大家好,又见面了,我是你们的朋友全栈君。

作用:
(1)健康检测:zkfc会周期性的向它监控的namenode(只有namenode才有zkfc进程,并且每个namenode各一个)发生健康探测命令,从而鉴定某个namenode是否处于正常工作状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于不健康的状态;
(2)会话管理:如果namenode是健康的,zkfc机会保持在zookeeper中保持一个打开的会话,如果namenode是active状态的,那么zkfc还会在zookeeper中占有一个类型为短暂类型的znode,当这个namenode挂掉时,这个znode将会被删除,然后备用的namenode得到这把锁,升级为主的namenode,同时标记状态为active,当宕机的namenode,重新启动,他会再次注册zookeeper,发现已经有znode了,就自动变为standby状态,如此往复循环,保证高可靠性,但是目前仅支持最多配置两个namenode.
(3)master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断哪个namenode为active状态。
工作过程:
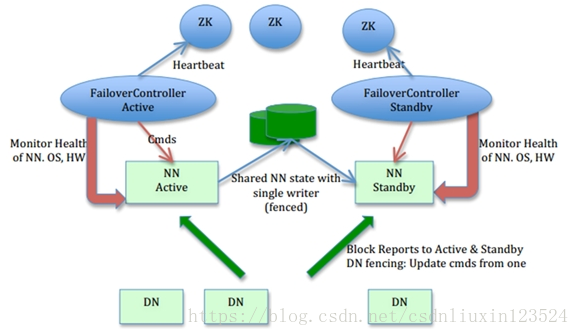
上图是一张Hadoop高可靠性的工作原理图,其中NN代表的是NameNode,DN代表的是DataNode,ZK代表的是Zookeeper,我们发现这个集群当中有两个NameNode,一个处于Active状态,另一个处于Standby状态,NameNode是受Zookeeper控制的,但是又不是直接受Zookeeper控制,有一个中间件FailoverController(也就是ZKFC进程),每一个NameNode所在的机器都有一个ZKFC进程,ZKFC可以给NameNode发送一些指令,比如切换指令。同时ZKFC还负责监控NameNode,一旦它发现NameNode宕机了,它就会报告给Zookeeper,另一台NameNode上的ZKFC可以得到那一台NameNode宕机的信息,因为Zookeeper数据是同步的,因此它可以从ZK中得到这条信息,它得到这条信息之后,会向它控制的NameNode发送一条指令,让它由Standby状态切换为Active状态。具体原理是什么呢,刚开始的时候两个NameNode都正常工作,处于激活状态的NameNode会实时的把edits文件写入到存放edits的一个介质当中(如下图绿色的如数据库图形的东西),Standby状态的NameNode会实时的把介质当中的edits文件同步到它自己所在的机器。因此Active里面的信息与Standby里面的信息是实时同步的。FailoverController实时监控NameNode,不断把NameNode的情况汇报给Zookeeper,一旦Active状态的NameNode发生宕机,FailoverController就跟NameNode联系不上了,联系不上之后,FailoverController就会把Active宕机的信息汇报给Zookeeper,另一个FailoverController便从ZK中得到了这条信息,然后它给监控的NameNode发送切换指令,让它由Standby状态切换为Active状态。存放edits文件的方式可以使用NFS—网络文件系统,另一种是JournalNode,DataNode连向的是NameService,DataNode既可以跟Active的NameNode通信又可以跟Standby的NameNode通信,一旦Active宕机,DataNode会自动向新的Active进行通信。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106127.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
