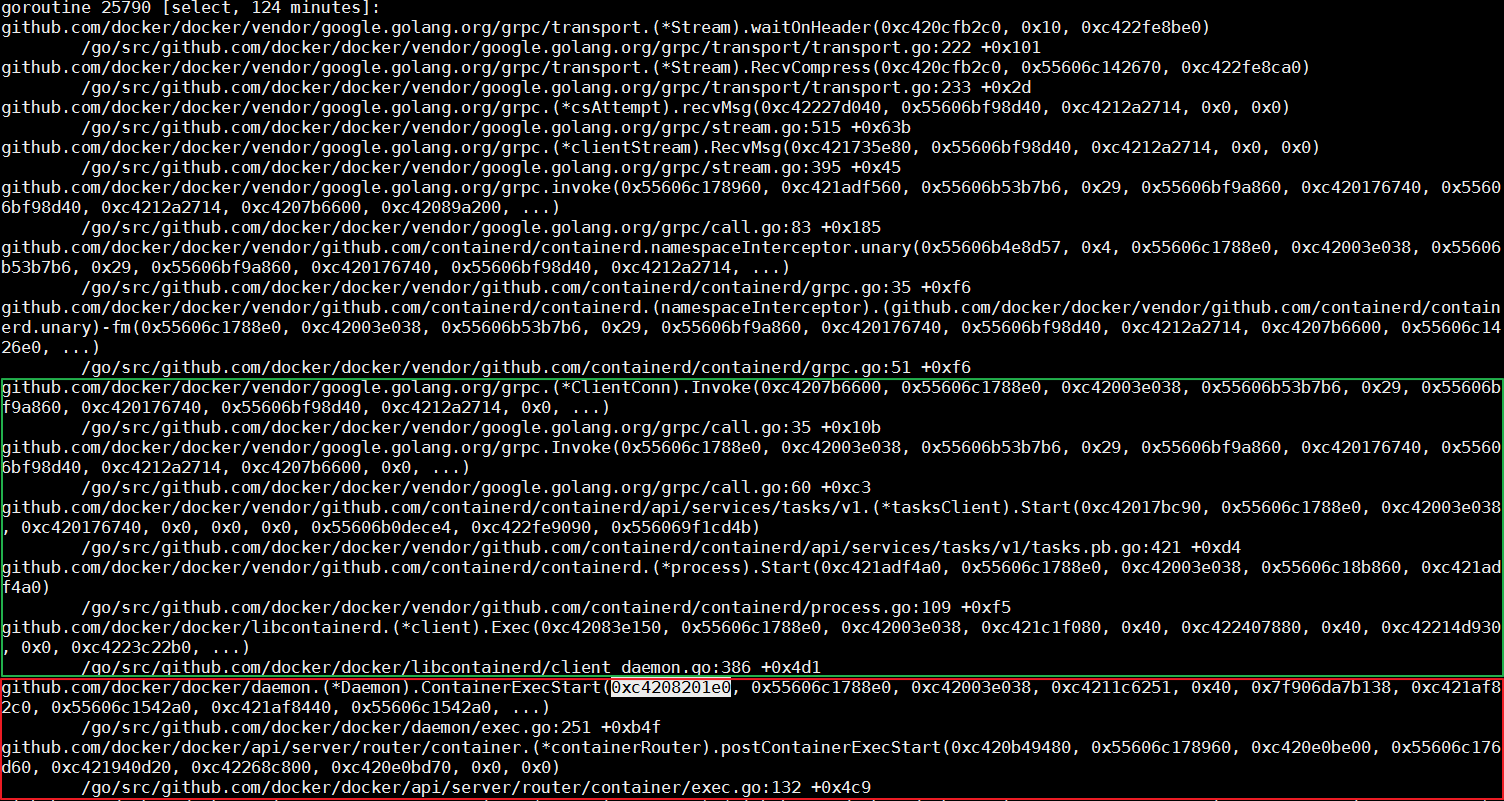
这个线程上,函数ContainerExecStart也是在处理具体请求的时候,收到了这个mutex这个参数。但不同的是,ContainerExecStart并没有在等待mutex,而是已经拿到了mutex的所有权,并把执行逻辑转向了containerd调用。关于这一点,我们可以使用代码来验证。前边我们提到过,containerd向上通过gRPC对docker daemon提供接口。此调用栈上半部分内容,正是docker daemon在通过gRPC请求来呼叫containerd。
Containerd调用栈分析
与输出docker daemon的调用栈类似,我们可以通过kill -SIGUSR1 <pid>命令来输出containerd的调用栈。不同的是,这次调用栈会直接输出到messages日志。
Containerd作为一个gRPC的服务器,它会在接到docker daemon的远程请求之后,新建一个线程去处理这次请求。关于gRPC的细节,我们这里其实不用关注太多。在这次请求的客户端调用栈上,可以看到这次调用的核心函数是Start一个进程。我们在containerd的调用栈里搜索Start,Process以及process.go等字段,很容易发现下边这个线程。
