大家好,又见面了,我是你们的朋友全栈君。
简介:
项目大致过程是:flume监控日志文件,定时把文件清洗后上传到hdfs上,上传清晰后的数据是格式化的,可被hive识别,然后hive创建表,写脚本,执行hql语句,把执行结果写到hdfs上,最后为了方便查看,把放在hdfs上的结果通过sqoop放在mysql中。
第一部分:项目分析
我们要做的小项目是关于黑马训练营的日志分析项目,用到的日志文件大家可以到:http://download.csdn.net/detail/u012453843/9680664这个地址下载。日志文件中的内容如下(仅拿出来两行内容),可以看到一共有5列,每列代表的意思是:第一列是IP,第二列是时间,第三列是请求资源路径,第四列是访问状态(200代表访问成功),第五列是本次访问产生的流量。
27.19.74.143 – – [30/May/2013:17:38:20 +0800] “GET /static/image/common/faq.gif HTTP/1.1” 200 1127
110.52.250.126 – – [30/May/2013:17:38:20 +0800] “GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1” 200 1292
上面的数据比较重要的数据是请求的资源路径,有了它我们就可以知道用户喜欢访问的资源是哪些,然后有针对性地对用户进行推销相关产品。
下面来说几个网站的关键指标。
第一个:浏览量PV
定义:页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录一次。
分析:网站总浏览量,可以考核用户对于网站的兴趣,就像收视率对于电视剧一样,但是对于网站运营者来说,更重要的是每个栏目下的浏览量。PV虽然重要但有可能水分比较大,比如我一个用户写个程序一天访问这个网站一千万次,这并不能代表这个网站就是成功的。
第二个:访客数UV(包括新访客数、新访客比例)
定义:访客数(UV)即唯一访客数,一天之内网站的独立访客数(以Cookie 为依据),一天内同一访客多次访问网站只计算1 个访客。
分析:在统计工具中,我们经常可以看到,独立访客和IP数的数据是不一样的,独立访客都多于IP数。那是因为,同一个IP地址下,可能有很多台电脑一同使用,这种情况,相信都很常见。
还有一种情况就是同一台电脑上,用户清空了缓存,使用360等工具,将cookie删除,这样一段时间后,用户再使用该电脑,进入网站,这样访问数UV也被重新加一。
当然,对于网站统计来说,关于访客数需要注意的另一个指标就是新访客数,新访客数据可以衡量,网站通过推广活动,所获得的用户数量。新访客对于总访客数的比值,可以看到网站吸引新鲜血液的能力,及如何保留旧有用户。
第三个:IP数
定义:一天之内,访问网站的不同独立IP个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。
分析:统计IP虽然不太好(因为现实中都是一个公网IP对应着多台电脑,所以从IP并不能知道具体有多少人访问)但是它依然有它的用处,由于它是我们最熟悉的一个概念,无论同一个IP上有多少电脑,或者其他用户,从某种程度上来说,独立IP的多少,是衡量网站推广活动好坏最直接的数据,我们还是可以从IP的数量来分析出那片区域访问的数量比较多,哪片访问的少,对于IP数量比较少的区域我们应该加大广告力度。
公式:对不同ip,计数
第四个:跳出率
定义:只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数/全部的访问次数汇总。
分析:跳出率是非常重要的访客黏性指标,它显示了访客对网站的兴趣程度:跳出率越低说明流量质量越好,访客对网站的内容越感兴趣,这些访客越可能是网站的有效用户、忠实用户。
该指标也可以衡量网络营销的效果,指出有多少访客被网络营销吸引到宣传产品页或网站上之后,又流失掉了,可以说就是煮熟的鸭子飞了。比如,网站在某媒体上打广告推广,分析从这个推广来源进入的访客指标,其跳出率可以反映出选择这个媒体是否合适,广告语的撰写是否优秀,以及网站入口页的设计是否用户体验良好。
公式:(1)统计一天内只出现一条记录的ip,称为跳出数
(2)跳出数/PV
第五个;板块热度排行榜
定义:版块的访问情况排行。
分析:巩固热点版块成绩,加强冷清版块建设。同时对学科建设也有影响。
公式:按访问次数、停留时间统计排序
第二部分:项目开发步骤
1.flume(采集数据)
2.对数据进行清洗(采用MapReduce对数据进行清洗)
3.使用hive进行数据的多维分析
4.把hive分析结果通过sqoop导出到mysql中
5.提供视图工具供用户使用
第三部分:实战
首先我们来删除我们hive以前创建的表(避免影响我们的结果),如下图所示,我们先到hive的bin目录,然后使用./hive来启动hive。
xiaoye@ubuntu:~$ ./hive/bin/hive
18/04/07 23:06:14 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
Logging initialized using configuration in jar:file:/home/xiaoye/hive/lib/hive-common-0.13.1-cdh5.2.0.jar!/hive-log4j.properties
hive> show tables;
OK
people
student
Time taken: 1.42 seconds, Fetched: 2 row(s)
hive> drop table people;
OK
Time taken: 3.937 seconds
hive> drop student;
hive> show tables;
OK
Time taken: 0.051 seconds
删除表之后我们来建表,如下所示,我们创建了一张分区表,是以logdate来作为分区条件,列分隔符为’\t’,创建的表在HDFS的位置是根目录下的cleaned(过滤完数据之后的目录)(注意要先启动hadoop集群)。
hive> create external table fmhsm(ip string,logtime string,url string)
> partitioned by (logdate string)
> row format delimited fields terminated by ‘\t’ location ‘/cleaned’;
OK
Time taken: 1.352 seconds
hive> show tables;
OK
fmhsm
Time taken: 0.07 seconds, Fetched: 1 row(s)
hive下是有我们新建的fmhsm表的。我们看看hdfs上有没有cleaned文件:

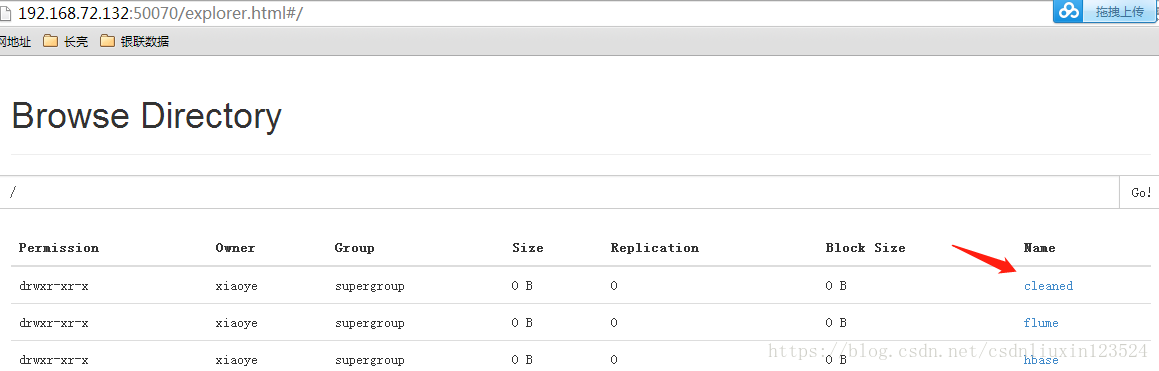
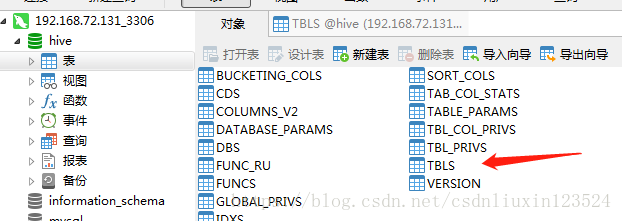
创建完一个hive表后,在元数据库中就有相应的信息了,如下所示
找到TBLS表,里面的tblname是表名,tblType是外部表

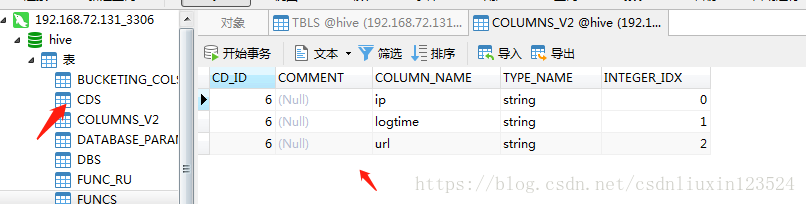
columns_v2是表字段信息:
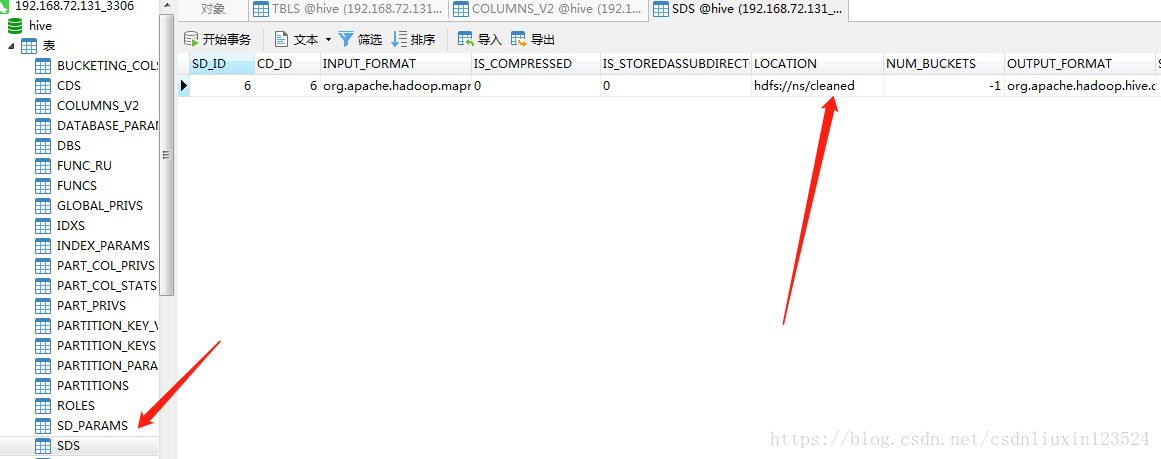
SDS表中有对应的hdfs存储地址:
现在我们来创建一个脚本文件,名叫daily.sh,如下所示
xiaoye@ubuntu:~$ vim daily.sh
xiaoye@ubuntu:~$ ls
apache-activemq-5.15.3 examples.desktop Music Templates
classes flume no Videos
daily.sh hadoop no.pub zookeeper
derby.log hbase Pictures zookeeper.out
Desktop hive product.java
Documents logs Public
Downloads metastore_db sqoop
下面我们修改下脚步的权限,让它成为可执行的脚本:
命令:chmod +x daily.sh
下面我们需要一个MapReduce程序来帮我们清洗一下数据,代码如下:
package com.mapreduce.clean;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import org.apache.commons.lang.ObjectUtils.Null;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.v2.LogParams;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.lf5.util.LogFileParser;
