大家好,又见面了,我是你们的朋友全栈君。
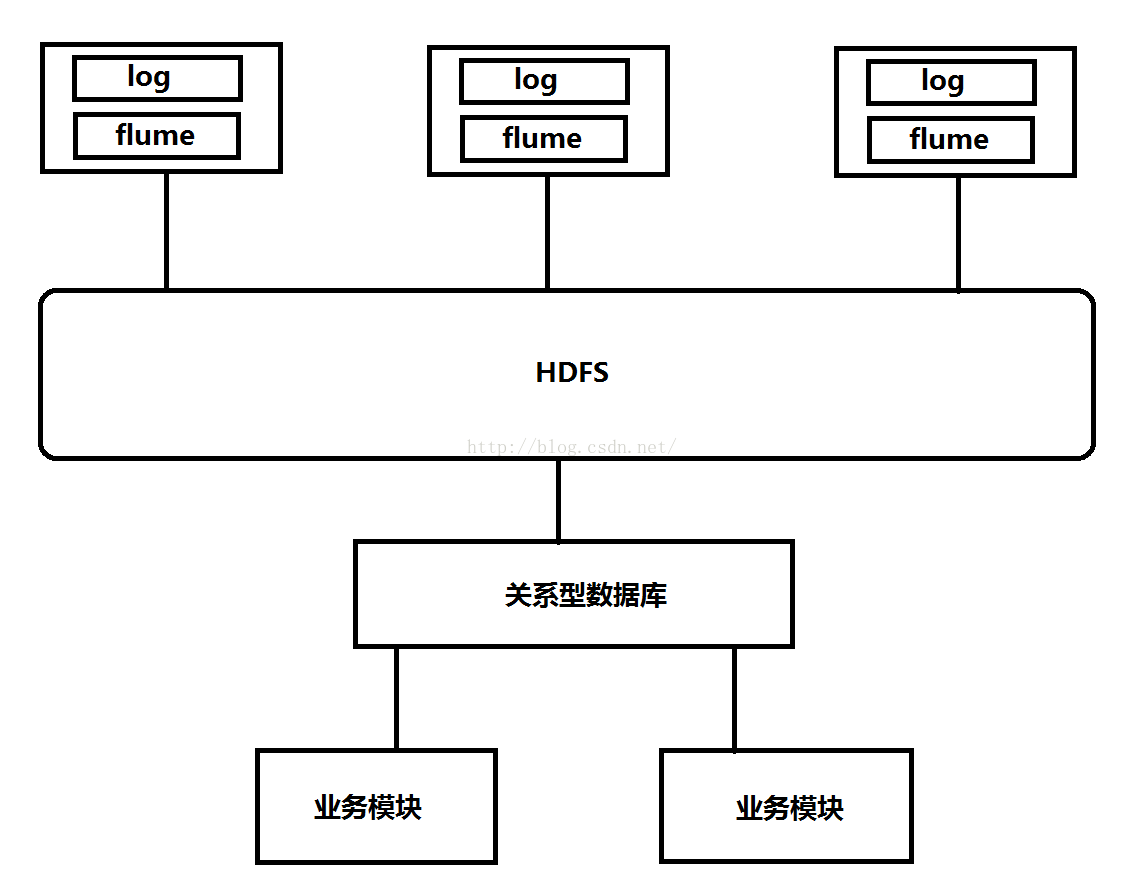
先我们来看一张图,如下所示,最上方代表三台设备,当然可以是更多的设备,每台设备运行过程都会产生一些log,这些log是我们需要的信息,我们不可能手动的一台一台的去收集这些log,那样的话太浪费人力了,这就需要一个自动化的采集工具,而我们今天要说的Flume便是自动化采集工具中的代表,flume可以自动从设备收集log然后将这些log上传到HDFS,HDFS会对这些log进行过滤,过滤后为了方便业务模块实时查询,HDFS会将过滤好的数据通过Sqoop工具导入到关系型数据库当中,从而各个业务模块可以去关系型数据库中去读取数据然后展示给用户。

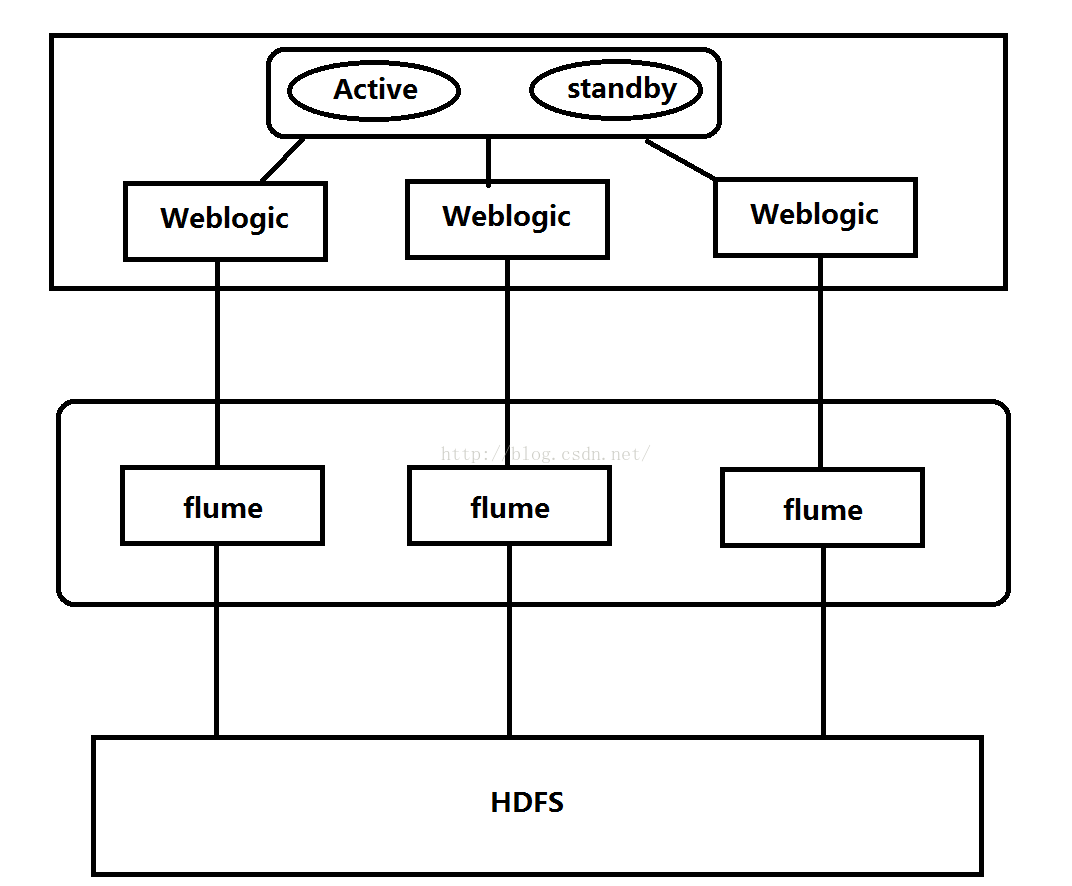
但是在现实开发过程中有可能客户不让你随便给人家的服务器上安装软件,比如与银行合作开发项目,人家为了安全是不让随便安装软件的,那么怎么解决呢?我们看下下面这张图。下面这张图的上面部分显示的是银行的集群,其中Active和standby状态的两台服务器是负载均衡服务器,它们下方的三台服务器是Weblogic服务器,我们要得到银行设备的log,我们可以在外网的设备上安装Flume自动化采集工具,银行的集群一般与外网也有接口,我们可以让银行向我们的服务器上发送log,当然为了防止log中途被截获,需要我们与银行定义一套加密解密规则,银行把log加密之后发送出来,我们的Flume工具便接收到这些log,然后将这些log解密之后发送到HDFS,之后我们便又可以像第一张图那样过滤数据并将数据导入关系型数据库并共业务模块查询等等。
Flume是一个自动化采集框架,既然是框架,很多东西都不用我们去写了,甚至我们都不用写java代码便可以实现我们的目的,这就是框架的好处!
