大家好,又见面了,我是你们的朋友全栈君。

基础及相关概念
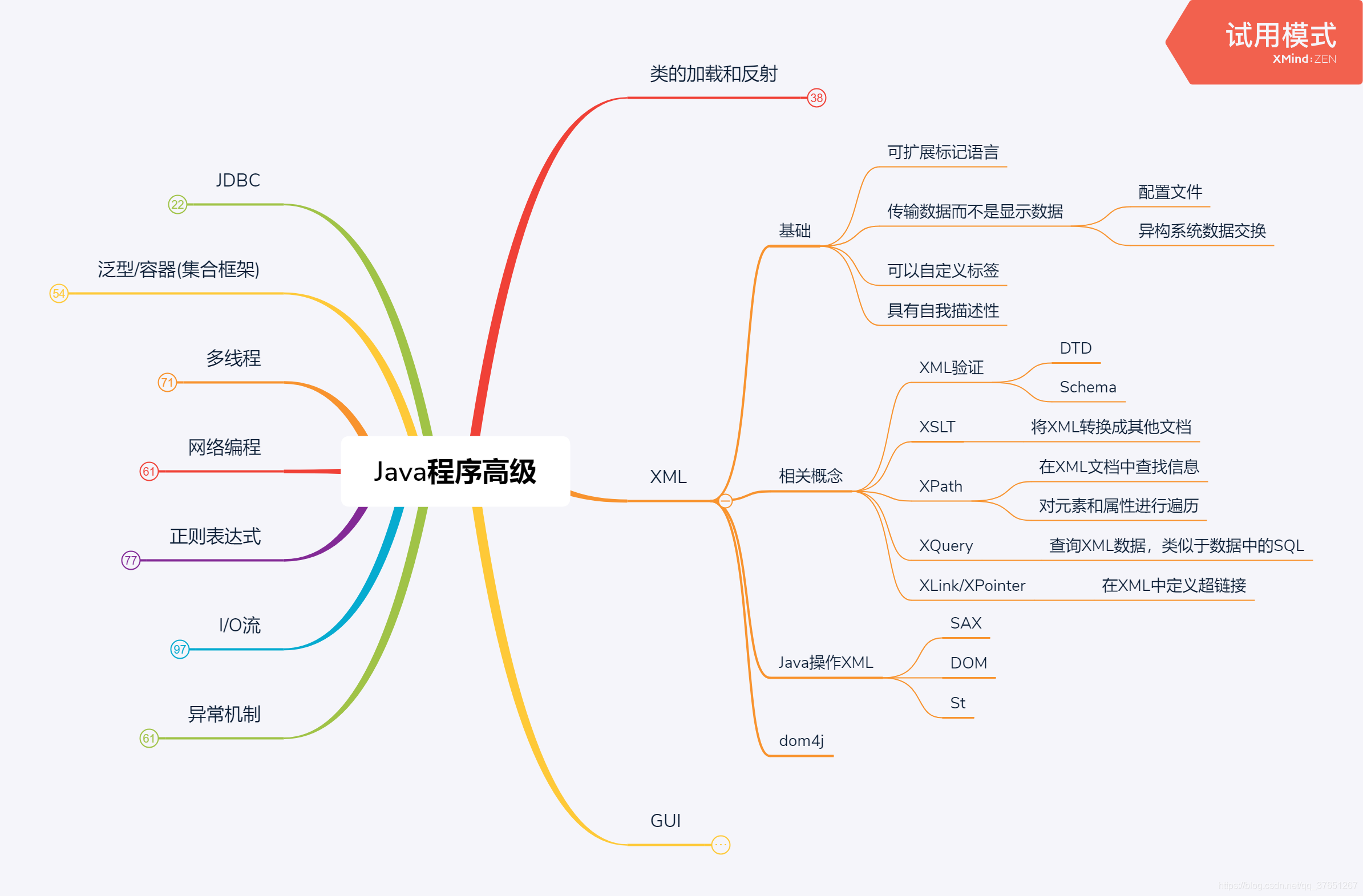
XML(EXtensible Markup Language),可扩展标记语言。
- 特点:
- XML与操作系统、编程语言的开发平台都无关【通用的数据交换格式】
- 实现不同系统之间的数据交换【包括系统的配置文件】
- 是一种标记语言,没有固定的标记,可以随便发明也可以自己创建【整个XML是一种树形文件】
- 是其他技术的基础技术
- 作用:
- 数据交互
- 配置应用程序和网站
- Ajax基石
XML文档结构:
<?xml version="1.0" encoding="UTF-8"?> 【声明部分(位于第一行);这个是满足xml 1.0标准的】
【底下的都是:文档元素描述信息(文档结构),所有带尖括号的都叫标签,也叫元素,都是用树形文件写出来的】
<books> 【根元素,每个XML文件的根元素有且仅有一个】
<!--图书信息 --> 【XML中的注释语法:<!--……-->】
<book id="bk101"> 【books的子元素,包含关系的元素要用缩进来体现】
<author>王珊</author> 【book的子元素】
<title>.NET高级编程</title> 【就像以前的类和属性】
<description>包含C#框架和网络编程等</description>
</book>
<book id="bk102"> 【books的子元素】
<author>李明明</author>
<title>XML基础编程</title>
<description>包含XML基础概念和基本作用</description>
</book>
</books> 【根元素</……>是结束的符号】
【数据库,Java文件,XML文档应当全部一致】
XML文档内容由一系列标签元素组成
<元素名 属性名=“属性值”>元素内容</元素名>
空元素的方法:
<name>(这里是一个空格)</name>
<name></name>
<name/>
- 语法:
属性值用双引号包裹
一个元素可以有多个属性
属性值中不能直接包含<、“、&(不建议:‘、>)【最好都不要写】
例如:
<?xml version="1.0" encoding="UTF-8"?>
<students>
<!-- 学生信息 -->
<student id="s1">
<name>张三</name>
<age>18</age>
</student>
<student id="s2">
<name>李四</name>
<age>22</age>
</student>
<!-- 这两种写法都可以,但是第一种用的居多 -->
<student id="s1"name="张三"age="18"/>
<student id="s2"name="李四"age="22"/>
</students>
-
XML编写注意事项:
所有XML元素都必须有结束标签(</……>)
XML标签对大小写敏感
XML必须正确的嵌套
同级标签以缩进对齐
元素名称可以包含字母、数字或其他的字符
元素名称不能以数字或者标点符号开始(<5name>是错误的;是正确的)
元素名称中不能含空格(是错误的;是正确的的) -
XML编写命名习惯:
编写的元素名称要有描述性。
名字尽量简短些,可以用下划线“_”,但是不要用中横线“-”、点“.”或者冒号“:”(<book_title>)。
数据库怎么命名,XML文件就怎么命名,要保持一致。 -
XML中的转义符列表:
| 符号 | 转义符(预定义实体) |
|---|---|
| < | & lt; |
| > | & gt; |
| “ | & quot; |
| ’ | & apos; |
| & | & amp; |
java操作XML
案例:查
books.xml代码:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book 类型="children">
<title 属性="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book 类型="cooking">
<title 属性="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book 类型="web">
<title 属性="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
<book 类型="web">
<title 属性="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
</bookstore>
java代码:
package xmlDomDome;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomDemo {
public static void main(String[] args) {
// 1.创建一个解析工厂
DocumentBuilderFactory df = DocumentBuilderFactory.newInstance();
// 2.由工厂创建具体的解析器
try {
// 得到一个解析器
DocumentBuilder db = df.newDocumentBuilder();
// 获取要解析的文件
Document document = db.parse(new File("conf/books.xml"));
// 获取根节点
NodeList list = document.getElementsByTagName("bookstore");
Element e = (Element) list.item(0);
NodeList list1 = e.getElementsByTagName("book");
// 3.开始解析
System.out.println("book节点的数量:" + list1.getLength());
System.out.println("--------------------------");
for (int i = 0; i < list1.getLength(); i++) {
Element e1 = (Element) list1.item(i);
// 以下是获取属性节点
NamedNodeMap map = e1.getAttributes();