import com.mapreduce.clean.Cleaner.MyMapper.MyReducer;
/**
* * Cleaner类为何要继承Configured类呢?因为我们要使用Tool接口类,而Tool接口类继承了Configurable类,
* Configurable类有void setConf(Configuration conf);和Configuration
* getConf();两个接口需要实现
* 这就是说,如果我们直接继承Tool类,那么我们将不得不实现三个接口。但是我们的Configured类却已经帮我们实现了Configurable
* 类的两个接口,因此我们为了方便,继承Configurable类,仅实现Tool类的run方法就可以了。
*
* @author liuxin
* @date 2018年4月8日
*/
public class Cleaner extends Configured implements Tool{
/**
* 该方法是Tool接口类的一个接口,类似于一个线程,我们需要实现它的run方法。
*/
public int run(String[] arg0) throws Exception {
// 因为这是单独起的一个线程,因此变量必须是final类型的,第一个参数是输入路径,也就是我们的原始数据的路径
final String inputPath=arg0[0];
//第二个参数是输出路径,也就是清洗过的数据都会放在这里
final String outputPath=arg0[1];
//Job需要一个配置类,这里就new一个
final Configuration conf=new Configuration();
//得到一个作业实例
final Job job=Job.getInstance(conf);
//告诉job运行的是哪个类里的main方法
job.setJarByClass(Cleaner.class);
//把外界传来的原始数据的路径设置到job当中,从而job知道到哪里读取数据
FileInputFormat.setInputPaths(job, inputPath);
//把自己写的mapper类加载进来,
job.setMapperClass(MyMapper.class);
//指定输出的key(k2),我们清洗完数据后,其实还是一行一行的内容输出,因此输出的key还是行号
job.setMapOutputKeyClass(LongWritable.class);
//指定输出的vlaue(v2),清洗完数据后,数据依然是一行一行的文本,一次以text的格式输出
job.setMapOutputValueClass(Text.class);
//把自己写的Reduce类加进来
job.setReducerClass(MyReducer.class);
//指定k3的输出方式,也就是reduce处理完后将以什么样的方式来输出key,这里我们还是使用text
job.setOutputKeyClass(Text.class);
//指定v3的输出形式,也就是reduce处理完后,将以什么样的方式来输出,value,由于我们已经把清洗后的数据以text的格式输出了,其它我们已经不需要了,因此对于vlaue
//来说,我们传个null就行了
job.setOutputValueClass(NullWritable.class);
//告诉job清洗后的数据写到hdfs的那个目录下
FileOutputFormat.setOutputPath(job, new Path(outputPath));
//等待作业完成,指定参数true是指打印进度给用户看
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Cleaner(), args);
}
/**
* 自定义一个Mapper类,Mapper类的输入是<k1,v1>,输出是<k2,v2>
*/
static class MyMapper extends Mapper<LongWritable,Text,LongWritable,Text>{
//实例化一个转换类,
LogParser parser=new LogParser();
//之所以把v2放到map方法的外部是为了一次实例化多次调用,避免资源的浪费
Text v2=new Text();
protected void map(LongWritable key,Text value,Mapper<LongWritable,Text,LongWritable,Text>.Context context) {
//获取日志文件的第一行内容,(Value就是v1的值)
final String line=value.toString();
//将这一行内容经过转换类转换为一个数组
final String[] parsed=parser.parse(line);
//数组中第一个元素的值便是IP
final String ip=parsed[0];
//数组中第二个元素的值是log产生的时间
final String logtime=parsed[1];
//数组中第三个元素的值是url
String url=parsed[2];
//我们要过滤掉以”GET /static”或”GET /uc_server”开头的数据(我们姑且认为这两个开头的数据是坏数据)
if(url.startsWith(“GET /static”) || url.startsWith(“GET /uc_server”)){
return;
}
//如果是GET请求,我们截取”GET”和” HTTP/1.1″之间的数据,比如”GET /static/image/common/faq.gif HTTP/1.1″
//我们要得到的是”/static/image/common/faq.gif”
if(url.startsWith(“GET”)){
url=url.substring(“GET “.length()+1, url.length()-” HTTP/1.1″.length());
}
//如果是POST请求,我们截取”POST”和” HTTP/1.1″之间的数据,比如”POST /api/manyou/my.php HTTP/1.0″
//我们要得到的是”/api/manyou/my.php HTTP/1.0″
if(url.startsWith(“POST”)){
url=url.substring(“POST “.length()+1,url.length()-” HTTP/1.1″.length());
}
//v2的输出格式是:ip,logtime,url
v2.set(ip+”\t”+logtime+”\t”+url);
//k2和k1一样,都是数值型
try {
context.write(key, v2);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 自定义一个Reducer类,输入是<k2,v2>,输出是<k3,v3>
* @author wanghaijie
*
*/
static class MyReducer extends Reducer<LongWritable,Text,Text,NullWritable>{
protected void reduce(LongWritable k2,Iterable<Text> v2s,Reducer<LongWritable,Text, Text, NullWritable>.Context context) {
//Reducer要做的工作其实非常简单,就是把<k2,v2>的v2的值给输出出去,k3的类型是Text,v3其实是多余的,那么我们用Null来表示。序列化形式的
//Null是NullWritable.get()
for(Text v2:v2s){
try {
context.write(v2, NullWritable.get());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
再创建一个解析日志的类,用来分割提取我们需要的字段数据
package com.mapreduce.clean;
import java.text.Format;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import junit.awtui.Logo;
/**
*
* @author liuxin
* @date 2018年4月8日
*/
public class LogParser {
//第一个FORMAT用来匹配日志文件中的英文时间,英文时间是[30/May/2013:17:38:20 +0800]这种格式的
public static final SimpleDateFormat format=new SimpleDateFormat(“d/MMM/yyyy:HH:mm:ss”,Locale.ENGLISH);
