大家好,又见面了,我是你们的朋友全栈君。
学过简单的wordcount后就开始使用hive吧
这里先介绍下,怎么设置hadoop的环境变量
提示:始终记得我们是ubuntu操作系统。
这里由于小编的这里在安装hive时,由于出现了启动hive时出现了和hadoop的版本不一致的原因,并且始终没有解决,所以就改变策略使用cdh版本的hadoop和hive.因为cdh版本的比较系统,兼容性好。因此要重新安装了。
下载地址如下:http://archive.cloudera.com/cdh5/cdh/5/
安装前先卸载之前的hadoop.这里卸载也很暴力,直接删掉之前的hadoop的安装目录。然后把下载好的cdh版本的hadoop,安装之前的方式,解压,修改解压后的文件夹目录名为hadoop。修改hadoop/etc/hadoop目录下的四个文件,分别是hadoop-env.sh;core-site.xml;hdfs-site.xml;mapred-site.xml
其中hadoop-env.sh是配置java的安装目录,其余的三个分别如上篇博文配置即可。这里不再详述。最后还有就是设置环境变量,如下。
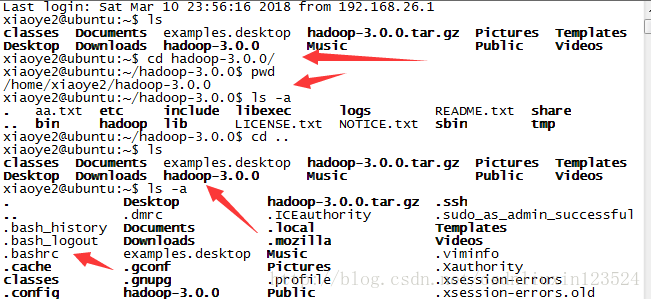
1,设置hadoop环境变量
当前用户目录下:ls -a
会有个.bashrc的隐藏文件,
vim .bashrc
在文件末尾加入hadoop的安装目录,一级bin和sbin的路径
如下:
export HADOOP_HOME=/home/xiaoye2/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
整体截图如下:


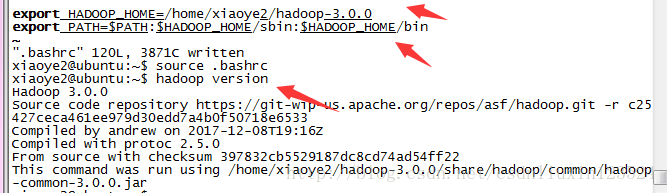
改好之后 执行命令:source ./bashrc
然后
hadoop -version 命令会出现hadoop的版本等信息
2,hive的安装使用
2.1下载安装hive
下载地址,同hadoop一样,也是cdh的。http://archive.cloudera.com/cdh5/cdh/5/
小编下载的是: hive-0.13.1-cdh5.2.0.tar.gz
上传到linux,小编同意下载到Downloads目录下:
tar -zxvf hive-0.13.1-cdh5.2.0.tar.gz ../
mv hive-0.31.1 hive 修改目录名字
给hive设置元数据库,这里我也是使用mysql。所以首先安装mysql数据库吧。这里就不介绍了
然后进入到conf目录:
文件名如下,如果没有就自行创建:
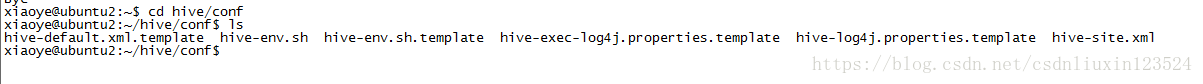
修改hive-site.xml文件,加入一下内容:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ubuntu:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>以下可选配置,该配置信息用来指定 Hive 数据仓库的数据存储在 HDFS 上的目录:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property> 然后,一定要记得加入 MySQL 驱动包(mysql-connector-java-5.1.40-bin.jar)该 jar 包放置在 hive 的lib目录下
2,2如同配置hadoop的环境变量一样,设置hive的环境变量。如下:

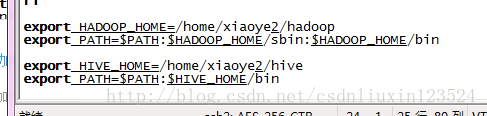
export HIVE_HOME=/home/xiaoye2/hive
export PATH=$PATH:$HIVE_HOME/bin这样就好了,先启动hadoop。
再 hive 直接启动
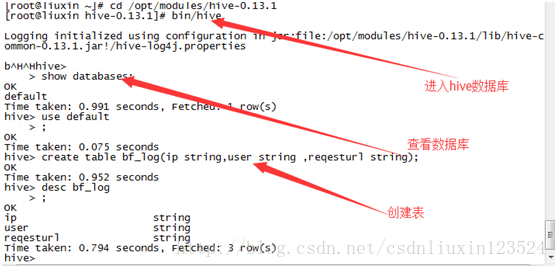
按照上图可建基本的表。
2.3建表
hive> create table student(id int,name string);
OK
Time taken: 0.84 seconds
hive> show tables;
OK
student