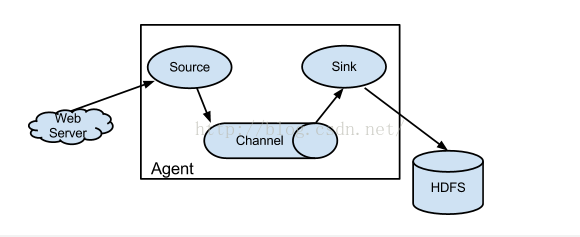
下面我们来看一张图,Agent也就是Flume,是由三部分组成的,第一部分是Source,Source是用来采集数据的,Channel是用来暂时保存数据的,Sink是将数据写到某种介质当中,比如写到HDFS、数据库、文件等。那么为什么Agent要分成三个组件呢?这是为了灵活搭配满足我们的个性化需求而这样设计的。三个组件分别有多个实现类,以Source为例,我们可以监听某个端口,我们可以监听某个文件夹,还可以使用tail -f来实时监听log文件,只要有数据就收集过来。这需要不同的实现类来完成,Channel作为临时存储介质也有多个实现类,比如Memory Channel,这样的Channel的优点是效率高,但是缺点是数据容易丢失。我们可以使用File Channel。Sink可以写到不同的介质当中HDFS只是其中的一种而已,我们还可以写到HBase、Oracle等介质当中。我们可以根据需要灵活搭配,只需要更改配置文件内容即可,不需要我们写代码。
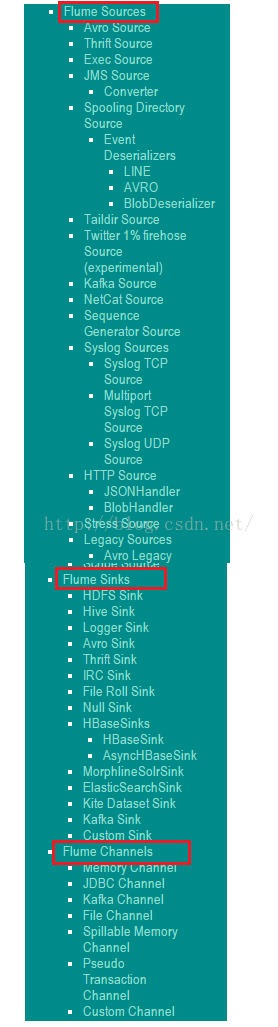
Source、Sink、Channel三个组件的实现类列表如下图所示。
二 ,安装flume
下载地址:http://archive.cloudera.com/cdh5/cdh/5/
上传,解压,修改目录名,最终如下:

修改配置文件:
更改flume-env.sh文件名,并设置此脚本的JAVA_HOME路径:
xiaoye@ubuntu:~$ cd flume/
xiaoye@ubuntu:~/flume$ ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
xiaoye@ubuntu:~/flume$ cd conf
xiaoye@ubuntu:~/flume/conf$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
xiaoye@ubuntu:~/flume/conf$ cp flume-env.sh.template flume-env.sh
xiaoye@ubuntu:~/flume/conf$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh flume-env.sh.template log4j.properties
