大家好,又见面了,我是你们的朋友全栈君。
MRv1缺点
1、JobTracker容易存在单点故障
2、JobTracker负担重,既要负责资源管理,又要进行作业调度;当需处理太多任务时,会造成过多的资源消耗。
3、当mapreduce job非常多的时候,会造成很大的内存开销,在
TaskTracker端,以mapreduce task的数目作为资源的表示过于简单,没有考虑到cpu以及内存的占用情况,如果两个大内存消耗的task被调度到了一块,很容易出现OutOfMemory异常。
4、在TaskTracker端,把资源强制划分为map task slot和reduce task slot,如果当系统中只有map task或者只有reduce task的时候,会造成资源的浪费。
这里我们讲的是hadoop集群的作业调度和资源管理。
首先说一下hadoop低版本的MapReduce处理流程:
先介绍三个概念,
Job Tracker:是Map-reduce框架的中心,他需要与集群中的机器定时通信heartbeat,需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
TaskTracker:是Map-Reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
slot:hdfs的基本存储单元,是一个量词,可称为插槽

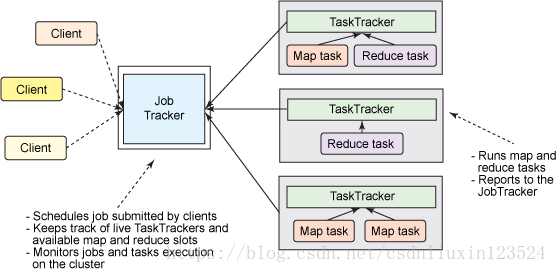
执行过程:
当一个客户端向一个 Hadoop 集群发出一个请求时,此请求由 JobTracker 管理。JobTracker 与 NameNode 联合将工作分发到离它所处理的数据尽可能近的位置。NameNode 是文件系统的主系统,提供元数据服务来执行数据分发和复制。JobTracker 将 Map 和 Reduce 任务安排到一个或多个 TaskTracker 上的可用插槽中。TaskTracker 与 DataNode(分布式文件系统)一起对来自 DataNode 的数据执行 Map 和 Reduce 任务。当 Map 和 Reduce 任务完成时,TaskTracker 会告知 JobTracker,后者确定所有任务何时完成并最终告知客户作业已完成。
存在的问题:
存在单点故障,影响可扩展性和稳定性
Hadoop 1.0中HDFS的NameNode和MapReduce的JobTracker设计为单一节点,这将是整个系统的单点故障源(SPOF)。单点故障主要由以下两个原因导致:
NameNode内存消耗过大
DataNode会定期向NameNode发送Block Report,这些数据是占用内存空间的,随着Hadoop集群存储空间的增多,这些Block Report会越来越多,因此NameNode的内存容量成为制约Hadoop集群的一个重要因素。
JobTracker内存消耗过大
随着JobTracker处理的job数量的增长,任务数量也随着增长,从而导致JobTracker的内存消耗过大,同时任务失败的概率也随着增加。
资源管理方案不灵活
slot数目无法动态修改。Hadoop 1.0采用了静态slot资源设置策略,即每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。
资源无法共享。Hadoop 1.0将slot分为Map slot和Reduce slot两种,且不允许共享。对于一个作业,刚开始运行时,Map slot资源紧缺而Reduce slot空闲,当Map Task全部运行完成后,Reduce slot紧缺而Map slot空闲。很明显,这种区分slot类别的资源管理方案在一定程度上降低了slot的利用率。