Time taken: 0.069 seconds, Fetched: 1 row(s)
hive>
们在关系型数据库中如果想查看有哪些表必须先指定用哪个数据库,但是我们的Hive就不用,它会默认使用default数据库。
hive> show create table student
> ;
FAILED: SemanticException [Error 10001]: Table not found student
hive> create table student(id int,name string);
OK
Time taken: 1.152 seconds
hive> show create table student;
OK
CREATE TABLE `student`(
`id` int,
`name` string)
ROW FORMAT SERDE
‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
STORED AS INPUTFORMAT
‘org.apache.hadoop.mapred.TextInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat’
LOCATION
‘hdfs://localhost:9000/user/hive/warehouse/student’
TBLPROPERTIES (
‘COLUMN_STATS_ACCURATE’=’false’,
‘numFiles’=’1’,
‘numRows’=’-1′,
‘rawDataSize’=’-1′,
‘totalSize’=’27’,
‘transient_lastDdlTime’=’1522143506’)
Time taken: 0.508 seconds, Fetched: 18 row(s)
hive>
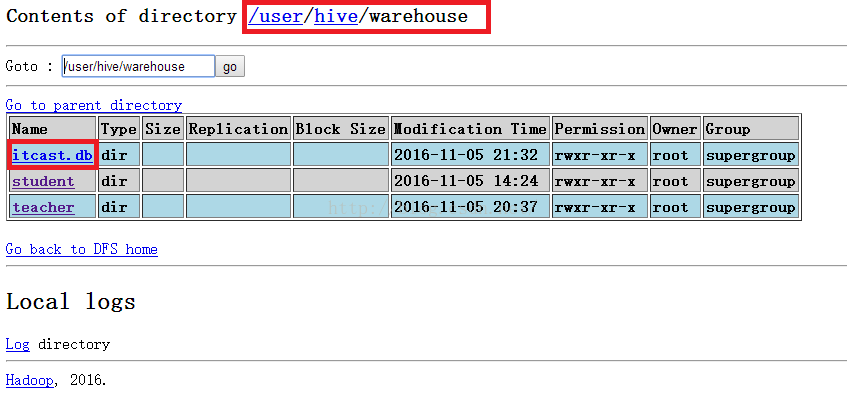
然后可以hdfs上查看我们刚才建的表:
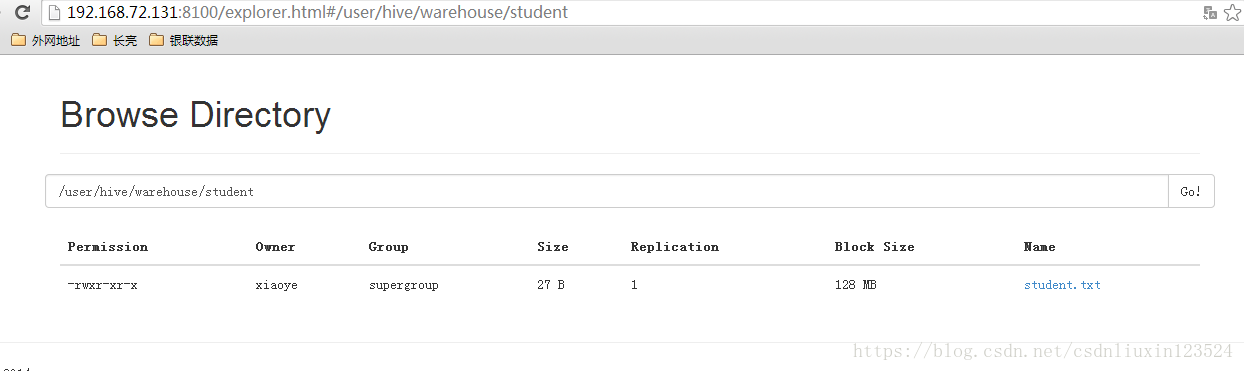
2.4,放入数据到表中
接下来我们便创建一个student.txt文件并在里面添加几条数据,创建student.txt直接使用命令vim student.txt便可以,然后在里面输入三行内容,然后保存退出。
[root@itcast01 ~]# vim student.txt
1 zhangsan
2 lisi
3 wangwu
接着我们把student.txt文件上传到HDFS系统student目录下,如下所示。
hive> load data local inpath ‘/root/student.txt’ into table student;
Copying data from file:/root/student.txt
Copying file: file:/root/student.txt
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]
OK
Time taken: 1.796 seconds
hive>
操作完毕之后我们到HDFS文件系统查看一下,如下图所示,发现已经有student.txt文件并且文件中的内容与我们输入的内容一致。
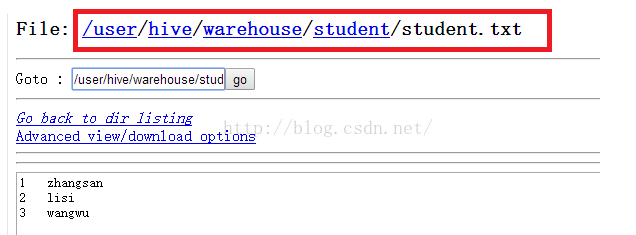
我们从hive视图查询一下student表的内容,如下所示。发现查询出来的内容都是NULL,这是因为我们创建表的时候没有指定列与列之间是以什么分割的。有两列NULL是因为我们创建了两个字段。
hive> select * from student;
OK
NULL NULL
NULL NULL
NULL NULL
Time taken: 1.058 seconds, Fetched: 3 row(s)
hive>
我们不妨来试试查询student表中插入元素的数量,如下所示。我们从执行信息中可以看到Hive自动去调用MapReduce去统计我们的数量了,我们根本就没做什么事情。是不是很神奇呢。最后查询的结果是3,完全正确。