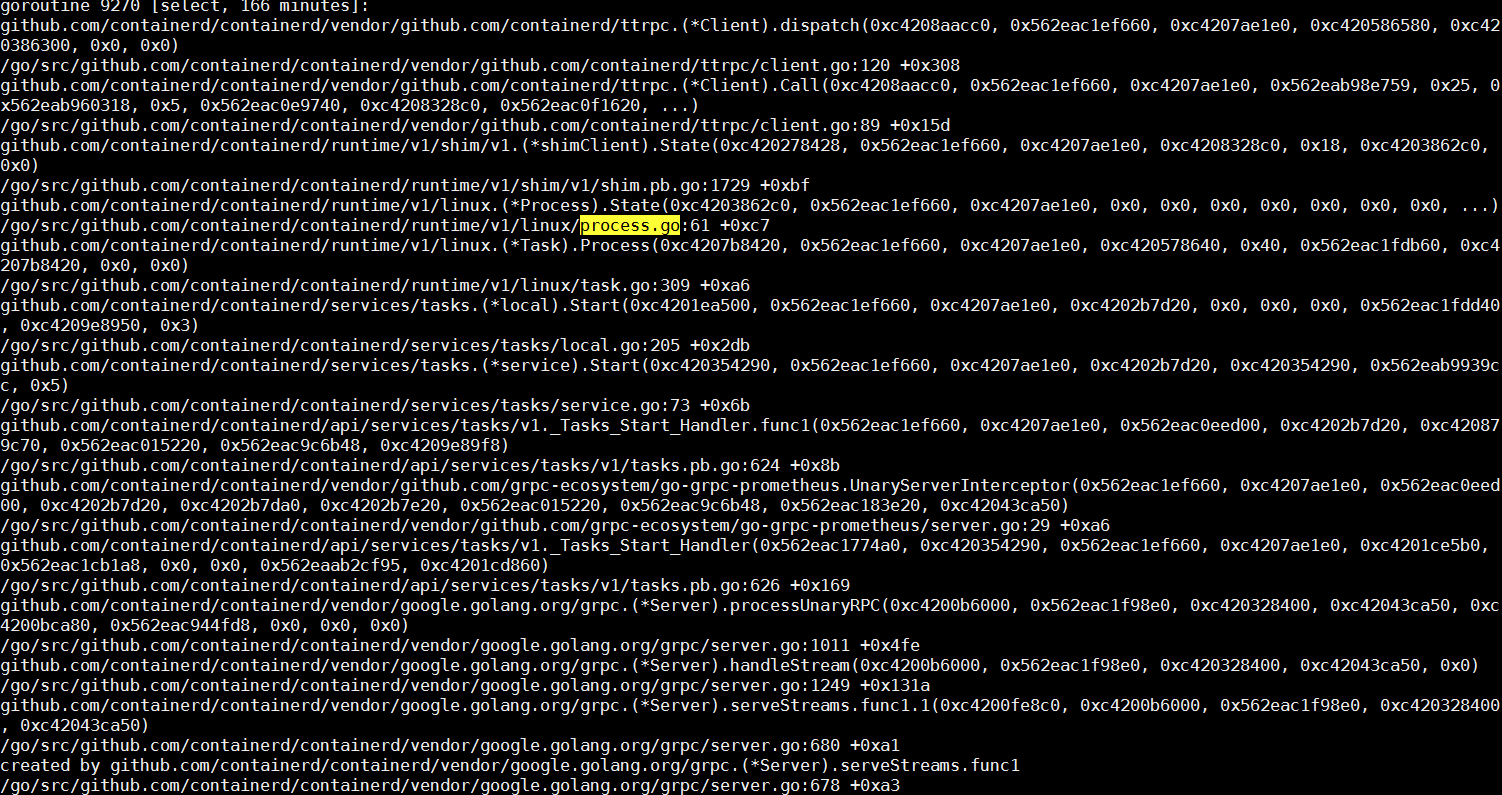
这个线程的核心任务,就是依靠runC去创建容器进程。而在容器启动之后,runC进程会退出。所以下一步,我们自然而然会想到,runC是不是有顺利完成自己的任务。查看进程列表,我们会发现,系统中有个别runC进程,还在执行,这不是预期内的行为。容器的启动,跟进程的启动,耗时应该是差不对的,系统里有正在运行的runC进程,则说明runC不能正常启动容器。
什么是Dbus
RunC请求Dbus
容器runtime的runC命令,是libcontainer的一个简单的封装。这个工具可以用来管理单个容器,比如容器创建,或者容器删除。在上节的最后,我们发现runC不能完成创建容器的任务。我们可以把对应的进程杀掉,然后在命令行用同样的命令尝试启动容器,同时用strace追踪整个过程。
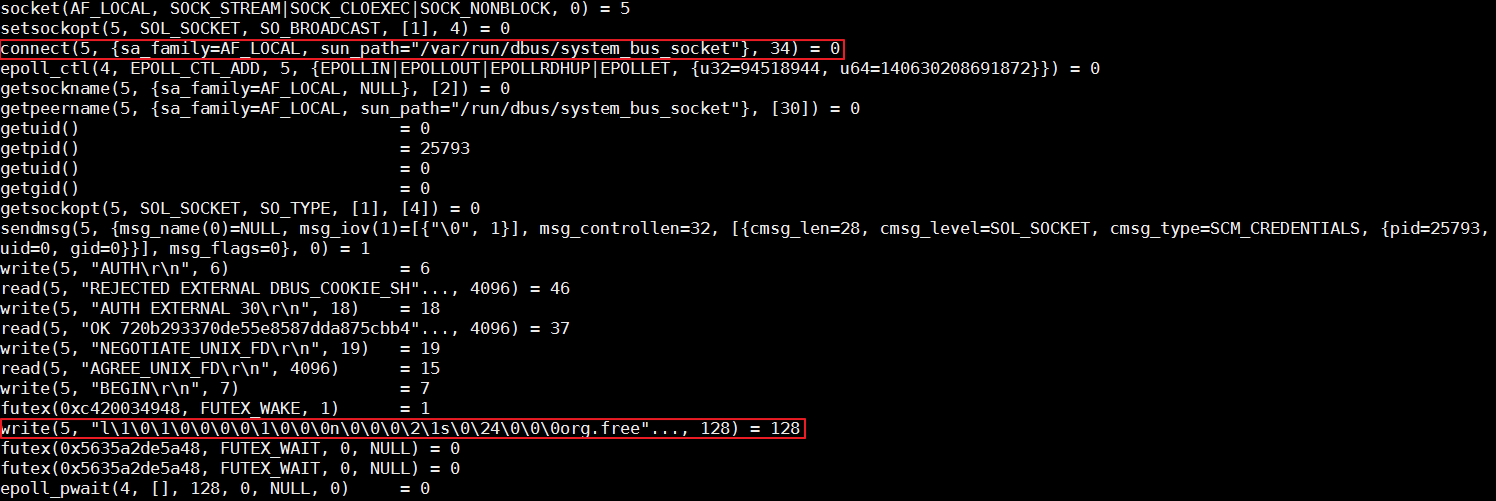
分析发现,runC停在了向带有org.free字段的dbus写数据的地方。那什么是dbus呢?在Linux上,dbus是一种进程间进行消息通信的机制。
原因并不在Dbus
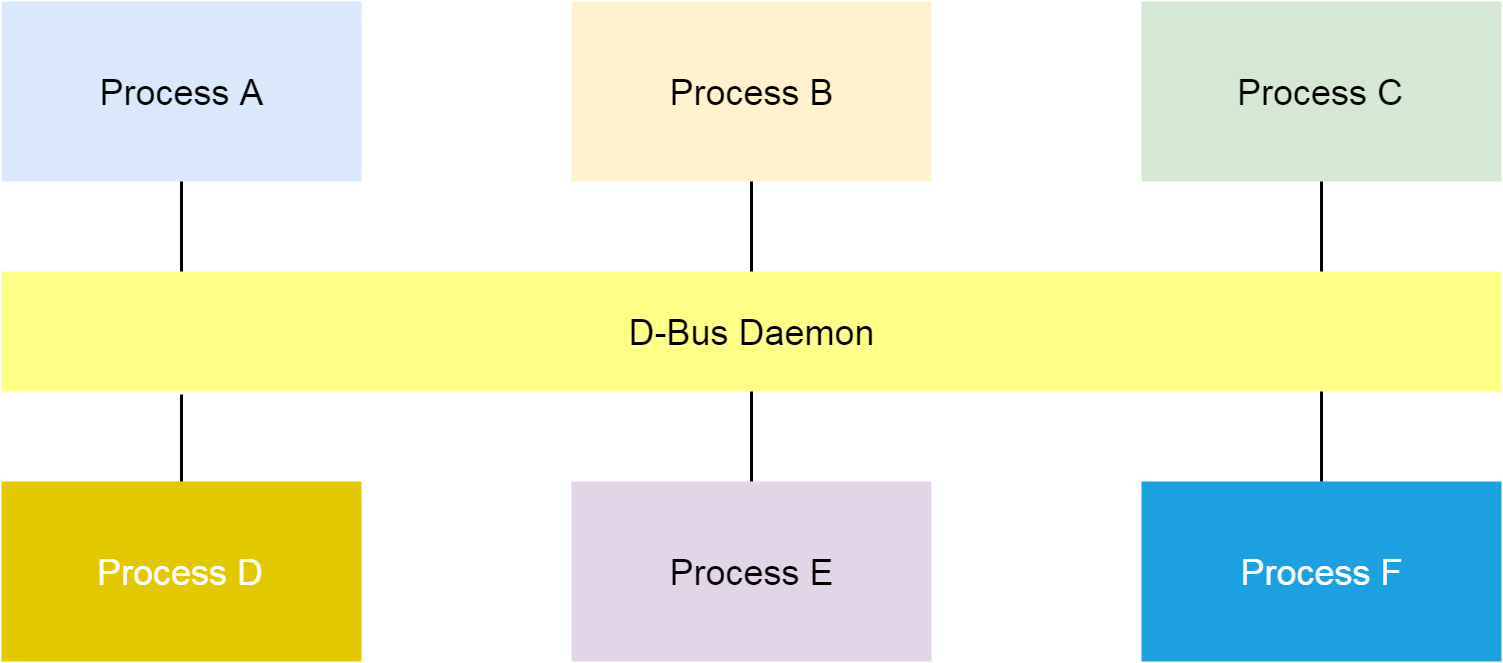
我们可以使用busctl命令列出系统现有的所有bus。如下图,在问题发生的时候,我看到客户集群节点Name的编号非常大。所以我倾向于认为,dbus某些相关的数据结构,比如Name,耗尽了引起了这个问题。
