概述
分布式的集群很容易有“选举”的需求,所谓的选举可以先简单的理解为选出集群多个节点的“老大”(leader)
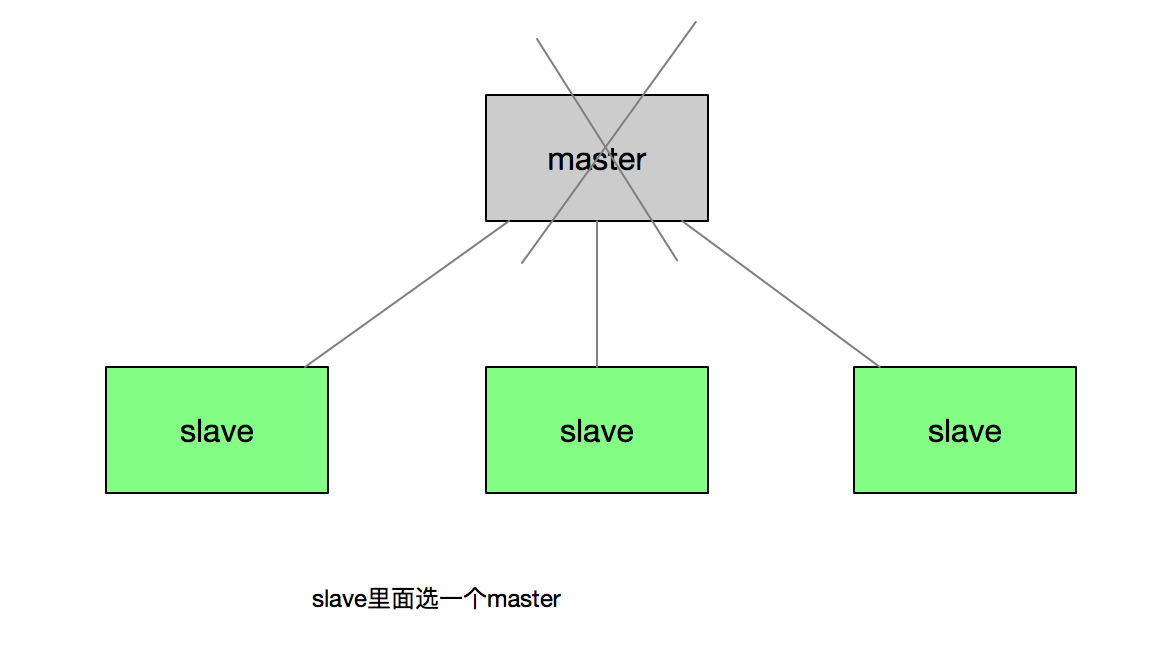
例子1 —— 主从节点选举
举个不是很恰当的例子(mysql不是使用zk来做选举的),我们使用mysql时候,为了做到高可用,可能会同时布两个mysql,一主多备。这个时候,如果master节点挂了,多个slave节点哪一个会被选为主节点?这里就涉及到“选举”,从多个slave节点里选出一个新的master。

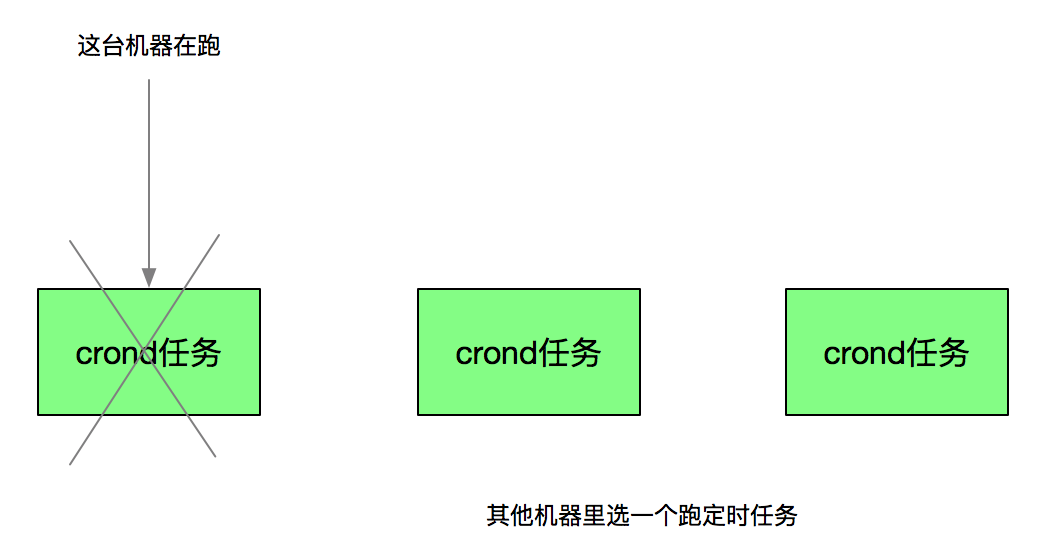
例子2 —— 定时任务
又比如,我们经常有定时任务的需求,为了保证高可用。可能跑定时任务的服务会部署多台。
假设有这样一个任务,它会扫表A,然后将这个表A的数据插入到另一个表B里。当只有一台机器跑这个任务,没有问题。但是如果同一时刻,有多台机器在跑,数据就会重复插入到表B里。
所以理想的情况可能是,同一时刻只有一台机器在跑定时任务。当这台机器挂掉了,立刻在其他机器里面选举出一台机器跑定时任务。
使用zookeeper来做集群的选举
总的来说,选举这种需求还是不少的。zookeeper是一个成熟的分布式协调服务,通过使用zookeeper我们可以较为方便的实现集群的选举。
leader选举 —— 非公平模式
Zookeeper节点类型
要想了解如何使用zookeeper实现选举,首先需要了解zookeeper节点的类型