hive> select count(*) from student;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478323409873_0001, Tracking URL = http://itcast03:8088/proxy/application_1478323409873_0001/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478323409873_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-05 14:35:51,757 Stage-1 map = 0%, reduce = 0%
2016-11-05 14:36:01,163 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.66 sec
2016-11-05 14:36:11,584 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.7 sec
MapReduce Total cumulative CPU time: 2 seconds 700 msec
Ended Job = job_1478323409873_0001
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 2.7 sec HDFS Read: 237 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 700 msec
OK
3
Time taken: 35.475 seconds, Fetched: 1 row(s)
hive>
既然我们建的student表没有指定列与列的分割符,那么我们接下来再建一张表并且指定分隔符。我们就建一张teacher表吧,建表语句如下。
hive> create table teacher(id bigint,name string)row format delimited fields terminated by ‘\t’;
OK
Time taken: 0.545 seconds
hive> show create table teacher;
OK
CREATE TABLE `teacher`(
`id` bigint,
`name` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
STORED AS INPUTFORMAT
‘org.apache.hadoop.mapred.TextInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat’
LOCATION
‘hdfs://ns1/user/hive/warehouse/teacher’
TBLPROPERTIES (
‘transient_lastDdlTime’=’1478344693’)
Time taken: 0.309 seconds, Fetched: 13 row(s)
建好了teacher表,我们再来给teacher表中插入一些数据。我们的做法是新建一个teacher.txt文件并在里面输入一些数据,如下所示,输入完毕后保存退出该文件。
[root@itcast01 ~]# vim teacher.txt
1 赵老师
2 王老师
3 刘老师
4 邓老师
接下来我们把teacher.txt插入到teacher表当中。如下所示。
hive> load data local inpath ‘/root/teacher.txt’ into table teacher;
Copying data from file:/root/teacher.txt
Copying file: file:/root/teacher.txt
Loading data to table default.teacher
Table default.teacher stats: [numFiles=1, numRows=0, totalSize=48, rawDataSize=0]
OK
Time taken: 0.764 seconds
hive>
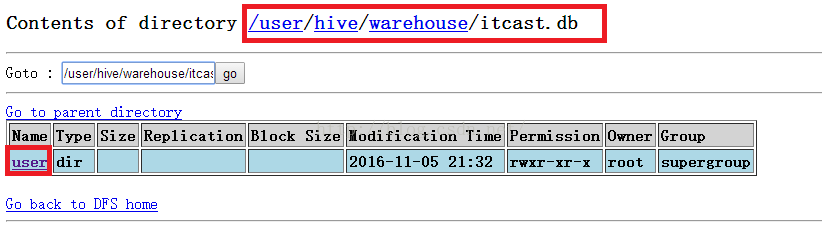