//第二个FORMAT是我们要把时间转换成的格式,如20130530173820
public static final SimpleDateFormat DATEFORMAT=new SimpleDateFormat(“yyyyMMddHHmmss”);
public static void main(String[] args){
final String s1=”27.19.72.132–[30/May/2013:17:38:20+0800]\”GET/static/image/common/faq.gif HTTP/1.1\”200 1127″;
LogParser parser=new LogParser();
final String[] array=parser.parse(s1);
for(String a : array){
System.out.println(a);
}
}
/**
* 解析日志的行记录
* @param line
* @return 数组含有5个元素,分别是ip、时间、url、状态、流量
*/
public String[] parse(String line){
String ip=parseIP(line);//提取ip
String time;
time=parseTime(line);//提取时间
String url;
url=parseURL(line);//提取url
String status =parseStatus(line);//提取状态
String traffic=parseTraffic(line);//提取流量
return new String[]
{ip,time,url,status,traffic };
}
/**
* 获取本次浏览所消耗的流量
* 字符串中关于流量的信息如:”GET /static/image/common/faq.gif HTTP/1.1″ 200 1127
* 我们要得到的是1127,为了得到它,我们从最后一个”\”后的空格开始,截取到最后,然后去掉两端的空格,就剩”200 1127″
* 然后我们把”200 1127″以空格为分隔符,数组的第二个元素的值就是”1127″
* @param line
* @return
*/
private String parseTraffic(String line) {
final String trim=line.substring(line.lastIndexOf(“\””)+1).trim();
String traffic =trim.split(” “)[1];
return traffic;
}
/**
* 截取访问结果Status
* 字符串中关于Status的信息如:”GET /static/image/common/faq.gif HTTP/1.1″ 200 1127
* 我们要得到的是200,为了得到它,我们从最后一个”\”后的空格开始,截取到最后,然后去掉两端的空格,就剩”200 1127″
* 然后我们把”200 1127″以空格为分隔符,数组的第一个元素的值就是”200″
* @param line
* @return
*/
private String parseStatus(String line) {
// TODO Auto-generated method stub
final String trim=line.substring(line.lastIndexOf(“\””)+1).trim();
String status=trim.split(” “)[0];
return status;
}
/**
* 截取字符串中的URL
* 字符串中关于URL的信息如:”GET /static/image/common/faq.gif HTTP/1.1″
* 我们截取的话当然应该从”\”的下一个字母开始,到下一个”\”结束(字符串截取包括前面,不包括后面)
* @param line
* @return
*/
private String parseURL(String line) {
// TODO Auto-generated method stub
final int first=line.indexOf(“\””);
final int last=line.lastIndexOf(“\””);
String url=line.substring(first+1,last);
return url;
}
/**
* 将英文时间转变为如:20130530135026这样形式的时间
* 字符串中关于时间的信息如: [30/May/2013:17:38:20 +0800] ,我们截取其中的时间,截取的开始位置是”[“后面的”3″,
* 结束的位置是”+0800″,然后去掉前后的空格就是我们想要的英文时间”30/May/2013:17:38:20″
* 有了英文时间,我们便使用FORMAT.parse方法将time转换为时间,然后使用DATEFORMAT.format方法将时间转换为我们想要的”20130530173820″
* @param line
* @return
*/
private String parseTime(String line) {
// TODO Auto-generated method stub
final int first=line.indexOf(“[“);
final int last=line.indexOf(“+0800]”);
String time=line.substring(first+1, last).trim();
try {
String timeFormat=DATEFORMAT.format(format.parse(time));
return timeFormat;
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
/**
* 截取字符串中的IP 字符串如:27.19.74.143 – – [30/May/2013:17:38:20 +0800]
* 我们以”- -“为分割符,数组的第一个值便是IP的值
* @param line
* @return
*/
private String parseIP(String line) {
// TODO Auto-generated method stub
String ip=line.split(“–“)[0].trim();
return ip;
}
}
下面我们把MapReduce类所在的工程打成jar包,为了更方便的调用main方法,我在打包的过程中指定一下jar包的main方法入口,打包的过程如下图所示。
右键工程,选择java–>JAR file
下一步:
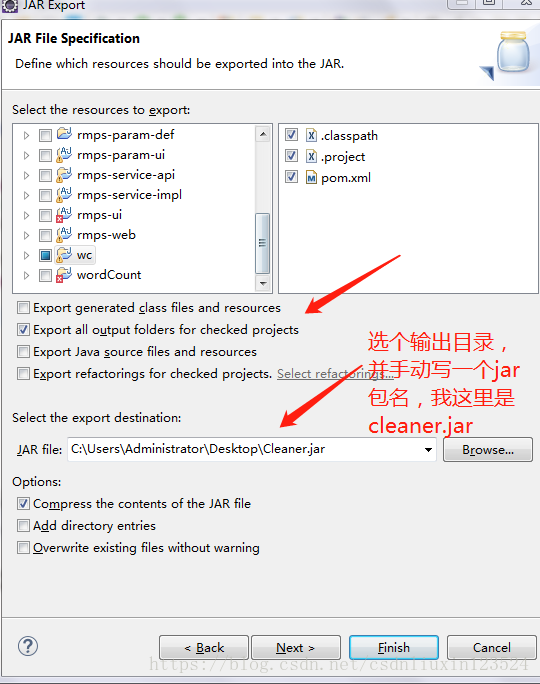
下一步:
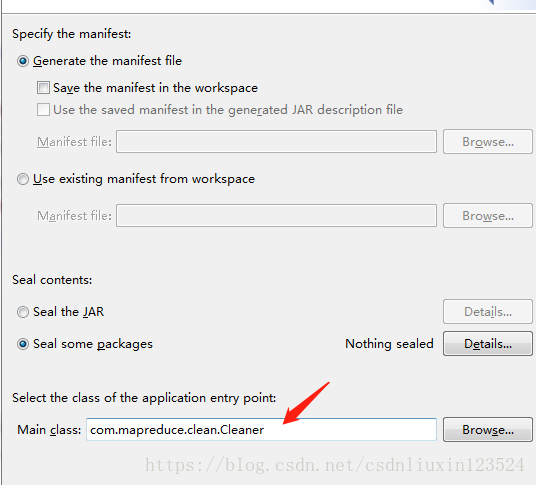
选择cleaner类
finish
在桌面上就有这样一个jar包了
把jar包上传到ubuntu上,
上传之后我们再把我们开始下载的日志通过flume采集到hdfs上。步骤如下:
先启动hadoop集群,再开启flume ,可参照小编的上一篇博文
xiaoye@ubuntu:~$ ./flume/bin/flume-ng agent -n a4 -c conf -f conf/a3/conf -Dflume.root.logger=INFO,console
执行这个命令后,我上传日志到,如下目录下:

上传的同时,flume控制台也有响应日志打印。结束后,在hdfs会有响应文件。如下,大小也是五十多兆。这里上传需要一定时间,要等到events-开头的文件后缀没有tmp结尾才算上传完毕。

但是看上面的图好像flume把文件分割成多个文件了,这样一开始我没有注意,依旧运行了mapreduce程序,结果报错了,出现java程序下标溢出。看元数据也没有脏数据啊。想了半天可能是文件被flume分割时处出现了问题,所以这里我们改一下配置:
xiaoye@ubuntu:~/flume/conf$ vim a4.conf

这里原来是60秒生产一个文件,现在改成360秒试试。
(注:flume监控日志不能从本机上的其他文件mv过去。因为mv只修改了文件的储存路径,并没有传输数据的过程)
再次执行,结果就只有一个文件了,不过用时比较长,要耐心等待,知道tmp后缀消失:

好,有了jar包和原数据,下面我们便来测试一下jar包是否真的管用。执行信息如下所示,由于我们在打包的时候已经指定了Cleaner.jar的main入口方法,因此我们这里不需要指定main了,只需要指定原始数据所在的目录以及要将清理后的数据放到哪个目录下,这里我们的原始数据在/flume/20180408目录下,清理后的数据我们也放到flume目录下,起名为out1112。
上传jar包到主目录下:
xiaoye@ubuntu:~$ rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring Cleaner.jar…