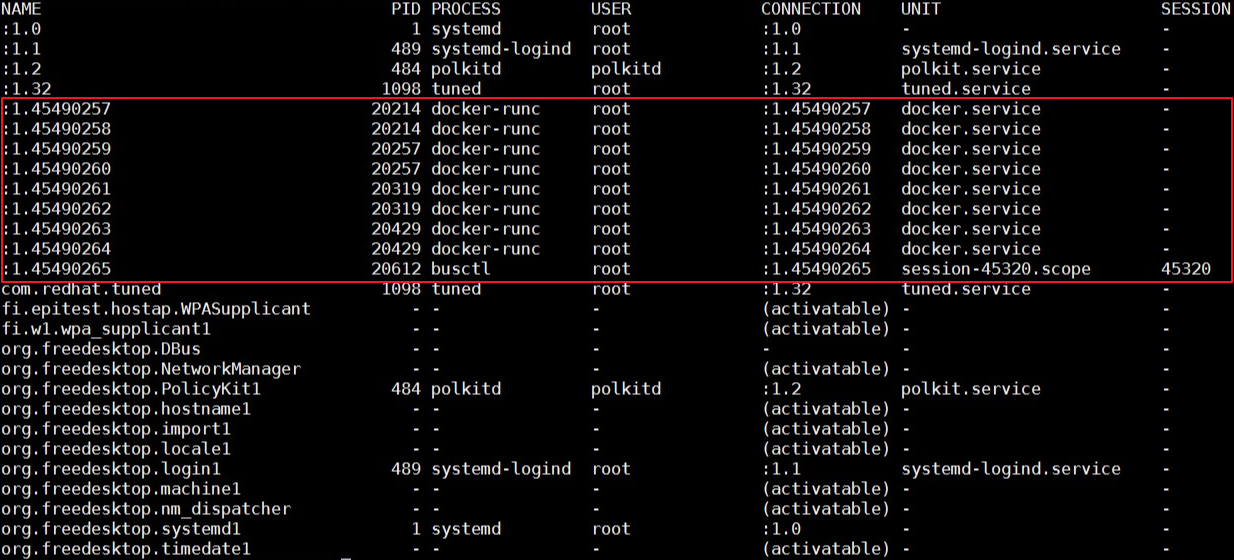
Dbus机制的实现,依赖于一个组件叫做dbus-daemon。如果真的是dbus相关数据结构耗尽,那么重启这个daemon,应该是可以解决这个问题。但不幸的是,问题并没有这么直接。重启dbus-daemon之后,问题依然存在。
在上边用strace追踪runC的截图中,我提到了,runC卡在向带有org.free字段的bus写数据的地方。在busctl输出的bus列表里,显然带有这个字段的bus,都在被systemd使用。这时,我们用systemctl daemon-reexec来重启systemd,问题消失了。所以基本上我们可以判断一个方向:问题可能跟systemd有关系。
Systemd是硬骨头
Systemd是相当复杂的一个组件,尤其对没有做过相关开发工作的同学来说,比如我自己。基本上,排查systemd的问题,我用到了四个方法,(调试级别)日志,core dump,代码分析,以及live debugging。其中第一个,第三个和第四个结合起来使用,让我在经过几天的鏖战之后,找到了问题的原因。但是这里我们先从“没用”的core dump说起。
没用的Core Dump