xiaoye@ubuntu:~/flume/conf$ vim flume-env.sh
# If this file is placed at FLUME_CONF_DIR/flume-env.sh, it will be sourced
# during Flume startup.
# Enviroment variables can be set here.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
# export JAVA_OPTS=”-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote”
下面我们来配置Agent的三个组件,既然要配置就需要有配置文件,我们人工建一个配置文件,起名叫a4.conf(当然也可以叫a5.conf或其它名字)。下面我们看看a4.conf文件中的内容,配置文件中的注释可能还不够详细,我再说的具体一点,一开始是给source、channel、sink起个名字;接下来具体配置source,我们定义的spooldir是监听一个目录,监听的目录是/root/logs目录,你只要向这个目录放数据它就能监听到;接下来我们定义具体的channel,我们配置的是memory类型的channel这种类型的channel的优点是速度快,但有个缺点就是容易丢失数据。我们配置的memory channel的最大容纳数据量是10000条,达到10000条便将数据写出去,memory事务的容量是100;接着是拦截器,拦截器可以帮我们过滤一些数据,同时它还可以帮我们做一些处理,比如我们下面配置的拦截器就是帮我们给数据添加时间戳,根据时间戳我们便可以动态的将数据写入到指定日期的文件当中,这就相当于分区功能了。我们来看看sink,我们配置的sink的具体实现是HDFS,配置了channel将数据写到HDFS上的目录是flume下以年月日为文件名的文件当中,文件的前缀是events-,文件类型是纯文本方式(还可以是压缩文件)。sink配置中的rollCount是指每多少条flush成一个文件,如果配置成0则代表不按照条数生成文件,紧接着配置了当文件达到128M时会生成一个文件,或者时间达到60秒时也会生成一个文件。最后将source、channel、sink组装起来。
在flumn的conf目录下touch一个a4.conf文件
a4.conf文件的内容,读者要根据自己的目录修改一两处文件目录名字:
gent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /home/xiaoye/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://ns/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1准备jar包,
我们在运行flume之前需要先准备一些jar包,首先我们需要hadoop-common-*.jar,
jar我们可以到hadoop的安装目录中去找,如下:
xiaoye@ubuntu2:~/hadoop$ cd share/
xiaoye@ubuntu2:~/hadoop/share$ ls
doc hadoop
xiaoye@ubuntu2:~/hadoop/share$ cd hadoop/
xiaoye@ubuntu2:~/hadoop/share/hadoop$ ls
common hdfs httpfs kms mapreduce mapreduce1 mapreduce2 tools yarn
这里我们要找common的包就ls看看有什么
xiaoye@ubuntu2:~/hadoop/share/hadoop$ ls common/
hadoop-common-2.5.0-cdh5.2.0.jar jdiff templates
hadoop-common-2.5.0-cdh5.2.0-tests.jar lib
hadoop-nfs-2.5.0-cdh5.2.0.jar
发现有我们需要的包,拷到flume的lib目录下:
xiaoye@ubuntu2:~/hadoop/share/hadoop$ cd common/
xiaoye@ubuntu2:~/hadoop/share/hadoop/common$ pwd
/home/xiaoye/hadoop/share/hadoop/common
xiaoye@ubuntu:~/flume/lib$ cp /home/xiaoye/hadoop/share/hadoop/common/hadoop-common-2.5.0-cdh5.2.0.jar ./
这样就拷过去了。
接着我们来拷贝commons-configuration-1.6.jar和hadoop-auth-2.2.0.jar,
xiaoye@ubuntu:~/flume/lib$ cp /home/xiaoye/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar ./
xiaoye@ubuntu:~/flume/lib$ cp /home/xiaoye/hadoop/share/hadoop/common/lib/hadoop-auth-2.5.0-cdh5.2.0.jar ./
这样也考过去了。
最后我们来拷贝hadoop-hdfs-2.2.0.jar,如下:
xiaoye@ubuntu2:~/hadoop/share/hadoop/common$ cd ..
xiaoye@ubuntu2:~/hadoop/share/hadoop$ cd hdfs/
xiaoye@ubuntu2:~/hadoop/share/hadoop/hdfs$ ls
hadoop-hdfs-2.5.0-cdh5.2.0.jar jdiff templates
hadoop-hdfs-2.5.0-cdh5.2.0-tests.jar lib webapps
hadoop-hdfs-nfs-2.5.0-cdh5.2.0.jar sources
xiaoye@ubuntu2:~/hadoop/share/hadoop/hdfs$ pwd
/home/xiaoye/hadoop/share/hadoop/hdfs
xiaoye@ubuntu2:~/hadoop/share/hadoop/hdfs$ pwd
/home/xiaoye/hadoop/share/hadoop/hdfs
xiaoye@ubuntu:~/flume/lib$ cp /home/xiaoye/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.5.0-cdh5.2.0.jar ./
这个也好了。
接着,
拷贝配置文件
之所以拷贝配置文件是因为我们配置flume的时候配置了hdfs://ns,这个配置的意思是让flume连向HDFS的NameNode的一个抽象,那么flume该怎么知道namenode和datanode在哪些设备上呢?就是通过core-site.xml和hdfs-site.xml这两个配置文件知道的。
xiaoye@ubuntu:~/flume$ cd conf/
xiaoye@ubuntu:~/flume/conf$ cp /home/xiaoye/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml} ./
xiaoye@ubuntu:~/flume/conf$ ls
