大家好,又见面了,我是你们的朋友全栈君。
文章转自:https://blog.csdn.net/u012453843/article/details/72865687
先看如下代码:
package com.xiaoyexinxin.ThreadLearn;
public class DirtyRead {
private String username = "bjfdz";
private String password = "123";
public synchronized void setValue(String username,String password){
//先修改username的值
this.username = username;
//在修改密码之前先让程序休息两秒
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
//修改密码
this.password = password;
//修改完后打印用户名和密码信息
System.out.println("setValue最终结果:username="+username+",password="+password);
}
public void getValue(){
System.out.println("getValue方法得到:username = "+this.username+", password = "+this.password);
}
public static void main(String[] args) throws InterruptedException{
final DirtyRead dr = new DirtyRead();
Thread t1 = new Thread(new Runnable() {
public void run() {
dr.setValue("zhangsan", "456");
}
});
t1.start();
Thread.sleep(1000);
dr.getValue();
}
}
执行结果:
getValue方法得到:username = zhangsan, password = 123
setValue最终结果:username=zhangsan,password=456这是个修改用户名和密码的 简易程序。看最后的执行结果,这个结果我们要倒过来看,想先看set,再看get。会发现只改了用户名。而密码没有改成功,这就是脏读了。因为程序在修改的过程先只修改了用户名,然后中睡眠了2s,在此期间只有人来读取数据就出现了用户名修改了,但是密码没来得及修改的情况。
下面说下Oracle数据库脏读的场景以及Oracle数据库是如何避免脏读的,假如有张表有千万级的数据,用户要查询某条记录(假如该记录开始的 值 是100),假如要查询的这条记录在表的第一千万行,那么查询需要大概10分钟的时间,假如这10分钟期间有别的用户修改了这条记录(假如将该 值 修改成200了并且事务提交了),那么用户查询的结果是多少呢?相信很多人都会认为是200,我当时也是这样认为的。事实上查询到的结果是100,这是为何呢?原因是Oracle数据库采用了undo机制。Undo就是用来记录保存事务操作过程中的数据,如果事务发生错误,可以将之前的数据进行填补。

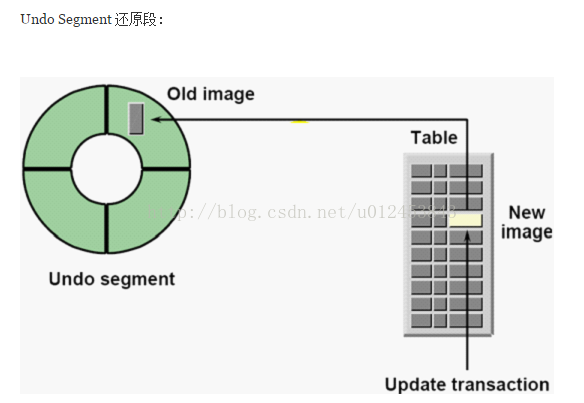
从来面的视图,我们就可以很清晰的看出,我们要对表(table)中的一个数据进行修改,在修改之前,先把老的映像(old image)放到undo 上面。然后再在table中放入new image 。假如过程失败,我们还可以把undo 上的old image 再拿回来放在原先的位置,从而使这件事儿看起来像没发生过一样。
当我们执行一个事务的时候,oracle会分配一个SCN编号,这个编号是递增的。下一个事务的编号一定比当前事务的编号大。假如执行查询时分配的事务编号为10023,在这个事务执行的过程中,另一事务对数据进行了修改。用来替换的数据块SCN编号为10024 ,而被替换掉的数据块会被保存到undo 上面。当第一个事务执行到被修改过的数据块时,发现10024比10023大,这个时候就会到undo segment上找比自己SCN号小的数据块进行读,于是发找到了SCN号为10008和10021两个块。这样就有效的保证了读一致性。
当然,会有一种特殊情况,也就是undo segment 太小,最多放100条数据,可一下子来了120条数据,那么最先写入的20条数据被最后写入的20条数据覆盖。这个时候就会报错,这也是为什么要对数据据进行调优的原因。
Undo segment 是保存在表空间上的。Undo 大小是固定的,既然是固定的也就是有限的。如果保存的记录非常多,那么它就会被占满,新记录的数据会覆盖掉最早的数据。所以用一个圆形的盘片能更加形象的表示。数据从一个位置开始写入,当写满一圈后,最新的数据就会覆盖最早写入的数据。
以上是Oracle处理脏读的方法。下面我们学习下Mysql是如何避免脏读的
MySQL InnoDB事务隔离级别脏读、可重复读、幻读
MySQL InnoDB事务的隔离级别有四级,默认是“可重复读”(REPEATABLE READ)。
· 1).未提交读(READUNCOMMITTED)。另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据(脏读)( 隔离级别最低,并发性能高 )。
· 2).提交读(READCOMMITTED)。本事务读取到的是最新的数据(其他事务提交后的)。问题是,在同一个事务里,前后两次相同的SELECT会读到不同的结果(不重复读)。会出现不可重复读、幻读问题(锁定正在读取的行)
· 3).可重复读(REPEATABLEREAD)。在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象(稍后解释)。会出幻读(锁定所读取的所有行)。
· 4).串行化(SERIALIZABLE)。读操作会隐式获取共享锁,可以保证不同事务间的互斥(锁表)。
‘
四个级别逐渐增强,每个级别解决一个问题。
· 1).脏读。另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据。
· 2).不重复读。解决了脏读后,会遇到,同一个事务执行过程中,另外一个事务提交了新数据,因此本事务先后两次读到的数据结果会不一致。
· 3).幻读。解决了不重复读,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数据,本事务再更新时,就会“惊奇的”发现了这些新数据,貌似之前读到的数据是“鬼影”一样的幻觉。
MySQL四种事务在脏读、不可重复读、幻读的处理。READCOMMITTED、REPEATABLEREAD、SERIALIZABLE都可以解决脏读问题。
在我们对一个对象的方法加锁的时候,需要考虑业务的整体性,即为setValue/getValue方法同时加锁synchronized同步关键字,保证业务(service)的原子性,不然会出现业务错误(也从侧面保证业务的一致性)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106150.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