因为重启systemd解决了问题,而这个问题本身,是runC在使用dbus和systemd通信的时候没有了响应,所以我们需要验证的第一件事情,就是systemd不是有关键线程被锁住了。查看core dump里所有线程,只有以下一个线程,此线程并没有被锁住,它在等待dbus事件,以便做出响应。

零散的信息
因为无计可施,所以只能做各种测试、尝试。使用busctl tree命令,可以输出所有bus上对外暴露的接口。从输出结果看来,org.freedesktop.systemd1这个bus是不能响应接口查询请求的。
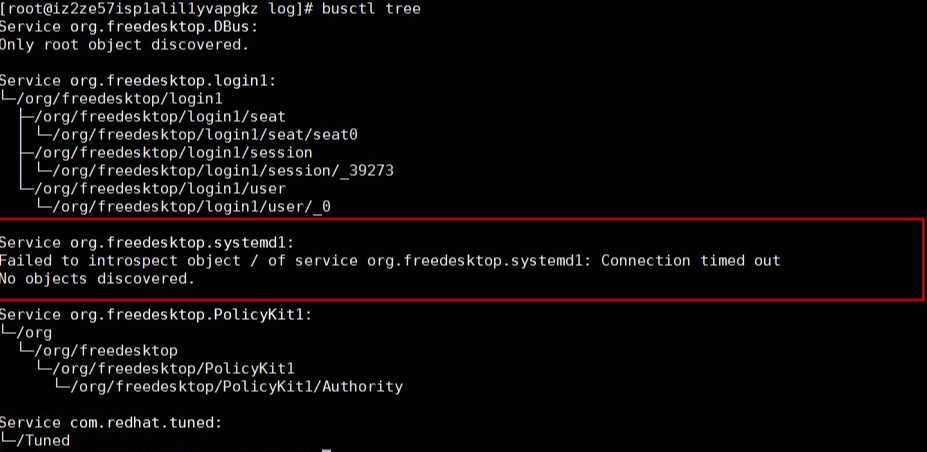
使用下边的命令,观察org.freedesktop.systemd1上接受到的所以请求,可以看到,在正常系统里,有大量Unit创建删除的消息,但是有问题的系统里,这个bus上完全没有任何消息。
gdbus monitor –system –dest org.freedesktop.systemd1 –object-path /org/freedesktop/systemd1
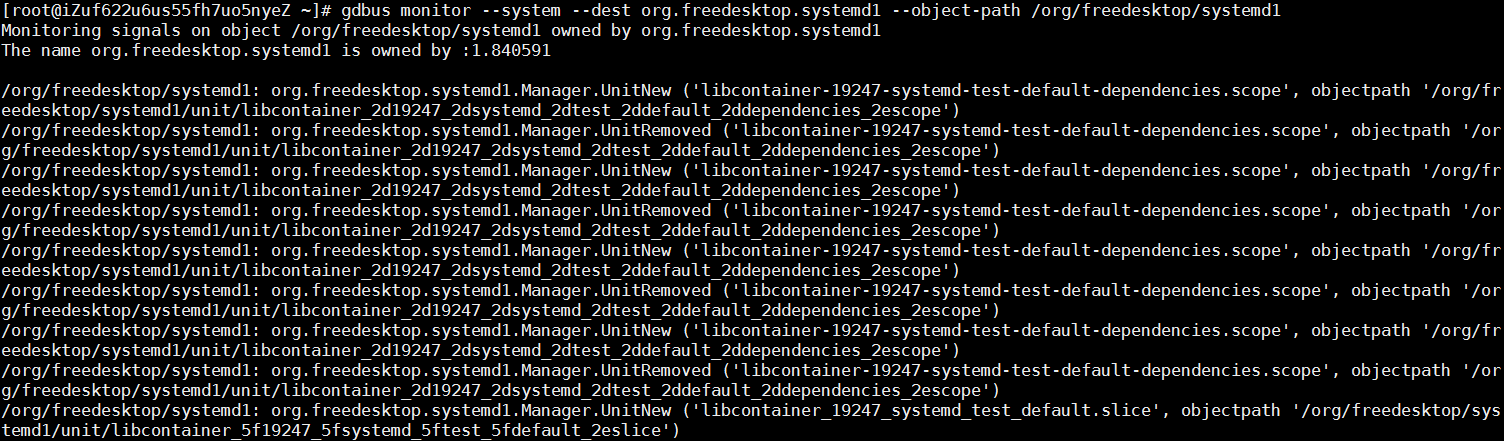
分析问题发生前后的系统日志,runC在重复的跑一个libcontainer_%d_systemd_test_default.slice测试,这个测试非常频繁,但是当问题发生的时候,这个测试就停止了。所以直觉告诉我,这个问题,可能和这个测试,有很大的关系。