for (int j = 0; j < map.getLength(); j++) {
Node n1 = map.item(j);
System.out.println(n1.getNodeName() + ":" + n1.getNodeValue());
}
// 获取子节点
NodeList titleList = e1.getElementsByTagName("title");
Element titleElement = (Element) titleList.item(0);
NamedNodeMap titleMap = titleElement.getAttributes();
for (int j = 0; j < titleMap.getLength(); j++) {
Node titleNode = titleMap.item(j);
System.out.println(titleNode.getNodeName() + ":" + titleNode.getNodeValue() + " title:"
+ titleElement.getFirstChild().getNodeValue());
}
NodeList authorList = e1.getElementsByTagName("author");
for (int j = 0; j < authorList.getLength(); j++) {
Element authorElement = (Element) authorList.item(j);
System.out.println("author:" + authorElement.getFirstChild().getNodeValue());
}
NodeList yearList = e1.getElementsByTagName("year");
for (int j = 0; j < yearList.getLength(); j++) {
Element yearElement = (Element) yearList.item(j);
System.out.println("year:" + yearElement.getFirstChild().getNodeValue());
}
NodeList priceList = e1.getElementsByTagName("price");
for (int j = 0; j < priceList.getLength(); j++) {
Element priceElement = (Element) priceList.item(j);
System.out.println("price:" + priceElement.getFirstChild().getNodeValue());
}
System.out.println("------------------------------");
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
控制台输出:
book节点的数量:4
--------------------------
类型:children
属性:en title:Harry Potter
author:J K. Rowling
year:2005
price:29.99
------------------------------
类型:cooking
属性:en title:Everyday Italian
author:Giada De Laurentiis
year:2005
price:30.00
------------------------------
类型:web
属性:en title:Learning XML
author:Erik T. Ray
year:2003
price:39.95
------------------------------
类型:web
属性:en title:XQuery Kick Start
author:James McGovern
author:Per Bothner
author:Kurt Cagle
author:James Linn
author:Vaidyanathan Nagarajan
year:2003
price:49.99
------------------------------
增删改详见dom4j的介绍
dom4j
DOM4J:
开源,易用,应用于Java平台上的一种解析XML的技术,提供第三方的jar包使用了大量的接口。
其中:
Document:定义XML文档(和DOM一样)
Element:定义XML元素
Text:定义XML文本节点
Attribute:定义了XML 的属性
第一步:拖进来jar包选择build path之后add build path。
l例如:初始化信息
public Document parse(String url) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(url);
return document;
解析文件:
try {
parse("animals.xml");
} catch (DocumentException e) {
System.out.println("文件找不到");
}
对文件的操作:
//先得到根节点
Element root=doc.getRootElement();
//遍历根元素的所有子节点
Iterator it= root.elementIterator();
while(it.hasNext()){
//得到每个user的所有子节点
Element user=(Element)it.next();
//其他操作
String XXX=user.getText();//得到子节点的文本
String XXX=user.attributeValue("id");//得到子节点的属性
user.addElement("name").addText(name);//给子节点添加文本
user.addAttribute("id", id);//添加属性
root.remove(user);//删除节点
}
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106685.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