上传完后,我们到HDFS文件系统中去看看我们的teacher表及数据。如下图所示,发现我们的表及teacher.txt文件都存在于HDFS中。
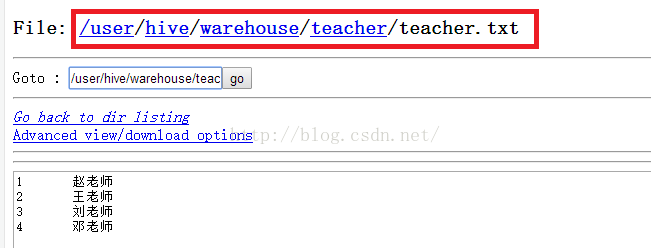
我们再通过shell命令来查看teacher表的信息,如下所示,可以看到我们查询到了teacher表中的数据。
hive> select * from teacher;
OK
1 赵老师
2 王老师
3 刘老师
4 邓老师
Time taken: 0.971 seconds, Fetched: 4 row(s)
hive>
我们以前学MapReduce的时数据的排序都需要我们手动写MapReduce程序来完成,现在有了Hive,我们只需要一条order by语句便可以搞定,假如我们想让teacher表中的数据降序排列,我们可以使用语句select * from teacher order by desc;我们并没有写任何MapReduce语句,接下来我们执行这条语句,信息如下,可以发现它会自动启用MapReduce来帮我们完成排序功能,真的是省去了我们很多麻烦。但是这也有个问题就是延迟性比较高,因为它要启动MapReduce,小弟要领取jar包领取任务,有可能还要执行多个MapReducer,因此延迟性便会比较多。
hive> select * from teacher order by id desc;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478323409873_0002, Tracking URL = http://itcast03:8088/proxy/application_1478323409873_0002/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478323409873_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-05 20:52:32,598 Stage-1 map = 0%, reduce = 0%
2016-11-05 20:52:40,933 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.4 sec
2016-11-05 20:52:47,147 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.43 sec
MapReduce Total cumulative CPU time: 2 seconds 430 msec
Ended Job = job_1478323409873_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 2.43 sec HDFS Read: 252 HDFS Write: 48 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 430 msec
OK
4 邓老师
3 刘老师
2 王老师
1 赵老师
Time taken: 25.794 seconds, Fetched: 4 row(s)
hive>
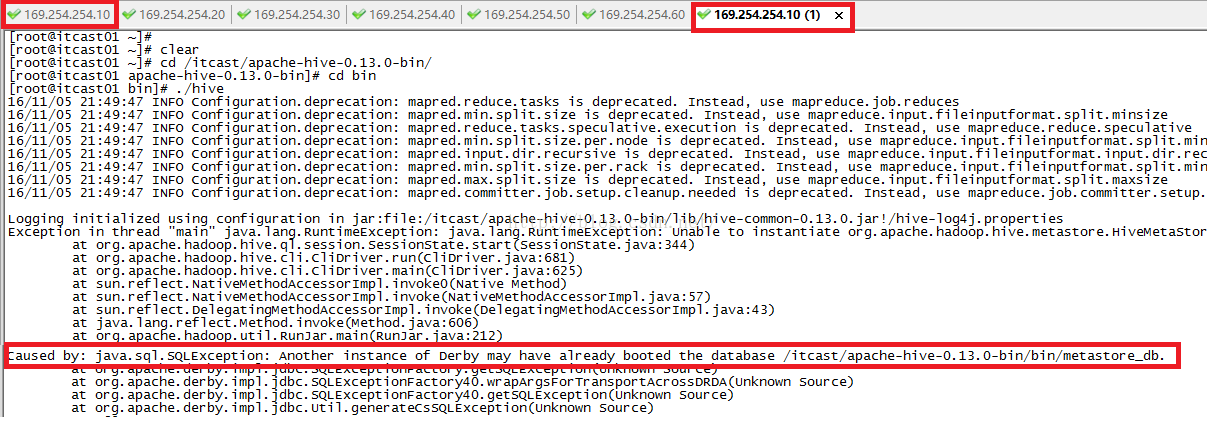
下面我们来说一下数据库的问题,我们在上面Hive架构图的时候提到了metadata元数据库,它里面有表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。Hive默认使用的元数据库是derby数据库,但是这个数据库有它致命的缺陷,那就是它仅支持单连接,这在公司的开发中简直就是恶梦。我下面为大家证明一下derby数据库仅支持单连接。
我们先hive的bin目录下启动hive并且建一个数据库itcast,如下所示。
启动hive
./hive
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/05 21:25:38 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
创建itcast数据库
hive>
create database itcast;
OK