100% 15 KB 15 KB/sec 00:00:01 0 Errors
开始测试了:
命令:xiaoye@ubuntu:~$ ./hadoop/bin/hadoop jar Cleaner.jar /flume/20180409/events-.1523259787334 /flume/out040904
执行完成后我们看看hdfs有没有生成输出文件,

是有的,打开文件看看是不是ip,时间,路径的数据格式;
下面我们来用脚本调用Cleaner.jar,我们需要定义一个时间变量,定义变量的好处是以后就不用手动改变它了,每隔一段时间它会自动执行,我们定义的时间变量名是CURRENT,如下所示,其中echo $CURRENT只是用来测试该时间变量是否可用。%y显示的是2016的后两位16,%Y则显示的是全部。
xiaoye@ubuntu:~$ vim daily.sh
CURRENT=`date +%Y%m%d`
echo $CURRENT
测试:
xiaoye@ubuntu:~$ ./daily.sh
20180409
那么假如我们想要显示昨天的日期的话,可以这样来写,如下所示:
CURRENT=`date -d “1 day ago” +%Y%m%d`
echo $CURRENT
xiaoye@ubuntu:~$ ./daily.sh
20180408
OK,没问题;
下面我们做一个执行脚本会自动执行mapreduce任务。
xiaoye@ubuntu:~$ vim daily.sh
#CURRENT=`date -d “1 day ago” +%Y%m%d`
CURRENT=`date +%Y%m%d`
#echo $CURRENT
/home/xiaoye/hadoop/bin/hadoop jar /home/xiaoye/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
注意上面所有的路径都是绝对路径。日期就选择当天吧,不过前天是hdfs上有flume传上去的当天的文件,即:
然后执行脚本:
xiaoye@ubuntu:~$ ./daily.sh
就开始执行mapreduce任务了。
结束后在hdfs会有结果文件:

虽然这时cleaned目录下已经有数据了,那么我们这时如果去查询hive表fmhsm的话,是查询不到数据的,如下所示。这是为什么呢?因为我们建fmhsm表的时候建的是分区表,意味着我们必须查询到具体的某个分区才能查到数据。现在我们用mapreduce在HDFS的cleaned的目录下生成一个以时间命名的目录,但是并没有通知hive,因此hive是不知道有这个表的存在的。
那么我们怎么通知hive呢?我们采用命令行的方式来通知hive。hive为我们提供了一种机制,让我们可以不进入hive命令行模式就可以使用hive表的相关命令。我们先举个例子,如下所示,发现确实帮我们查询出了hive表信息,要知道我们可是在普通模式下执行的,并没有进入到hive命令行模式(不过我们要在hive的bin目录下执行该命令,如果配置了hive的环境变量的话,在任何目录下都可以执行该命令)。
我这里配置了环境变量就直接执行了。
xiaoye@ubuntu:~$ hive -e “show tables”
18/04/09 02:05:31 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
Logging initialized using configuration in jar:file:/home/xiaoye/hive/lib/hive-common-0.13.1-cdh5.2.0.jar!/hive-log4j.properties
OK
fmhsm
Time taken: 1.849 seconds, Fetched: 1 row(s)
可以看到有fmhsm表:
下面我们来在我们的脚本中来执行hive表相关的命令来给fmhsm表添加一个具体的分区,为了排查问题方便,我们一个脚本命令一个脚本命令的来测试,把所有的脚本命令都测试成功之后,我们可以一起执行所有命令。现在我们先把第一个脚本命令注释掉(注释用”#”),添加第二个脚本命令(该命令是将数据加入到我们的hive表fmhsm当中),如下所示。
脚本内容如下:
xiaoye@ubuntu:~$ cat daily.sh
#CURRENT=`date -d "1 day ago" +%Y%m%d`
CURRENT=`date +%Y%m%d`
#echo $CURRENT
#/home/xiaoye/hadoop/bin/hadoop jar /home/xiaoye/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
/home/xiaoye/hive/bin/hive -e "alter table fmhsm add partition (logdate='$CURRENT') location '/cleaned/$CURRENT'"执行脚本
xiaoye@ubuntu:~$ ./daily.sh
18/04/09 02:43:59 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
Logging initialized using configuration in jar:file:/home/xiaoye/hive/lib/hive-common-0.13.1-cdh5.2.0.jar!/hive-log4j.properties
FAILED: SemanticException Partition spec {logdata=20180409} contains non-partition columns
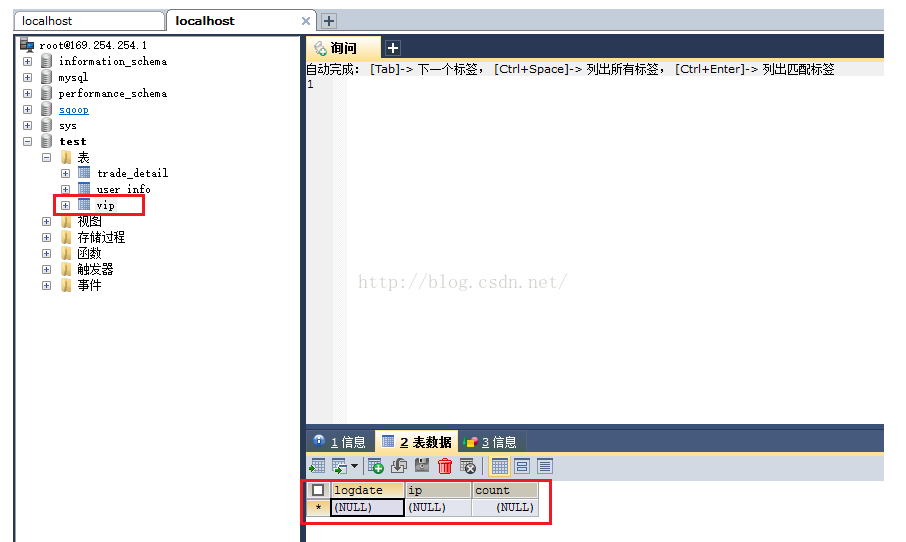
没有问题的话,我们就查询出前十条数据:
xiaoye@ubuntu:~$ hive -e "select * from fmhsm limit 10";
18/04/09 03:16:19 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead
Logging initialized using configuration in jar:file:/home/xiaoye/hive/lib/hive-common-0.13.1-cdh5.2.0.jar!/hive-log4j.properties
OK
110.52.250.126 - - [30/May/2013:17:38:20 +0800] "GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1" 200 1292 20130530173820 data/cache/style_1_widthauto.css?y720180409
110.52.250.126 - - [30/May/2013:17:38:20 +0800] "GET /source/plugin/wsh_wx/img/wsh_zk.css HTTP/1.1" 200 1482 20130530173820 source/plugin/wsh_wx/img/wsh_zk.css20180409那么,我们为什么可以查询到数据呢?因为我们刚才在元数据表中增加了一个分区,如下图所示,我们用hive命令查询数据,它会先去元数据库的相关表中去查询该表在HDFS上分区所在的位置,然后再去HDFS相应的分区目录下查询出数据。

下面我们来学习第三条脚本命令,该命令用来查询访问该网站的PV值(PV是指访问该网站的所有点击量之和),命令如下内容。
#CURRENT=`date -d "1 day ago" +%Y%m%d`
CURRENT=`date +%Y%m%d`
#echo $CURRENT
#/home/xiaoye/hadoop/bin/hadoop jar /home/xiaoye/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/home/xiaoye/hive/bin/hive -e "alter table fmhsm add partition (logdate='$CURRENT') location '/cleaned/$CURRENT'"
/home/xiaoye/hive/bin/hive -e "select count(*) from fmhsm where logdate=$CURRENT"执行脚本,程序开始计算数量了;
最后会有结果:
Total MapReduce CPU Time Spent: 32 seconds 140 msec
OK
169859
上面我们只是查询出了PV的值,但我们并没有保存起来,我们现在来把查询出来的数据保存到一张表当中,我们同样在daily.sh来写脚本运行
如下:
#CURRENT=`date -d "1 day ago" +%Y%m%d`
