

前一阵子公司有个售前来沟通某个用户的情况:数据量比较大,又涉及很多复杂的关联计算,在数据库中用SQL计算性能很差。本来这种场景是比较适合集算器的集文件(集算器特有的压缩二进制格式)存储并计算,但据说这个用户的历史数据还会经常变动,而集文件目前没有提供改写能力(为了保证压缩率和性能),也就不容易直接用。于是想推荐用户采用nosql产品做存储,集算器在上面做计算。
赶快打住!如果用户真的听了,那会恨死我们。
这个场景中有三个要素:数据量大、复杂计算、频繁改动。
为了解释这三者的大致关系,我画了一个不太严谨的图:
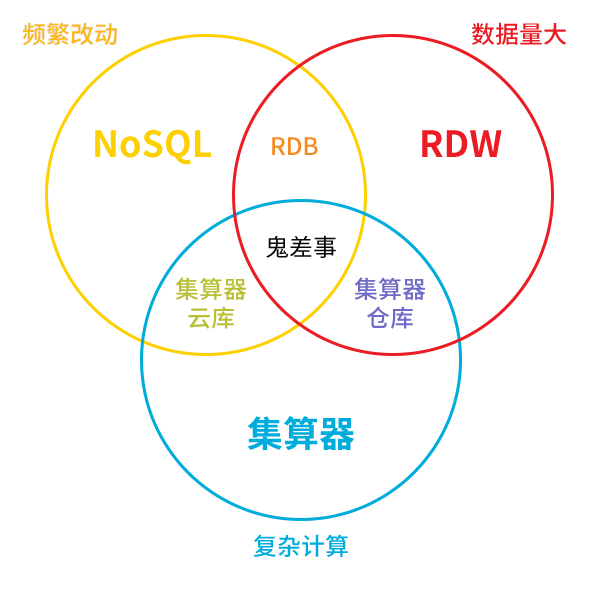
NoSQL数据库在存储时不考虑事务一致性,而且许多NoSQL产品对key-value结构(要改的数据肯定要有个key)的数据都会采用LSM树等优化手段,一般情况比RDB常用的B树性能要好,所以对于频繁改的应用,NoSQL的效率会比较高。相反,RDB虽然也能频繁改,但为了事务一致性等因素,效率就会低于NoSQL。
但key-value结构的NoSQL却不擅长大数据计算,除了按key找value比较快以外,涉及到遍历(这是家常便饭)的运算都不灵光,主要是因为value是无确定结构的,每次取出数据要现解析,而且数据结构也会多存很多空间,所以大数据计算效率就会远远低于RDB(所以上述场景一定要打住,绝不可以推荐NoSQL)。
RDB频繁修改后会导致数据在硬盘上的连续性很差,也不容易做好压缩,这样大数据量遍历的性能也不会太好。而RDW在RDB基础上做了运算优化,可以事先整理数据,放弃了复杂的写一致性能力,这样对于大数据计算就会有更好的性能。但反过来,频繁改就不适合了。
RDB和RDW都采用SQL体系运算,对于简单查询计算没太大问题,但过于复杂的关联和过程性运算,由于关系代数的局限性,很多优化算法无法实施(我们已经多次说过这个问题),所以在复杂运算场景下性能不佳(也就会发生上述场景的现象)。
集算器是为了复杂计算而设计,可以实现更优的算法获得更好的性能。但如开始所述,目前的集文件又不支持改写,所以它只适合解决复杂运算,而难以面对频繁改的场景。集算器其实比RDW在大数据计算性能方面更好,不过作为计算引擎并不太关注存储,而大数据需求中还是会比较在意的可维护管理能力就要弱了。
集算器进一步发展出来的仓库版将支持少量修改的存储方案,这样可以在保证复杂运算能力的基础上再提供数据维护能力,可以逐步替代数据仓库,不过也不合适频繁修改。而另一个方向的云库版则更注重结构多样性,同时也支持事务一致性,能适应频繁改,而且有集算器提供复杂计算能力,但同前面分析NoSQL的理由,这时候它又不适合大数据遍历了。
那么这三样都想要怎么办呢?难道就只能见鬼去?
其实也有办法,只要肯多花钱买大内存(还可能要集群)把数据全装进去,这三样就能并存了。毕竟,有钱能使鬼推磨嘛,呵呵!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/101703.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
