大家好,又见面了,我是你们的朋友全栈君。
1.1下载spark
地址:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.0/

1.2上传解压;
xiaoye@ubuntu:~/Downloads$ ls
apache-activemq-5.15.3-bin.tar.gz hive-0.13.1-cdh5.2.0.tar.gz
flume-ng-1.6.0-cdh5.10.1.tar.gz spark-2.3.0-bin-hadoop2.7.tgz
hadoop-2.5.0-cdh5.2.0.tar.gz zookeeper-3.4.5-cdh5.10.2.tar.gz
xiaoye@ubuntu:~/Downloads$ tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C ../
1.3为安装包建立一个软连接:
xiaoye@ubuntu:~$ ln -s spark-2.3.0-bin-hadoop2.7/ spark
1.4进入spark/conf修改配置文件
xiaoye@ubuntu:~$ cd spark
xiaoye@ubuntu:~/spark$ cd conf
xiaoye@ubuntu:~/spark/conf$ ls
docker.properties.template metrics.properties.template spark-env.sh.template
fairscheduler.xml.template slaves.template
log4j.properties.template spark-defaults.conf.template
xiaoye@ubuntu:~/spark/conf$
复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HADOOP_HOME=/home/xiaoye/hadoop
export HADOOP_CONF_DIR=/home/xiaoye/hadoop/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=ubuntu:2181,ubuntu2:2181,ubuntu3:2181 -Dspark.deploy.zookeeper.dir=/spark"解释:
集群搭建时配置的spark参数可能和现在的不一样,主要是考虑个人电脑配置问题,如果memory配置太大,机器运行很慢。
说明:
-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。就是说用zookeeper做了spark的HA配置,Master(Active)挂掉的话,Master(standby)要想变成Master(Active)的话,Master(Standby)就要像zookeeper读取整个集群状态信息,然后进行恢复所有Worker和Driver的状态信息,和所有的Application状态信息;
-Dspark.deploy.zookeeper.url=
buntu:2181,ubuntu2:2181,ubuntu3:2181 #将所有配置了zookeeper,并且在这台机器上有可能做master(Active)的机器都配置进来;(我用了3台,就配置了3台)
-Dspark.deploy.zookeeper.dir=/spark
这里的dir和zookeeper配置文件zoo.cfg中的dataDir的区别???
-Dspark.deploy.zookeeper.dir是保存spark的元数据,保存了spark的作业运行状态;
zookeeper会保存spark集群的所有的状态信息,包括所有的Workers信息,所有的Applactions信息,所有的Driver信息,如果集群
复制slaves.template成slaves:
xiaoye@ubuntu:~/spark/conf$ cp slaves.template slaves
修改slaves:
xiaoye@ubuntu:~/spark/conf$ vi slaves
ubuntu
ubuntu2
ubuntu31.5 一台机子配置完后分发给其他节点
xiaoye@ubuntu:~$ scp -r spark-2.3.0-bin-hadoop2.7/ xiaoye@192.168.26.141:/home/xiaoye
xiaoye@ubuntu:~$ scp -r spark-2.3.0-bin-hadoop2.7/ xiaoye@192.168.26.142:/home/xiaoye
1.6为每台机子创建软连接
xiaoye@ubuntu2:~$ ln -s spark-2.3.0-bin-hadoop2.7/ spark
xiaoye@ubuntu3:~$ ln -s spark-2.3.0-bin-hadoop2.7/ spark
1.7为每台机子配置环境变量
xiaoye@ubuntu:~$ vim .bashrc
#Spark
export SPARK_HOME=/home/xiaoye/spark
export PATH=$PATH:$SPARK_HOME/bin配置好后立即生效:
xiaoye@ubuntu:~$ source .bashrc
2试着启动spark集群
2.1启动zookeeper集群:
每台机子执行如下操作:
xiaoye@ubuntu:~$ ./zookeeper/sbin/zkServer.sh start
JMX enabled by default
Using config: /home/xiaoye/zookeeper/sbin/../conf/zoo.cfg
Starting zookeeper … STARTED
xiaoye@ubuntu:~$ ./zookeeper/sbin/zkServer.sh status
JMX enabled by default
Using config: /home/xiaoye/zookeeper/sbin/../conf/zoo.cfg
Mode: leader
2.2启动hdfs:
在一个节点执行以下命令即可:
xiaoye@ubuntu:~$ ./hadoop/sbin/start-dfs.sh
18/06/09 21:36:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [ubuntu ubuntu2]
ubuntu: Warning: Permanently added 'ubuntu,192.168.26.140' (ECDSA) to the list of known hosts.