CURRENT=`date +%Y%m%d`
#echo $CURRENT
#/home/xiaoye/hadoop/bin/hadoop jar /home/xiaoye/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/home/xiaoye/hive/bin/hive -e "alter table fmhsm add partition (logdate='$CURRENT') location '/cleaned/$CURRENT'"
#/home/xiaoye/hive/bin/hive -e "select count(*) from fmhsm where logdate=$CURRENT"
/home/xiaoye/hive/bin/hive -e "create table pv_$CURRENT row format delimited fields terminated by '\t' as select count(*) from fmhsm where logdate=$CURRENT"xiaoye@ubuntu:~$ ./daily.sh
执行完脚本之后,我们来查询一下hive表都有哪些,如下所示,发现多了一张pv_20161109表
[root@itcast03 ~]# hive -e “show tables;”;
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 00:26:30 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
hmbbs
pv_20161109
Time taken: 0.661 seconds, Fetched: 3 row(s)
下面我们来查询一下pv_20161109这张表中的数据,如下所示,发现存储着我们的PV值:169859
[root@itcast03 ~]# hive -e “select * from pv_20161109”;
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 00:27:11 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
169859
Time taken: 0.999 seconds, Fetched: 1 row(s)
[root@itcast03 ~]#
下面我们来查询浏览次数最多的前20名客户(VIP客户),我们还在我们的daily.sh脚本中写shell命令,如下,需要说明的是,在sql语句中一般情况下如果用group函数的话,查询的内容最多是group分组的字段以及count函数,但是常量除外,也就是说,我们可以在select 语句之后加任意的常量值,我们这里便把变量$CURRENT加到了select语句当中。
[root@itcast03 ~]# vim daily.sh
CURRENT=`date -d “4 day ago” +%Y%m%d`
#/itcast/hadoop-2.2.0/bin/hadoop jar /root/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “alter table hmbbs add partition (logdate=$CURRENT) location ‘/cleaned/$CURRENT'”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table pv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(*) from hmbbs where logdate=$CURRENT”
/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table vip_$CURRENT row format delimited fields terminated by ‘\t’ as select $CURRENT,ip,count(*) as hits from hmbbs where logdate=$CURRENT group by ip having hits>20 order by hits desc limit 20”
下面我们来执行脚本,如下所示。
[root@itcast03 ~]# ./daily.sh
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 00:53:22 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478920720232_0014, Tracking URL = http://itcast03:8088/proxy/application_1478920720232_0014/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478920720232_0014
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-13 00:53:37,402 Stage-1 map = 0%, reduce = 0%
2016-11-13 00:53:43,755 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.32 sec
2016-11-13 00:53:51,120 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.97 sec
MapReduce Total cumulative CPU time: 4 seconds 970 msec
Ended Job = job_1478920720232_0014
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478920720232_0015, Tracking URL = http://itcast03:8088/proxy/application_1478920720232_0015/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478920720232_0015
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2016-11-13 00:53:59,723 Stage-2 map = 0%, reduce = 0%
2016-11-13 00:54:06,019 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 1.34 sec
2016-11-13 00:54:12,282 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 2.5 sec
MapReduce Total cumulative CPU time: 2 seconds 500 msec
Ended Job = job_1478920720232_0015
Moving data to: hdfs://ns1/user/hive/warehouse/vip_20161109
Table default.vip_20161109 stats: [numFiles=1, numRows=20, totalSize=553, rawDataSize=533]
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.97 sec HDFS Read: 12756871 HDFS Write: 60477 SUCCESS
Job 1: Map: 1 Reduce: 1 Cumulative CPU: 2.5 sec HDFS Read: 60829 HDFS Write: 630 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 470 msec
OK
Time taken: 47.862 seconds
执行完脚本之后,我们查询一下hive所有的表,如下所示,可以看到有一张vip_20161109表
[root@itcast03 ~]# hive -e “show tables;”;
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 00:54:31 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
hmbbs
pv_20161109
vip_20161109
Time taken: 0.582 seconds, Fetched: 4 row(s)
下面我们来查看一下vip这张表。