Time taken: 0.579 seconds
查看当前所有的数据库
hive>
show databases;
OK
default
itcast
Time taken: 0.08 seconds, Fetched: 2 row(s)
查看当前所有的表(默认是在default数据库下)
hive>
show tables;
OK
student
teacher
Time taken: 0.037 seconds, Fetched: 2 row(s)
我们切换到itcast数据库
hive>
use itcast;
OK
Time taken: 0.012 seconds
查看itcast数据库下所有的表,当然,现在我们还没建任何表,因此没有任何表信息
hive>
show tables;
OK
Time taken: 0.017 seconds
我们创建一张user表,列与列之间用’\t’分割。
hive>
create table user(id int,name string) row format delimited fields terminated by ‘\t’;
OK
Time taken: 0.229 seconds
我们再来看看itcast数据库下都有哪些表,发现已经有一张user表了。
hive>
show tables;
OK
user
Time taken: 0.016 seconds, Fetched: 1 row(s)
hive>
beeline derby.log ext hive hive-config.sh hiveserver2
metastore_db metatool schematool
[root@itcast01 bin]#
[root@itcast01 apache-hive-0.13.0-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast01 apache-hive-0.13.0-bin]#
bin/hive
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/05 22:04:23 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
hive>
bin conf derby.log examples hcatalog lib LICENSE
metastore_db NOTICE README.txt RELEASE_NOTES.txt scripts
[root@itcast01 apache-hive-0.13.0-bin]#
3,安装mysql,
sudo apt-get install mysql-server mysql-client
安装途中会提示输入mysql密码,按照提示输入就是。
启动mysql服务 ‘sudo service mysql start’
注释:
重启mysql服务: ‘service mysql restart’
停止mysql服务: ‘service mysql stop’
查看mysql服务状态: ‘service mysql status’-
进入mysql 服务
3.1 创建hive用户
mysql -u root -p
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;
flush privileges;
use hive;
select user,host from mysql.user;
exit;ubuntu bin]#
hadoop fs -rm -r /user/hive
16/11/06 00:53:09 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /user/hive
[root@
ubuntu bin]#
hive-default.xml.template和hive-env.sh.template,
hive-default.xml.template是我们需要配置的。
ubuntu bin]# cd /itcast/
[root@
ubuntu itcast]# ls
apache-hive-0.13.0-bin hadoop-2.2.0 hbase-0.96.2-hadoop2 sqoop-1.4.6 sqoop-1.4.6.bin__hadoop-2.0.4-alpha