资源划分粒度粗糙。这种基于slot的资源划分方法的划分粒度仍过于粗糙,往往会造成节点资源利用率过高或者过低。比如,Hadoop默认为每个slot分配2G内存和1个CPU,如果一个应用程序的任务只需要1GB内存,则会产生“资源碎片”,从而降低集群资源的利用率;同样,如果一个应用程序的任务需要3GB内存,则会隐式地抢占其他任务的资源,从而产生资源抢占现象,可能导致集群利用率过高。另外,slot只是从内存和CPU的角度对资源进行分配,在实际系统中,资源本身是多维度的,例如:CPU、内存、网络I/O和磁盘I/O等。
没引入有效的资源隔离机制。Hadoop 1.0仅采用了基于jvm的资源隔离机制,这种方式仍过于粗糙,很多资源,比如CPU,无法进行隔离,这会造成同一个节点上的任务之间干扰严重。
计算模式单一。只支持MapReduce模式,不能有效的支持Storm、Spark等计算框架。
比如,假设Hadoop 1.0同时运行10个job,每个job有100个task,假设每个task运行在不同的机器上,那么,就有1000个节点在同时运行。如果每个节点(即每个task)每个5分钟向JobTracker发送心跳,那么JobTracker节点的压力会特别大,所以正常情况下Hadoop 1.0的集群规模只能达到4000台左右。JobTracker压力过重也是造成Hadoop 1.0单点故障和可扩展性差的重要原因。
Yarn
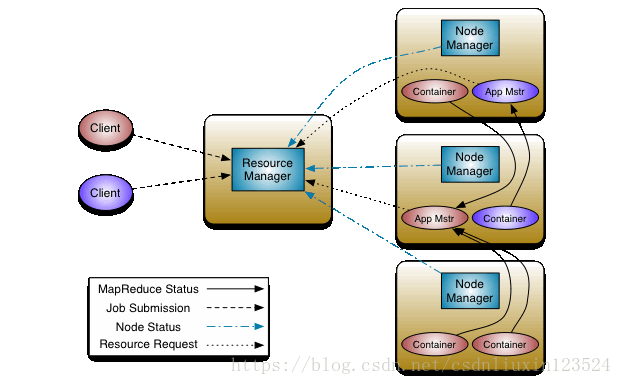
先介绍几个名词:
全局资源管理器 Resource Manager:是一个全局的资源管理器 ,它做的事情是调度、启动每一个Job所属的ApplicationMaster、另外监控ApplicationMaster的存在情况
针对每个应用程序的应用程序管理器 ApplicationMaster:是每一个Job(不是每一种)都有的一个部分,ApplicationMaster可以运行在ResourceManager以外的机器上。
节点管理器 NodeManager:是ResourceManager的在每个节点的代理,负责 Container 状态的维护,并向RM保持心跳。
容器 Container:是当AM向RM申请资源时,RM为AM分配的资源容器
调度器(scheduler)在资源管理器里,根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
ApplicaionManager: 主要负责接收作业,协商获取第一个容器用于执行ApplicationMaster和提供重启失败AM container的服务。
Yarn的架构图:
YARN应用工作流程
如下图所示用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
-
启动AM ,如下步骤1~3;
-
由AM创建应用程序为它申请资源并监控它的整个运行过程,直到运行完成,如下步骤4~7。
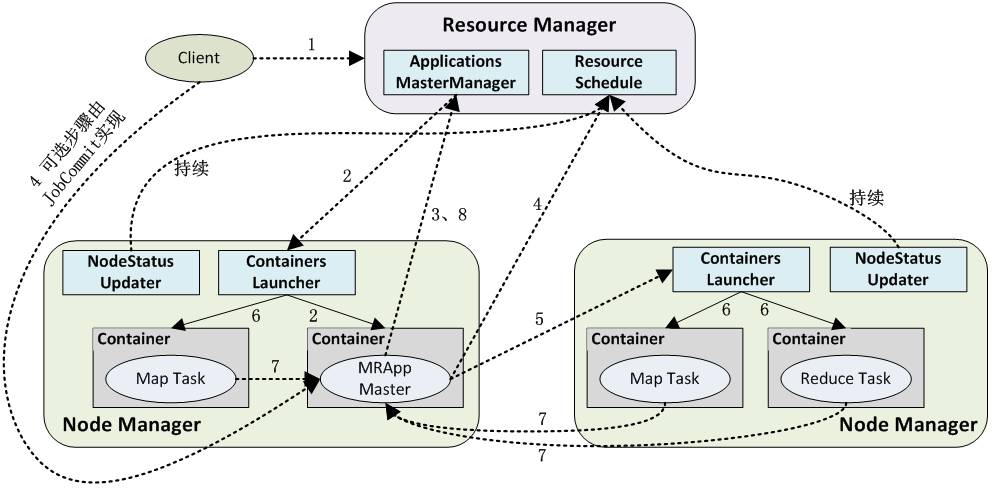
YARN应用工作流程图
1、用户向YARN中提交应用程序,其中包括AM程序、启动AM的命令、命令参数、用户程序等;事实上,需要准确描述运行ApplicationMaster的unix进程的所有信息。提交工作通常由YarnClient来完成。
2、RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container中启动AM;
3、AM首先向RM注册,这样用户可以直接通过RM査看应用程序的运行状态,运行状态通过 AMRMClientAsync.CallbackHandler的getProgress() 方法来传递给RM。 然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4〜7;
4、AM采用轮询的方式通过RPC协议向RM申请和领取资源;资源的协调通过 AMRMClientAsync异步完成,相应的处理方法封装在AMRMClientAsync.CallbackHandler中。
5、—旦AM申请到资源后,便与对应的NM通信,要求它启动任务;通常需要指定一个ContainerLaunchContext,提供Container启动时需要的信息。