ubuntu2: Warning: Permanently added 'ubuntu2,192.168.26.141' (ECDSA) to the list of known hosts.
ubuntu2: starting namenode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-namenode-ubuntu2.out
ubuntu: starting namenode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-namenode-ubuntu.out
ubuntu2: Warning: Permanently added 'ubuntu2,192.168.26.141' (ECDSA) to the list of known hosts.
ubuntu: Warning: Permanently added 'ubuntu,192.168.26.140' (ECDSA) to the list of known hosts.
ubuntu3: Warning: Permanently added 'ubuntu3,192.168.26.142' (ECDSA) to the list of known hosts.
ubuntu: starting datanode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-datanode-ubuntu.out
ubuntu2: starting datanode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-datanode-ubuntu2.out
ubuntu3: starting datanode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-datanode-ubuntu3.out
Starting journal nodes [ubuntu ubuntu2 ubuntu3]
ubuntu3: Warning: Permanently added 'ubuntu3,192.168.26.142' (ECDSA) to the list of known hosts.
ubuntu: Warning: Permanently added 'ubuntu,192.168.26.140' (ECDSA) to the list of known hosts.
ubuntu2: Warning: Permanently added 'ubuntu2,192.168.26.141' (ECDSA) to the list of known hosts.
ubuntu: starting journalnode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-journalnode-ubuntu.out
ubuntu3: starting journalnode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-journalnode-ubuntu3.out
ubuntu2: starting journalnode, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-journalnode-ubuntu2.out
18/06/09 21:36:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [ubuntu ubuntu2]
ubuntu2: Warning: Permanently added 'ubuntu2,192.168.26.141' (ECDSA) to the list of known hosts.
ubuntu: Warning: Permanently added 'ubuntu,192.168.26.140' (ECDSA) to the list of known hosts.
ubuntu2: starting zkfc, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-zkfc-ubuntu2.out
ubuntu: starting zkfc, logging to /home/xiaoye/hadoop/logs/hadoop-xiaoye-zkfc-ubuntu.out
xiaoye@ubuntu:~$ jps
\2746 NameNode
3252 DFSZKFailoverController
2573 QuorumPeerMain
2861 DataNode
3324 Jps
3060 JournalNode2.3启动spark
在三个节点分别执行以下命令:
xiaoye@ubuntu:~$ ./spark/sbin/start-all.sh
org.apache.spark.deploy.master.Master running as process 3359. Stop it first.