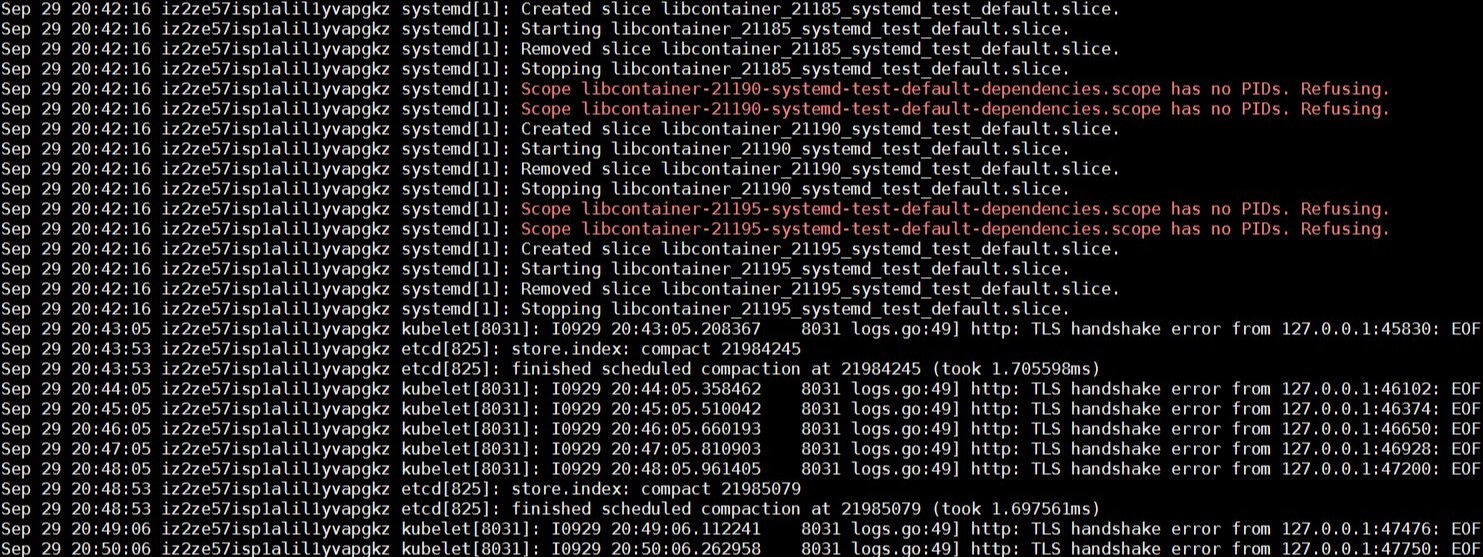
另外,我使用systemd-analyze命令,打开了systemd的调试日志,发现systemd有Operation not supported的报错。
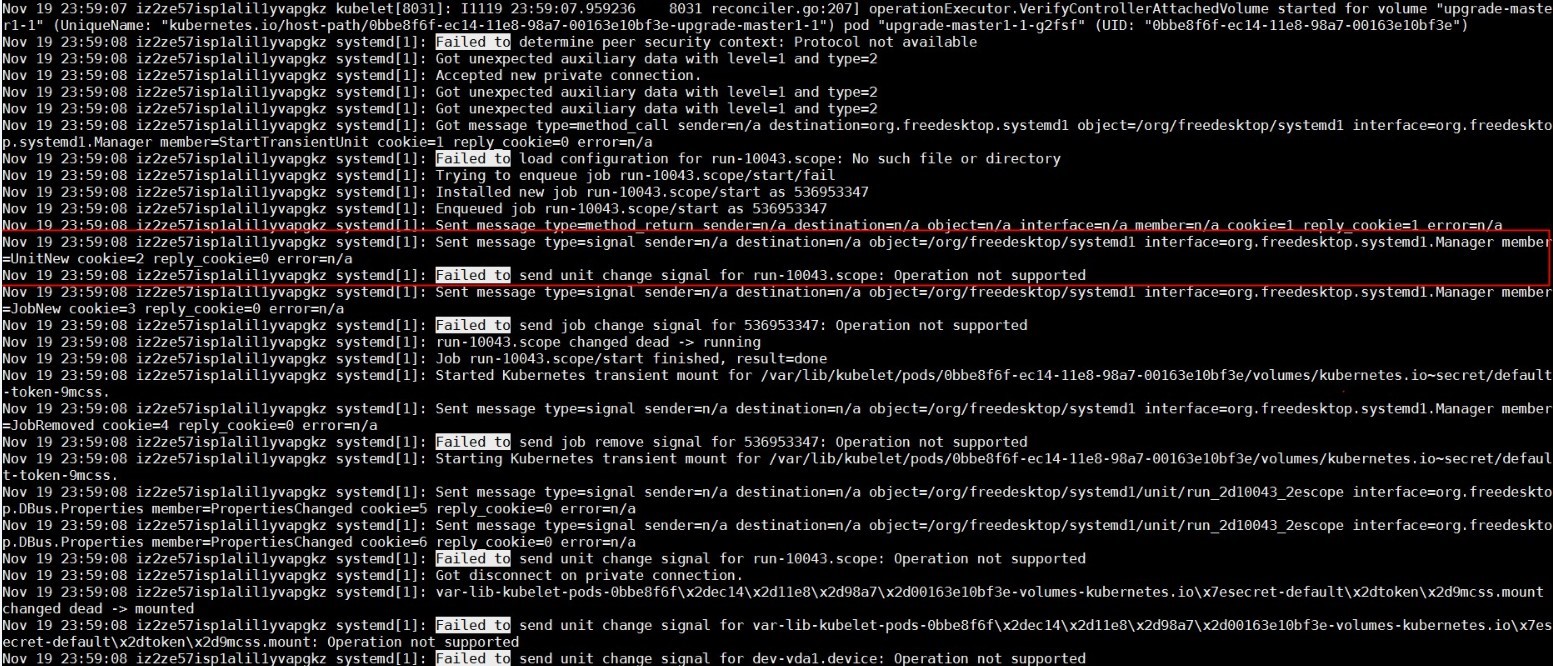
根据以上零散的知识,只能做出一个大概的结论:org.freedesktop.systemd1这个bus在经过大量Unit创建删除之后,没有了响应。而这些频繁的Unit创建删除测试,是runC某一个checkin改写了UseSystemd这个函数,而这个函数被用来测试,systemd的某些功能是否可用。UseSystemd这个函数在很多地方被调用,比如创建容器,或者查看容器性能等操作。
代码分析
这个问题在线上所有Kubernetes集群中,发生的频率大概是一个月两例。问题一直在发生,且只能在问题发生之后,通过重启systemd来处理,这风险极大。
我们分别给systemd和runC社区提交了bug,但是一个很现实的问题是,他们并没有像阿里云这样的线上环境,他们重现这个问题的概率几乎是零,所以这个问题没有办法指望社区来解决。硬骨头还得我们自己啃。