[root@
ubuntu itcast]# cd apache-hive-0.13.0-bin/
[root@
ubuntu apache-hive-0.13.0-bin]# ls
bin conf examples hcatalog lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts
[root@
ubuntu apache-hive-0.13.0-bin]# cd conf
[root@
ubuntu conf]# ls
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@
ubuntu conf]#
hive-default.xml.template,我们需要先把它的名字修改一下,将其改为hive-site.xml,如下所示。
ubuntu conf]# ls
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@
ubuntu conf]#
mv hive-default.xml.template hive-site.xml
[root@
ubuntu conf]# ls
hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
hive-site.xml
[root@
ubuntu conf]#
<!–配置连接的URL,现在我们的mysql安装在了ubuntu上了,因此我们改成
ubuntu,如果hive库不存在我们创建它–>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ubuntu:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!–连接驱动–>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!–连接数据库的用户名–>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!–连接数据库的密码–>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12qw</value>
<description>password to use against metastore database</description>
</property>
</configuration>
ubuntu的hive的lib包下放mysql的驱动包,大家如果没有驱动包的话,可以到http://download.csdn.net/detail/u012453843/9667329这个地址进行下载。
ubuntu ~]# ls
anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs
mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
[root@
ubuntu ~]#
cp mysql-connector-java-5.1.40-bin.jar /itcast/apache-hive-0.13.0-bin/lib/
[root@
ubuntu ~]#
进入到mysql mysql -u root -p
在root用户下创建hive数据库。create database hive;
ubuntu ~]# cd /itcast/apache-hive-0.13.0-bin/bin
[root@
ubuntu bin]# ./hive
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 01:18:07 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Exception in thread “main” java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:344)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:625)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:964)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:897)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:886)