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /home/xiaoye/spark/logs/spark-xiaoye-org.apache.spark.deploy.worker.Worker-1-ubuntu.out好了之后jps分别查看启动的进程:
leader节点:
xiaoye@ubuntu:~$ jps
2746 NameNode
3359 Master
3252 DFSZKFailoverController
3550 Worker
2573 QuorumPeerMain
2861 DataNode
3583 Jps
3060 JournalNode其他两个从节点:
xiaoye@ubuntu2:~$ jps
2488 JournalNode
2748 Worker
2784 Jps
2654 Master
2229 QuorumPeerMain
2377 DataNode
xiaoye@ubuntu3:~$ jps
2510 Master
2582 Worker
2298 DataNode
2402 JournalNode
2665 Jps
2198 QuorumPeerMain3,验证是否成功启动
在web上查看:
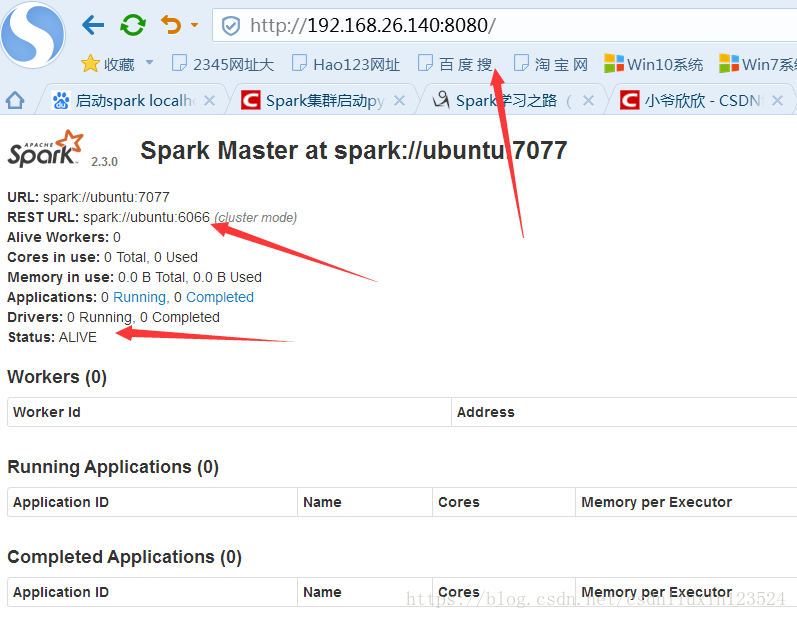
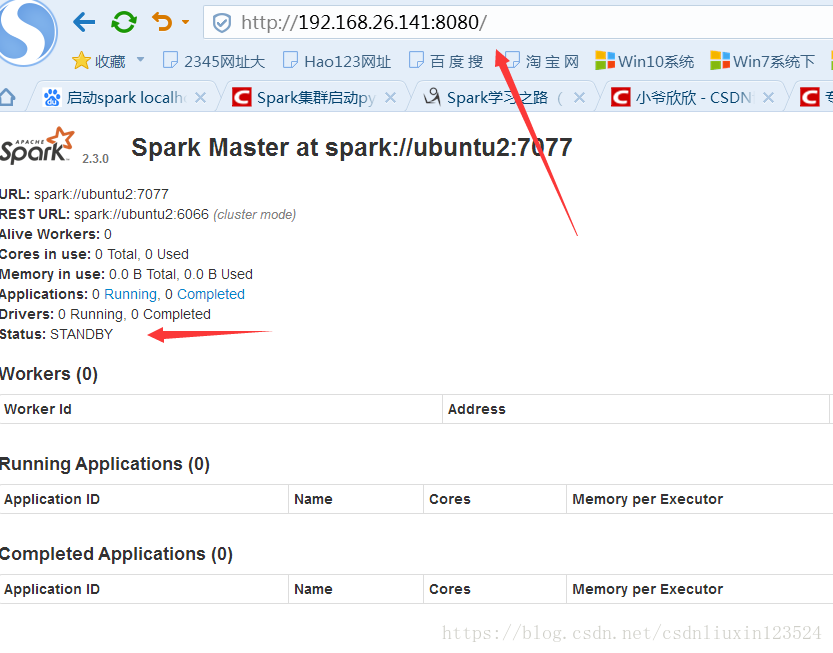
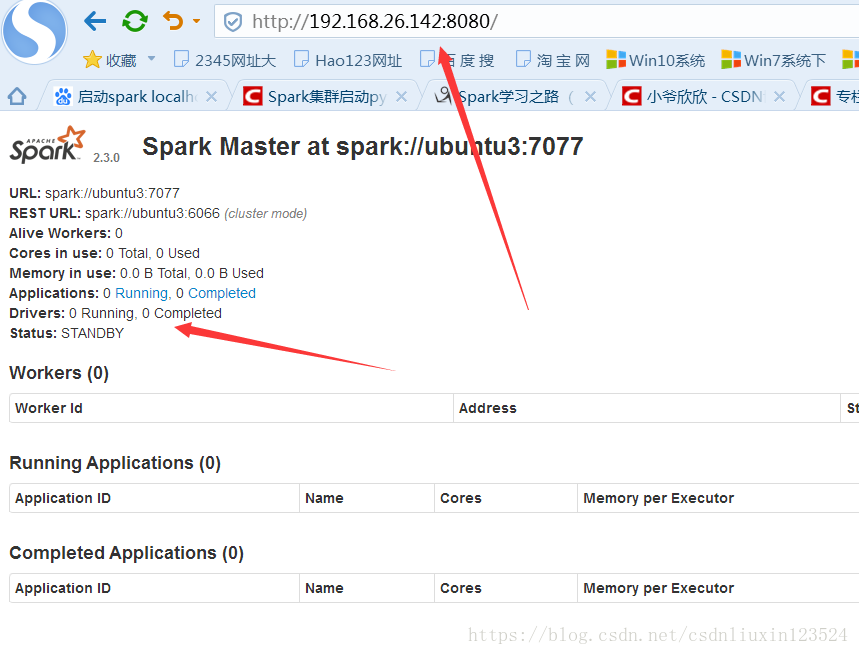
4,验证HA高可用
动干掉ubuntu上面的Master进程,观察是否会自动进行切换
xiaoye@ubuntu:~$ jps
3656 Jps
2746 NameNode
3359 Master
3252 DFSZKFailoverController
2573 QuorumPeerMain
2861 DataNode
3060 JournalNode
xiaoye@ubuntu:~$ kill -9 3359
xiaoye@ubuntu:~$ jps