[root@itcast03 ~]# hive -e “select * from vip_20161109”;
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 00:55:09 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
20161109 61.50.141.7 4855
20161109 222.133.189.179 3942
20161109 60.10.5.65 1889
20161109 220.181.89.156 1877
20161109 123.147.245.79 1571
20161109 61.135.249.210 1378
20161109 49.72.74.77 1160
20161109 180.173.113.181 969
20161109 122.70.237.247 805
20161109 125.45.155.27 735
20161109 173.199.114.195 672
20161109 221.221.153.8 632
20161109 119.255.57.50 575
20161109 139.227.126.111 575
20161109 157.56.93.85 561
20161109 222.141.54.75 533
20161109 58.63.138.37 520
20161109 123.126.50.182 512
20161109 61.135.249.206 508
20161109 222.36.188.206 503
Time taken: 1.056 seconds, Fetched: 20 row(s)
[root@itcast03 ~]#
下面我们来查询一下UV的值,就是每个IP一天内无论浏览多少次网站都只算一次,如下所示。
[root@itcast03 ~]# vim daily.sh
CURRENT=`date -d “4 day ago” +%Y%m%d`
#/itcast/hadoop-2.2.0/bin/hadoop jar /root/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “alter table hmbbs add partition (logdate=$CURRENT) location ‘/cleaned/$CURRENT'”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table pv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(*) from hmbbs where logdate=$CURRENT”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table vip_$CURRENT row format delimited fields terminated by ‘\t’ as select $CURRENT,ip,count(*) as hits from hmbbs where logdate=$CURRENT group by ip having hits>20 order by hits desc limit 20”
/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table uv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(distinct ip) from hmbbs where logdate=$CURRENT”
下面我们来执行daily.sh,如下所示。
[root@itcast03 ~]# ./daily.sh
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 01:08:59 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478920720232_0016, Tracking URL = http://itcast03:8088/proxy/application_1478920720232_0016/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478920720232_0016
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-13 01:09:12,694 Stage-1 map = 0%, reduce = 0%
2016-11-13 01:09:19,008 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.41 sec
2016-11-13 01:09:25,294 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.9 sec
MapReduce Total cumulative CPU time: 4 seconds 900 msec
Ended Job = job_1478920720232_0016
Moving data to: hdfs://ns1/user/hive/warehouse/uv_20161109
Table default.uv_20161109 stats: [numFiles=1, numRows=1, totalSize=6, rawDataSize=5]
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 4.9 sec HDFS Read: 12756871 HDFS Write: 81 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 900 msec
OK
Time taken: 24.247 seconds
执行完脚本之后,我们来查看一下hive现在都有哪些表,发现确实多了一张uv_20161109表。
[root@itcast03 ~]# hive -e “show tables”;
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 01:09:44 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
hmbbs
pv_20161109
uv_20161109
vip_20161109
Time taken: 0.588 seconds, Fetched: 5 row(s)
接着我们来查询一下uv_20161109这张表中的数据,如下所示,发现UV的值是:10413
[root@itcast03 ~]# hive -e “select * from uv_20161109”;
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 01:10:10 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
OK
10413
Time taken: 0.956 seconds, Fetched: 1 row(s)
下面我们来查询一下每天注册的用户数量,我们依然在daily.sh脚本中输入命令(注意:我这里没有把每天的用户注册数量写到某张表里面,而只是查询而已),如下所示。
[root@itcast03 ~]# vim daily.sh
CURRENT=`date -d “4 day ago” +%Y%m%d`
#/itcast/hadoop-2.2.0/bin/hadoop jar /root/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “alter table hmbbs add partition (logdate=$CURRENT) location ‘/cleaned/$CURRENT'”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table pv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(*) from hmbbs where logdate=$CURRENT”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table vip_$CURRENT row format delimited fields terminated by ‘\t’ as select $CURRENT,ip,count(*) as hits from hmbbs where logdate=$CURRENT group by ip having hits>20 order by hits desc limit 20”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table uv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(distinct ip) from hmbbs where logdate=$CURRENT”