at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1040)
首先我们以root身份登录ubuntu上的mysql
ubuntu ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 5.1.73 MySQL Community Server (GPL)
affiliates. Other names may be trademarks of their respective
owners.
执行下面的语句 *.*:所有库下的所有表 %:任何IP地址或主机都可以连接
Query OK, 0 rows affected (0.00 sec)
刷新一下权限
Query OK, 0 rows affected (0.00 sec)
ubuntu bin]# ./hive
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 01:27:20 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
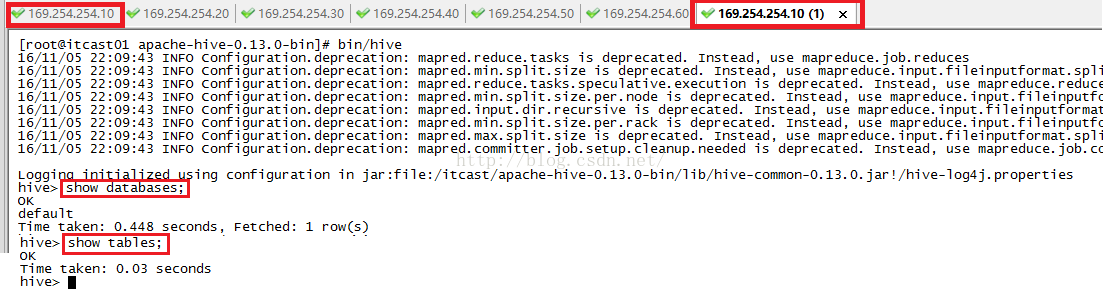
hive> show tables;
OK
Time taken: 0.619 seconds
hive> create table people (id int,name string);
OK
Time taken: 0.396 seconds
hive>
4,数据在mysql的存储
在window上使用navicat远程链接数据库,可能出现无法访问的情况,可参照小编的博文:https://blog.csdn.net/csdnliuxin123524/article/details/79715997
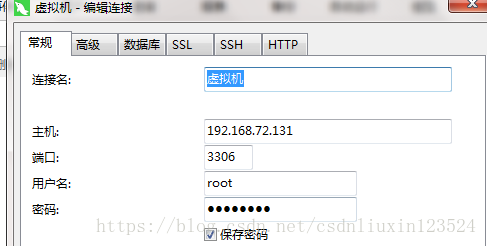
连上mysql之后,如下图所示,可以看到mysql数据库自动多了一个hive库,这里面大概有二十几张表,这里面存放的是元数据信息。
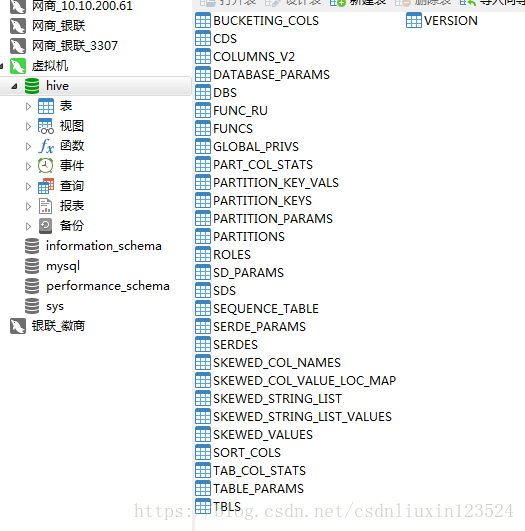

那么表有哪些字段在哪儿保存呢?它其实保存在COLUMNS_V2中,如下图所示。那么它怎么知道这两个字段是属于people表的呢,它其实是有外键的。
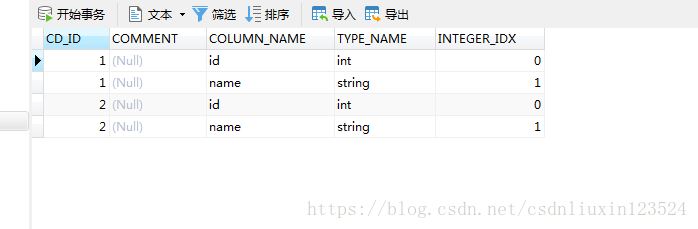
那么在哪儿存放着数据的存放路径呢,如下图所示,可以看到在SDS当中存放着我们的数据在HDFS上的存放路径。

我们到HDFS上看下people表的路径,如下图所示,发现确实是正确的。
5,解决单链接
这里我们还需要验证一下我们使用mysql之后是否真的解决了Derby数据库仅支持单连接的问题。
启动前先查看当前目录下有哪些文件,如下
anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
启动hive
[root@
ubuntu ~]#
/itcast/apache-hive-0.13.0-bin/bin/hive
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/06 09:48:18 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
启动成功后查看表,可以查到people表
hive>
show tables;
OK
people
Time taken: 0.401 seconds, Fetched: 1 row(s)
退出hive视图
hive> exit;
再次查看当前目录下的文件,发现跟启动hive前是一样的!说明我们配置的Mysql完全解决了Derby数据库的缺陷!!