在上一节最后,我们看到了,问题出现的时候,systemd会输出一些Operation not supported报错。这个报错看起来和问题本身风马牛不相及,但是直觉告诉我,这,或许是离问题最近的一个地方,所以我决定,先搞清楚这个报错因何而来。
Systemd代码量比较大,而报这个错误的地方也比较多。通过大量的代码分析(这里略去一千字),我发现有几处比较可疑地方,有了这些可疑的地方,接下来需要做的事情,就是等待。在等待了三周以后,终于有线上集群,再次重现了这个问题。
Live Debugging
在征求客户同意之后,下载systemd调试符号,挂载gdb到systemd上,在可疑的函数下断点,continue继续执行。经过多次验证,发现systemd最终踩到了sd_bus_message_seal这个函数里的EOPNOTSUPP报错。
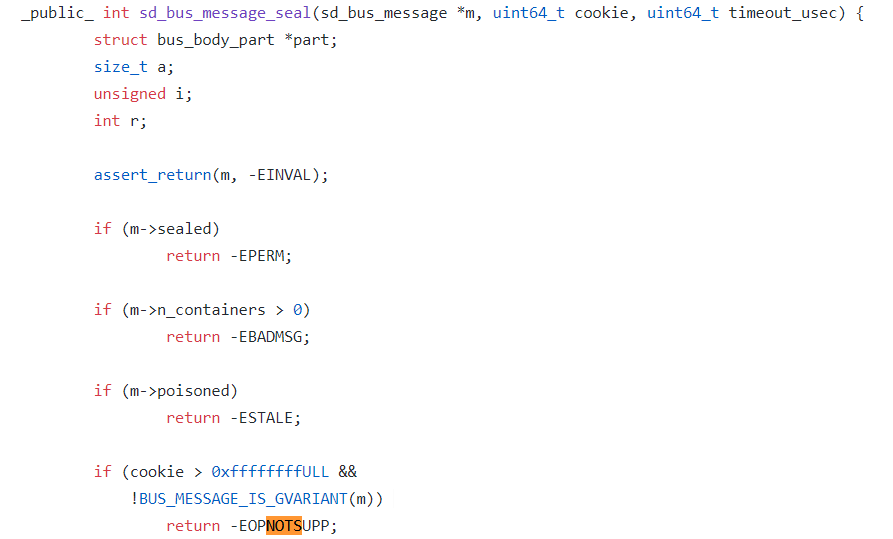
这个报错背后的道理是,systemd使用了一个变量cookie,来追踪自己处理的所有dbus message。每次在在加封一个新的消息的时候,systemd都会先把cookie这个值加一,然后再把这个cookie值复制给这个新的message。
我们使用gdb打印出dbus->cookie这个值,可以很清楚看到,这个值超过了0xffffffff。所以看起来,这个问题是systemd在加封过大量message之后,cookie这个值32位溢出,新的消息不能被加封导致的。