6、NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
7、各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;ApplicationMaster与NM的通信通过NMClientAsync object来完成,容器的所有事件通过NMClientAsync.CallbackHandler来处理。例如启动、状态更新、停止等。
8、应用程序运行完成后,AM向RM注销并关闭自己。
对比mrv1和yarn,可以看出:ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
用自己的话说:1,首先理解AM与RM的区别,前者是申请资源和监控进程,监控各个NM的运行情况以方便报告给client,。后者是资源调度进程,指挥NM做什么工作。好比战场上的(监军和谋士合体)和指挥官。
2,一句话说YARN的工作流程:client提交jar到yarn,RM为jar分配container,并启动AM监控进程,AM不断的向RM申请资源和任务,各个NM向AM领取任务后执行,AM则实时监控NM执行的情况,最后将处理结果写到hdfs上。
小编这里又从网友上拷了一个另一份更详细的图:
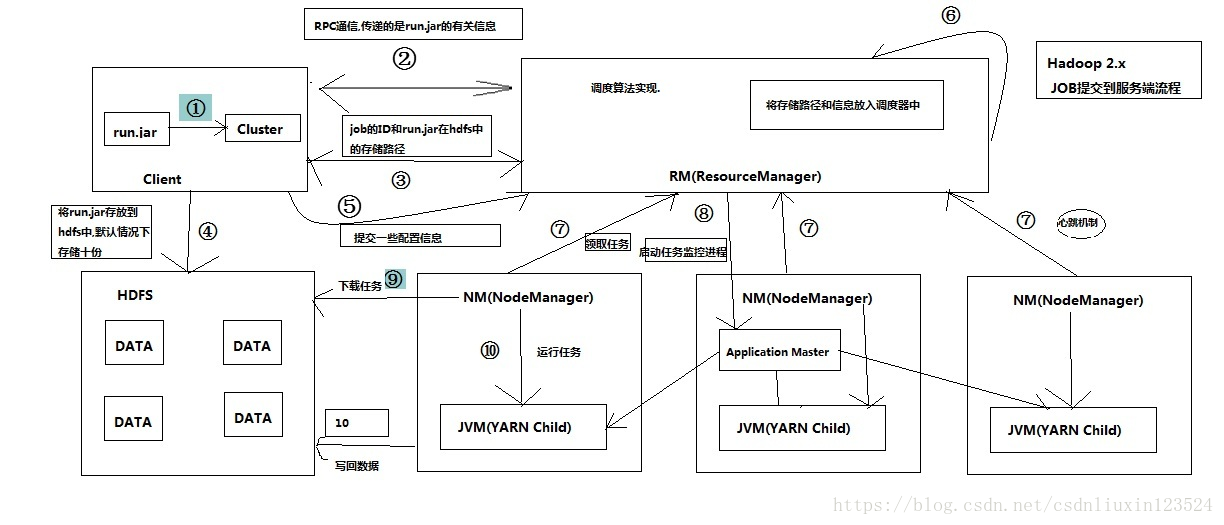
流程:
(1)客户端的Map Reduce程序通过hadoop shell提交到hadoop的集群中
(2)程序会通过RPC通信将打成jar包的程序的有关信息传递给Hadoop集群中RM(ResourceManager),可称为领取Job ID的过程
(3)RM将提交上来的任务分配一个唯一的ID,同时会将run.jar的在HDFS上的存储路径发送给客户端.
(4)客户端得到那个存储路径之后,会相应的拼接出最终的存放路径目录,然后将run.jar分多份存储在HDFS目录中,默认情况下备份数量为10份.可配置
(5)客户端提交一些配置信息,例如:最终存储路径,Job ID等给RM
(6)RM会将这些配置信息放入一个队列当中,供调度器调用.至于调度的算法,不必深究
(7)NM(NodeManager)和RM是通过心跳机制保持着通信的,NM会定期的向RM去领取任务
(8)RM会在任意的一台或多台的NM中,启动任务监控的进程Application Master.用来监控其他NM中YARN Child的执行的情况
(9)NM在领取到任务之后,得到信息,会去HDFS的下载run.jar.然后在本地的机器上启动YARN Child进程来执行map或者reduce函数.map函数的处理之后的中间结果数据会放在本地文件系统中的
(10)在结束程序之后,将结果数据写会HDFS中
一个Job从提交到执行的过程差不多如上所述。
YARN优势
1、YARN的设计减小了JobTracker的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全、更优美。
2、在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的AppMst,让更多类型的编程模型能够跑在Hadoop集群中。
3、对于资源的表示以内存为单位,比之前以剩余slot数目更加合理。
4、MRv1中JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在这个部分就扔给ApplicationMaster做了,
而ResourceManager中有一个模块叫做ApplicationManager,它是监测ApplicationMaster的运行状况,如果出问题,会在其他机器上重启。
5、Container用来作为YARN的一个资源隔离组件,可以用来对资源进行调度和控制。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106123.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