2746 NameNode
3252 DFSZKFailoverController
2573 QuorumPeerMain
2861 DataNode
3666 Jps
3060 JournalNode查看web:
再看看其他两个节点有没有成功上位成live的:
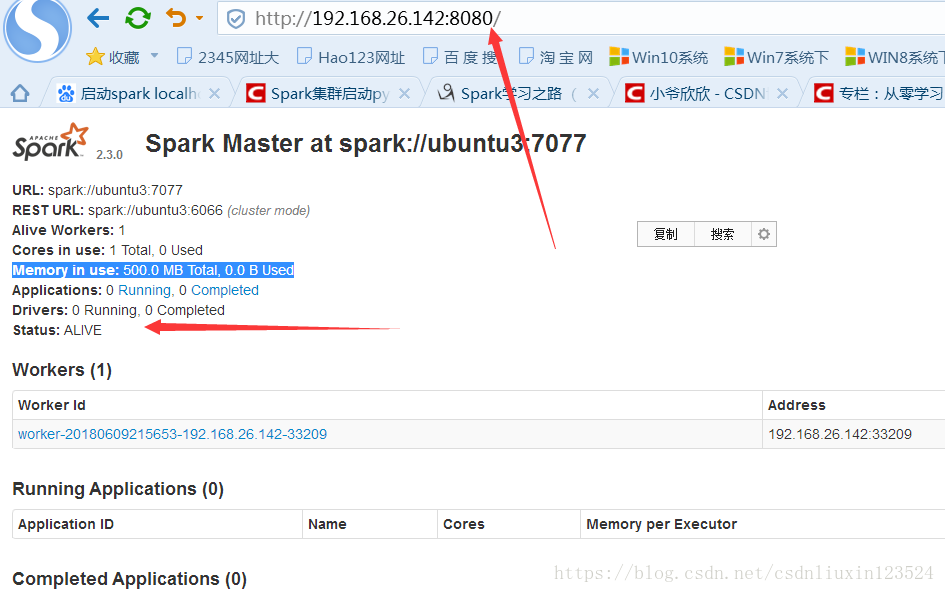
ubuntu3自动成为live节点说明成功。
5,执行spark程序 on standalone
5.1执行第一个spark程序,执行的是spark自带的案例:
在master下执行:
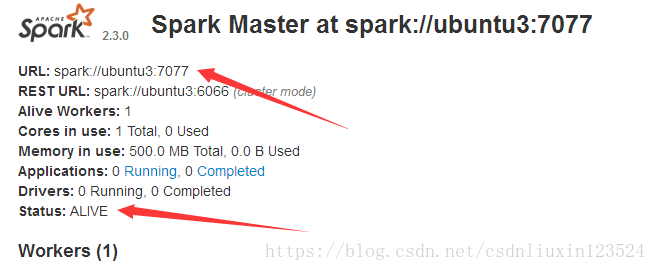
xiaoye@ubuntu3:~$ /home/xiaoye/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://ubuntu3:7077 --executor-memory 500m --total-executor-cores 1 /home/xiaoye/spark/examples/jars/spark-examples_2.11-2.3.0.jar 100

其中–master spark://ubuntu3:7077是下图的位置的结果:
运行结果:
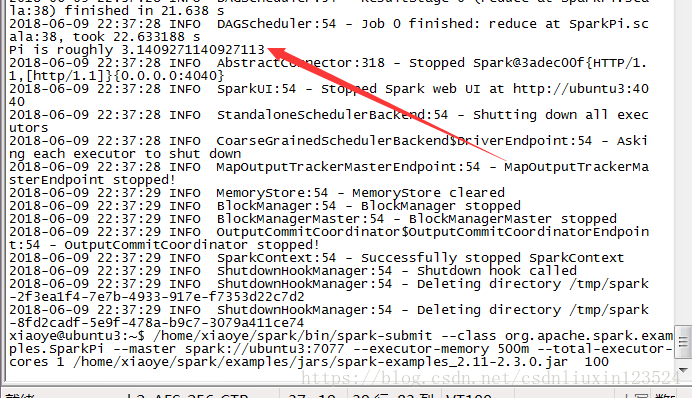
至于含义我们以后再讨论
5.2 启动spark shell
xiaoye@ubuntu3:~$ /home/xiaoye/spark/bin/spark-shell \
> --master spark://ubuntu3:7077 \
> --executor-memory 500m
> --total-executor-cores 1 参数说明:
–master spark://ubuntu3:7077 指定Master的地址
–executor-memory 500m:指定每个worker可用内存为500m
–total-executor-cores 1: 指定整个集群使用的cup核数为1个
xiaoye@ubuntu3:~$
xiaoye@ubuntu3:~$ /home/xiaoye/spark/bin/spark-shell \
> --master spark://ubuntu3:7077 \
> --executor-memory 500m
--^H^H2018-06-09 23:21:53 WARN Utils:66 - Your hostname, ubuntu3 resolves to a loopback address: 127.0.1.1; using 192.168.26.142 instead (on interface ens33)
2018-06-09 23:21:53 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2018-06-09 23:21:55 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu3:4040
Spark context available as 'sc' (master = spark://ubuntu3:7077, app id = app-20180609232223-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_162)
Type in expressions to have them evaluated.
Type :help for more information.
scala> --
scala>
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
Spark Shell中已经默认将SparkSQl类初始化为对象spark。用户代码如果需要用到,则直接应用spark即可
5.3在spark shell中编写word count 程序
创建一个文件,随便写点内容:
xiaoye@ubuntu3:~$ cat classes/aa.txt
hello world!