另外,在一个正常的系统上,使用gdb把bus->cookie这个值改到接近0xffffffff,然后观察到,问题在cookie溢出的时候立刻出现,则证明了我们的结论。
怎么判断集群节点NotReady是这个问题导致的
首先我们需要在有问题的节点上安装gdb和systemd debuginfo,然后用命令gdb /usr/lib/systemd/systemd 1把gdb attach到systemd,在函数sd_bus_send设置断点,然后继续执行。等systemd踩到断点之后,用p /x bus->cookie查看对应的cookie值,如果此值超过了0xffffffff,那么cookie就溢出了,则必然导致节点NotReady的问题。确认完之后,可以使用quit来detach调试器。
问题修复
这个问题的修复,并没有那么直截了当。原因之一,是systemd使用了同一个cookie变量,来兼容dbus1和dbus2。对于dbus1来说,cookie是32位的,这个值在经过systemd三五个月频繁创建删除Unit之后,是肯定会溢出的;而dbus2的cookie是64位的,可能到了时间的尽头,它也不会溢出。
另外一个原因是,我们并不能简单的让cookie折返,来解决溢出问题。因为这有可能导致systemd使用同一个cookie来加封不同的消息,这样的结果将是灾难性的。
最终的修复方法是,使用32位cookie来同样处理dbus1和dbus2两种情形。同时在cookie达到0xfffffff的之后下一个cookie返回0x80000000,用最高位来标记cookie已经处于溢出状态。检查到cookie处于这种状态时,我们需要检查是否下一个cookie正在被其他message使用,来避免cookie冲突。
后记
这个问题根本原因肯定在systemd,但是runC的函数UseSystemd使用不那么美丽的方法,去测试systemd的功能,而这个函数在整个容器生命周期管理过程中,被频繁的触发,让这个低概率问题的发生成为了可能。systemd的修复已经被红帽接受,预期不久的将来,我们可以通过升级systemd,从根本上解决这个问题。
https://github.com/lnykryn/systemd-rhel/pull/322
作者:shengdong
原文链接
本文为云栖社区原创内容,未经允许不得转载。
转载于:https://my.oschina.net/yunqi/blog/3041189
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106863.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