[root@
ubuntu ~]# ls
anaconda-ks.cfg Documents hbase-0.96.2-hadoop2-bin.tar.gz install.log.syslog logs mysql-connector-java-5.1.40-bin.jar Public Templates time wc.txt
Desktop Downloads install.log jdk-7u80-linux-x64.gz Music Pictures sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz test.sh Videos
[root@
ubuntu ~]#
6,设置环境变量
用户目录下修改./bashrc

加入
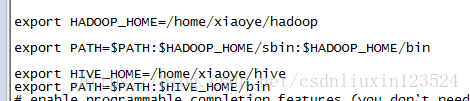
export HIVE_HOME=/home/xiaoye/hive
export PATH=$PATH:$HIVE_HOME/bin
7.原理讲解:
我们先来看一下Hive的简介,如下图所示,Hive是一个数据仓库,它部署在Hadoop集群上,它的数据是存储在HDFS上的,Hive所建的表在HDFS上对应的是一个文件夹,表的内容对应的是一个文件。它不仅可以存储大量的数据而且可以对存储的数据进行分析,但它有个缺点就是不能实时的更新数据,无法直接修改和删除数据,如果想要修改数据需要先把数据所在的文件下载下来,修改完之后再上传上去。Hive的语法非常类似于我们的MySQL语句,所以上起手来特别容易。HIve特别神奇的地方是我们只需写一条SQL语句它就会自动转换为MapReduce任务去执行,不用我们再手动去写MapReduce了。

图一 Hive简介

图二 Hive简介
接下来我们一起来看一下Hive的系统架构图,如下图所示,这张图还是比较老的图,不过还是可以拿来学习的,我们看到Hive的最上方是CLI、JDBC/ODBC、WebUI。CLI的意思是Command Line Interface(命令行接口),这意味着我们可以通过三种方式来操作我们的Hive,我们发送命令用CLI,尽量不要使用JDBC/ODBC因为事实证明它是有很多问题的,我们可以通过Web来浏览我们的Hive表及数据。元数据我们一般存储在mysql当中(Hive默认的数据库是derby),元数据是指表的信息,比如表的名字,表有哪些列等等描述信息。并不是我们要计算的数据。我们向表中插入的数据是保存在HDFS上的。
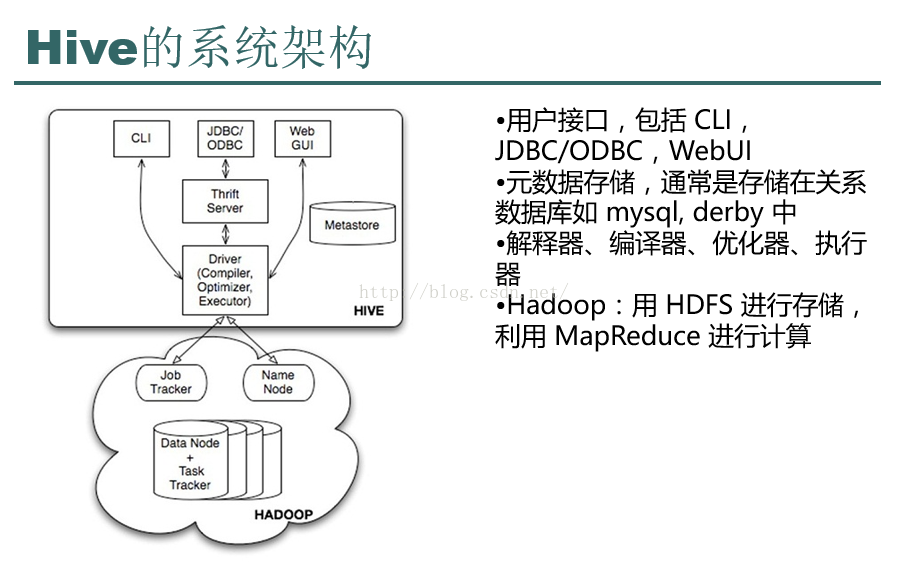
图三 Hive架构图

图四 Hive系统架构说明。
5,遇到错误
5.1ls: Call From ubuntu/127.0.1.1 to ubuntu:9000 failed on connection exception
访问hdfs时出现的错误,如 hadoop fs -ls / 查看hdfs系统的文件,或启动hive后创建表报出的错。报错的大概意思是,访问hdfs的127.0.1.1不能连接,经过一般试探,总结出应该是更换了hadoop后出现了问题,并且问题是hadoop/etc/hadoop/目录下的core-site.xml文件的ip配置和虚拟机的hosts文件配置不一致。因此这里小编就把原先core-site.xml的ip由192.168.26.129改为ubuntu,并且把mapred-site.xml,和hdfs-site.xml两个文件出现的地方也改成一样的。然后还要先停hadoop在hadoop namenode -format 格式化主节点,再启动hdfs。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106184.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...