/itcast/apache-hive-0.13.0-bin/bin/hive -e “select count(*) from hmbbs where logdate=$CURRENT and instr(url,’member.php?mod=register’)>0”
下面我们来执行daily.sh脚本,可以看到查询出来的结果是28人。
[root@itcast03 ~]# ./daily.sh
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/11/13 01:22:28 INFO Configuration.deprecation: mapred.committer.job.setup.cleanup.needed is deprecated. Instead, use mapreduce.job.committer.setup.cleanup.needed
Logging initialized using configuration in jar:file:/itcast/apache-hive-0.13.0-bin/lib/hive-common-0.13.0.jar!/hive-log4j.properties
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1478920720232_0017, Tracking URL = http://itcast03:8088/proxy/application_1478920720232_0017/
Kill Command = /itcast/hadoop-2.2.0/bin/hadoop job -kill job_1478920720232_0017
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-11-13 01:22:41,748 Stage-1 map = 0%, reduce = 0%
2016-11-13 01:22:48,155 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.23 sec
2016-11-13 01:22:54,417 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.41 sec
MapReduce Total cumulative CPU time: 3 seconds 410 msec
Ended Job = job_1478920720232_0017
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 3.41 sec HDFS Read: 12756871 HDFS Write: 3 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 410 msec
OK
28
Time taken: 22.633 seconds, Fetched: 1 row(s)
[root@itcast03 ~]#
最后我们把我们刚才查询出来的浏览网站次数最多的前20名的信息导出到数据库表中。首先我们在我们的关系型数据库中新建一张vip表,如下图所示。
然后我们把HDFS上的VIP表中的信息导出来,VIP表在HDFS的位置如下图所示。
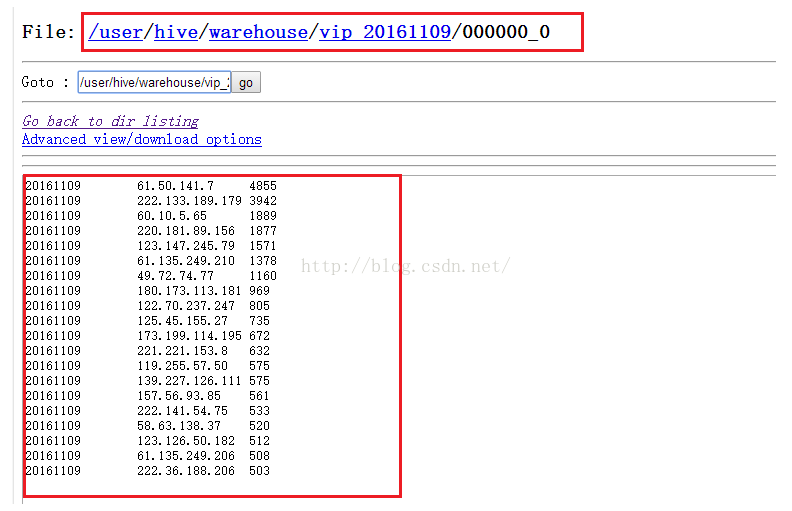
我们依然在daily.sh脚本中执行sqoop相关的shell命令,这里需要注意的是,命令中/user/hive/warehouse/vip_$CURRENT要用双引号来包含,而不能用单引号,否则$CURRENT无法解析。
[root@itcast03 ~]# vim daily.sh
CURRENT=`date -d “4 day ago” +%Y%m%d`
#/itcast/hadoop-2.2.0/bin/hadoop jar /root/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “alter table hmbbs add partition (logdate=$CURRENT) location ‘/cleaned/$CURRENT'”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table pv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(*) from hmbbs where logdate=$CURRENT”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table vip_$CURRENT row format delimited fields terminated by ‘\t’ as select $CURRENT,ip,count(*) as hits from hmbbs where logdate=$CURRENT group by ip having hits>20 order by hits desc limit 20”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “create table uv_$CURRENT row format delimited fields terminated by ‘\t’ as select count(distinct ip) from hmbbs where logdate=$CURRENT”
#/itcast/apache-hive-0.13.0-bin/bin/hive -e “select count(*) from hmbbs where logdate=$CURRENT and instr(url,’member.php?mod=register’)>0”
/itcast/sqoop-1.4.6/bin/sqoop export –connect jdbc:mysql://169.254.254.1:3306/test –username root –password root –export-dir “/user/hive/warehouse/vip_$CURRENT” –table vip –fields-terminated-by ‘\t’
下面我们来执行daily.sh脚本,如下所示,执行成功。
[root@itcast03 ~]# ./daily.sh
Warning: /itcast/sqoop-1.4.6/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /itcast/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /itcast/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /itcast/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
16/11/13 01:47:25 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
16/11/13 01:47:25 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
16/11/13 01:47:25 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
16/11/13 01:47:25 INFO tool.CodeGenTool: Beginning code generation
Sun Nov 13 01:47:25 CST 2016 WARN: Establishing SSL connection without server’s identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn’t set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to ‘false’. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification.