aa aa
d
d
dg
g然后上传到hdfs中:
xiaoye@ubuntu3:~/hadoop$ ./hadoop/ fs -mkdir -p /spark
-bash: ./hadoop/: Is a directory
xiaoye@ubuntu3:~/hadoop$ hadoop fs -mkdir -p /spark
18/06/09 23:32:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
xiaoye@ubuntu3:~/hadoop$ hadoop fs -ls /spark
18/06/09 23:33:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
xiaoye@ubuntu3:~/hadoop$ hadoop fs -put classes/aa.txt /spark
18/06/09 23:34:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
put: `classes/aa.txt': No such file or directory
xiaoye@ubuntu3:~/hadoop$ ls
bin etc hadoop lib sbin tmp
bin-mapreduce1 examples include libexec share
cloudera examples-mapreduce1 journal logs src
xiaoye@ubuntu3:~/hadoop$ cd ..
xiaoye@ubuntu3:~$ hadoop fs -put classes/aa.txt /spark
18/06/09 23:34:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
xiaoye@ubuntu3:~$ hadoop fs -ls /spark
18/06/09 23:34:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 2 xiaoye supergroup 29 2018-06-09 23:34 /spark/aa.txt5.4在spark shell中用scala编写spark程序,按空格分割数据
scala> sc.textFile("/spark/aa.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/out")说明:
sc是SparkContext对象,该对象是提交spark程序的入口
textFile(“/spark/aa.txt”)是hdfs中读取数据
flatMap(_.split(” “))先map再压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile(“/spark/out”)将结果写入到hdfs中
执行完后,查看hdfs的执行结果:
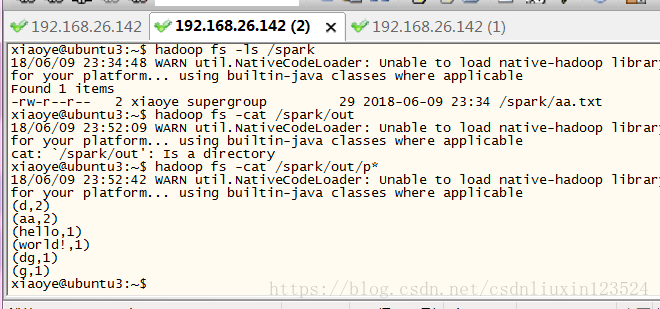
xiaoye@ubuntu3:~$ hadoop fs -cat /spark/out/p*
18/06/09 23:52:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(d,2)
(aa,2)
(hello,1)
(world!,1)
(dg,1)
(g,1)执行结果跟我们相要的结果是一样的。
6,执行spark程序 on Yarn
首先要成功启动zookeeper集群、HDFS集群、YARN集群
启动spark on Yarn
xiaoye@ubuntu3:~$
spark-shell --master yarn --deploy-mode client
启动时间比较长,成功启动:
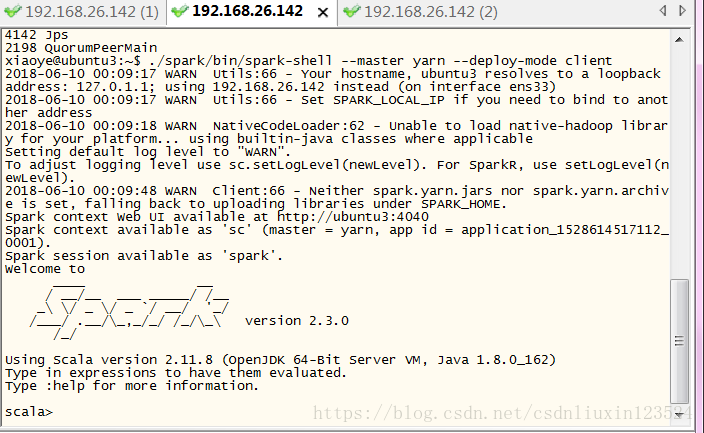
启动的进程如下:
xiaoye@ubuntu3:~$ jps
2298 DataNode
5150 ExecutorLauncher
3950 ResourceManager
2402 JournalNode
5375 Jps
5275 CoarseGrainedExecutorBackend
5274 CoarseGrainedExecutorBackend
4092 NodeManager
2198 QuorumPeerMain
4424 SparkSubmit发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/106103.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