a4.conf flume-env.ps1.template hdfs-site.xml
core-site.xml flume-env.sh log4j.properties
flume-conf.properties.template flume-env.sh.template
这样就把hadoop的两个配置文件放到了flume的conf目录下。
最后创建监控日志目录,这里我们安装刚才配置文件设置的目录创建一个目录:
xiaoye@ubuntu:~/flume/conf$ cd ~
xiaoye@ubuntu:~$ ls
apache-activemq-5.15.3 examples.desktop Music sqoop
classes flume no Templates
derby.log hadoop no.pub Videos
Desktop hbase Pictures zookeeper
Documents hive product.java zookeeper.out
Downloads metastore_db Public
xiaoye@ubuntu:~$ mkdir logs
xiaoye@ubuntu:~$ ls
apache-activemq-5.15.3 examples.desktop metastore_db Public
classes flume Music sqoop
derby.log hadoop no Templates
Desktop hbase no.pub Videos
Documents hive Pictures zookeeper
Downloads logs product.java zookeeper.out
xiaoye@ubuntu:~$
启动flume
前面做了那么多铺垫,我们现在终于要启动flume了,启动前我们要先启动hdfs,这里我就不多说了,读者可参考前面的博文。如下所示,命令的参数的意思是,agent是指我们要配置agent的参数,-n代表agent的名字,-c代表conf目录,-f代表agent中三个组件的具体配置,它在conf/a4.conf当中,-Dflume.root.logger=INFO,console是指日志信息级别是INFO,console表示输出到控制台
命令:
xiaoye@ubuntu:~$ ./flume/bin/flume-ng agent -n a4 -c conf -f conf/a4/conf -Dflume.root.logger=INFO,console下面,我们copy一个日志文件放到/home/xiaoye/logs目录下。随便找一个吧。这里我找了hadoop/logs下的namenode日志。
xiaoye@ubuntu:~/hadoop/logs$ cp hadoop-xiaoye-namenode-ubuntu.log ~/logs/
因为flume能够事实监控日志,所以我们把日志拷到/home/xiaoye/logs目录下时,监听界面看看控制台这时输出的信息,可以看到如下所示的信息,说明将内容都写完了。
因为我们设置把监控的日志最终写到hdfs上,那我们到hdfs上看看是不是生成了flume目录。
发现目录确实生成了,可打开这个目录看看最终的文件,里面的内容就是我们传进去的日志内容。
下面我们再来试一下另一个Agent,配置文件的名字是a2.conf,内容如下所示,我们source具体定义的是命令类型的source,实时监听/home/xiaoye/logs文件,如果该文件的内容发生变化将实时写出去,channel还是配置memory,sink配置成最简单的logger。
创建a2.conf文件
xiaoye@ubuntu:~$ cd flume/conf/
xiaoye@ubuntu:~/flume/conf$ vim a2.conf
文件内容如下:
gent名, source、channel、sink的名称
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#具体定义source
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /home/xiaoye/logs/tailLog
#具体定义channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
#具体定义sink
a2.sinks.k1.type = logger
#组装source、channel、sink
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1在创建的日志中随便写点东西。
xiaoye@ubuntu:~/logs$ vim tailLog
xiaoye@ubuntu:~/logs$ cat tailLog
33333333333333333
下面我们启动flume,成功的话我们可以看到监控界面能够打印出我们再日志中写的内容。
命令:
xiaoye@ubuntu:~/flume$ bin/flume-ng agent -n a2 -c conf/ -f conf.a2.conf -Dflume.root.logger=INFO,console2018-04-07 05:37:13,114 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO – org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 33 33 33 33 33 33 33 33 33 33 33 33 33 33 33 33 3333333333333333 }
2018-04-07 05:37:13,116 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO – org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 34 34 34 34 34 44444 }
2018-04-07 05:37:13,118 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO – org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 34 34 34 34 34 44444 }
2018-04-07 05:37:13,120 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO – org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 34 34 34 34 34
我们也可以往日志里面追加内容:
xiaoye@ubuntu:~/logs$ echo “44444” >> tailLog
xiaoye@ubuntu:~/logs$ echo “4eeer44” >> tailLog
xiaoye@ubuntu:~/logs$ echo “4eeer4444444444” >> tailLog
监控界面是有对应结果的:

好了,大功告成。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106163.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