16/11/13 01:47:25 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `vip` AS t LIMIT 1
16/11/13 01:47:26 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `vip` AS t LIMIT 1
16/11/13 01:47:26 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /itcast/hadoop-2.2.0
Note: /tmp/sqoop-root/compile/3307c34445798be97edc02e8d0d14b08/vip.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
16/11/13 01:47:27 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/3307c34445798be97edc02e8d0d14b08/vip.jar
16/11/13 01:47:27 INFO mapreduce.ExportJobBase: Beginning export of vip
16/11/13 01:47:27 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
16/11/13 01:47:28 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
16/11/13 01:47:28 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
16/11/13 01:47:28 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
16/11/13 01:47:28 INFO client.RMProxy: Connecting to ResourceManager at itcast03/169.254.254.30:8032
16/11/13 01:47:31 INFO input.FileInputFormat: Total input paths to process : 1
16/11/13 01:47:31 INFO input.FileInputFormat: Total input paths to process : 1
16/11/13 01:47:31 INFO mapreduce.JobSubmitter: number of splits:4
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.job.classpath.files is deprecated. Instead, use mapreduce.job.classpath.files
16/11/13 01:47:31 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.cache.files.filesizes is deprecated. Instead, use mapreduce.job.cache.files.filesizes
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.cache.files is deprecated. Instead, use mapreduce.job.cache.files
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.mapoutput.value.class is deprecated. Instead, use mapreduce.map.output.value.class
16/11/13 01:47:31 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
16/11/13 01:47:31 INFO Configuration.deprecation: mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
16/11/13 01:47:31 INFO Configuration.deprecation: mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.cache.files.timestamps is deprecated. Instead, use mapreduce.job.cache.files.timestamps
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.mapoutput.key.class is deprecated. Instead, use mapreduce.map.output.key.class
16/11/13 01:47:31 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
16/11/13 01:47:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1478920720232_0019
16/11/13 01:47:32 INFO impl.YarnClientImpl: Submitted application application_1478920720232_0019 to ResourceManager at itcast03/169.254.254.30:8032
16/11/13 01:47:32 INFO mapreduce.Job: The url to track the job: http://itcast03:8088/proxy/application_1478920720232_0019/
16/11/13 01:47:32 INFO mapreduce.Job: Running job: job_1478920720232_0019
16/11/13 01:47:38 INFO mapreduce.Job: Job job_1478920720232_0019 running in uber mode : false
16/11/13 01:47:38 INFO mapreduce.Job: map 0% reduce 0%
16/11/13 01:47:52 INFO mapreduce.Job: map 100% reduce 0%
16/11/13 01:47:54 INFO mapreduce.Job: Job job_1478920720232_0019 completed successfully
16/11/13 01:47:55 INFO mapreduce.Job: Counters: 27
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=413456
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2070
HDFS: Number of bytes written=0
HDFS: Number of read operations=19
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Job Counters
Launched map tasks=4
Rack-local map tasks=4
Total time spent by all maps in occupied slots (ms)=48728
Total time spent by all reduces in occupied slots (ms)=0
Map-Reduce Framework
Map input records=20
Map output records=20
Input split bytes=601
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=234
CPU time spent (ms)=3470
Physical memory (bytes) snapshot=371515392
Virtual memory (bytes) snapshot=3365302272
Total committed heap usage (bytes)=62390272
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
16/11/13 01:47:55 INFO mapreduce.ExportJobBase: Transferred 2.0215 KB in 26.7272 seconds (77.4492 bytes/sec)
16/11/13 01:47:55 INFO mapreduce.ExportJobBase: Exported 20 records
执行成功后我们再到我们的关系型数据库的vip表中看看数据有没有被导入进来,如下图所示,发现数据已经被成功导入进来了!!!
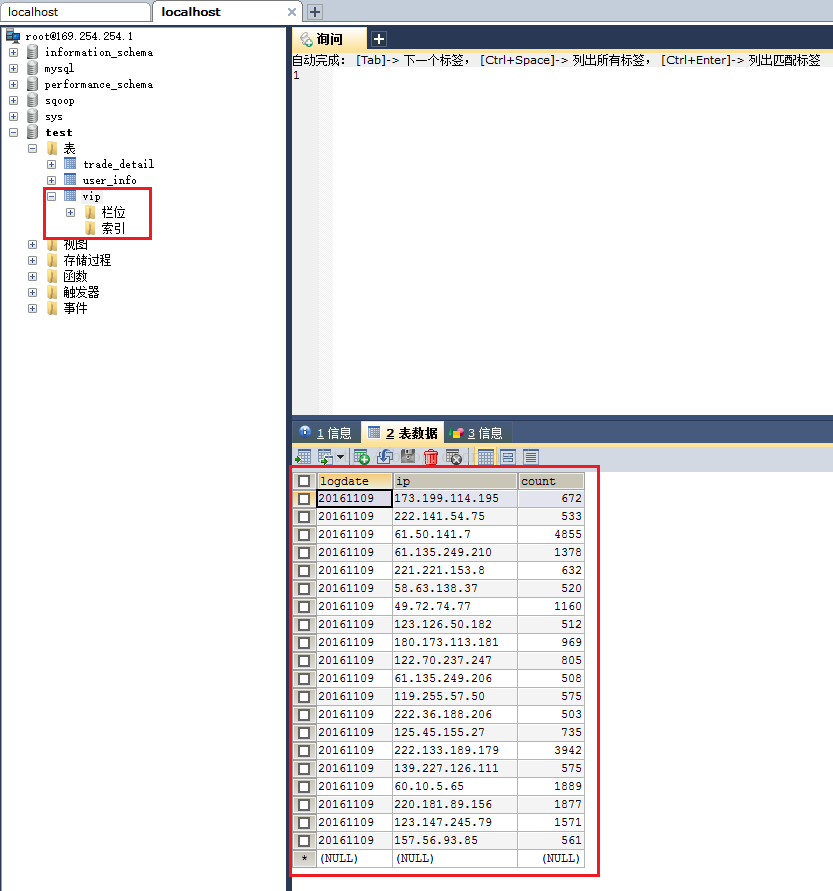
脚本:
CURRENT=`date -d "1 day ago" +%Y%m%d`
#CURRENT=`date +%Y%m%d`
#echo $CURRENT
#/home/xiaoye/hadoop/bin/hadoop jar /home/xiaoye/Cleaner.jar /flume/$CURRENT /cleaned/$CURRENT
#/home/xiaoye/hive/bin/hive -e "alter table fmhsm add partition (logdate='$CURRENT') location '/cleaned/$CURRENT'"
#/home/xiaoye/hive/bin/hive -e "select count(*) from fmhsm where logdate=$CURRENT"
#/home/xiaoye/hive/bin/hive -e "create table if not exists pv_$CURRENT row format delimited fields terminated by '\t' as select count(*) from fmhsm where logdate=$CURRENT"
#/home/xiaoye/hive/bin/hive -e "create table if not exists vip_$CURRENT row format delimited fields terminated by '\t' as select $CURRENT,ip,count(*) as hits from fmhsm where logdate=$CURRENT group by ip having hits>20 order by hits desc limit 20"
#/home/xiaoye/hive/bin/hive -e "create table if not exists uv_$CURRENT row format delimited fields terminated by '\t' as select count(distinct ip) from fmhsm where logdate=$CURRENT"
/home/xiaoye/hive/bin/hive -e "select count(*) fmhsm where logdate=$CURRENT and instr(url,'member.php?mod=register')>0"
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106115.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