当我们创建zookeeper节点时候,可以填一个CreateMode参数,通过这个参数可以指定创建的节点的类型。
1)PERSISTENT 该值会永久存在,哪怕创建该节点的机器挂了,节点数据依然会存在。注意,如果有两台机器创建了重复的key,比如/data,第二次创建会失败。
2)PERSISTENT_SEQUENTIAL 比如我们创建一个/test节点,zk会在后面加一串数字比如 /test/test0000000001。如果重复创建,会创建一个/test/test0000000002节点(一直往后加1,可以多次创建)
3)EPHEMERAL 临时节点,当创建该节点的机器失连了,创建的这个节点会被删除
4)EPHEMERAL_SEQUENTIAL 和 PERSISTENT_SEQUENTIAL差不多的,只是节点是临时的。
使用zookeeper实现非公平模式选举
了解了zookeeper节点的类型,我们就可以通过zk来实现选举。
什么是非公平模式选举
所谓的非公平模式的选举是相对的,假设有10台机器进行选举,最后会选到哪一个机器,是完全随机的(看谁抢的快)。比如选到了A机器。某一时刻,A机器挂掉了,这时候会再次进行选举,这一次的选举依然是随机的。与某个节点是不是先来的,是不是等了很久无关。这种选举算法,就是非公平的算法。

非公平选举算法
1)首先通过zk创建一个 /server 的PERSISTENT节点
2)多台机器同时创建 /server/leader EPHEMERAL子节点
3)子节点只能创建一个,后创建的会失败。创建成功的节点被选为leader节点
4)所有机器监听 /server/leader 的变化,一旦节点被删除,就重新进行选举,抢占式地创建 /server/leader节点,谁创建成功谁就是leader。
非公平选举算法实现示例
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("127.0.0.1:2181", FairSelectDemo.SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "---" + event.getPath() + "---" + event.getState());
}
});
//zk启动后试着进行选举
selection();
TimeUnit.HOURS.sleep(1); //阻塞住
zk.close();
}
private static void selection() throws Exception {
try {
//1、创建/server(这个通过zkCli创建好了),参数3表示公有节点,谁都可以改
zk.create("/server/leader", "node1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
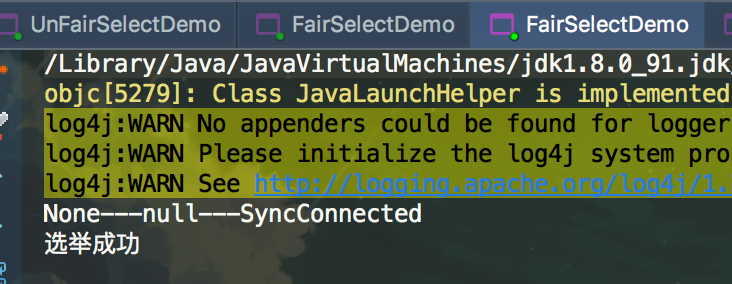
//2、没有抛异常,表示创建节点成功了
System.out.println("选举成功");
} catch (KeeperException.NodeExistsException e) {
System.out.println("选举失败");
} finally {
//3、监听节点删除事件,如果删除了,重新进行选举
zk.getData("/server/leader", new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "---" + event.getPath() + "---" + event.getState());
try {
if (Objects.equals(event.getType(), Event.EventType.NodeDeleted)) {
selection();
}
} catch (Exception e) {
}
}
}, null);
}
}
测试结果:
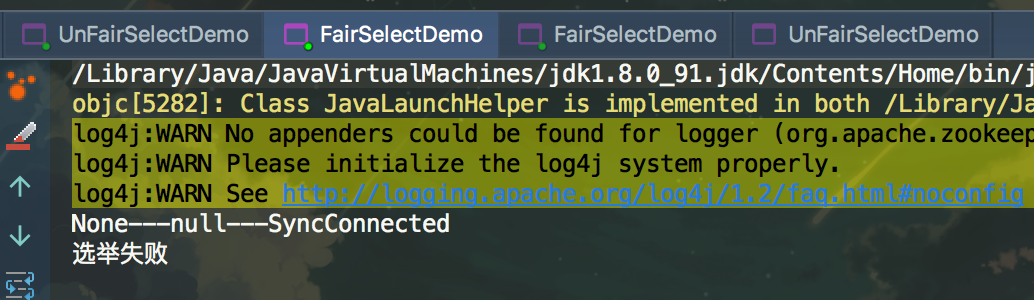
被选举的客户端被close掉后
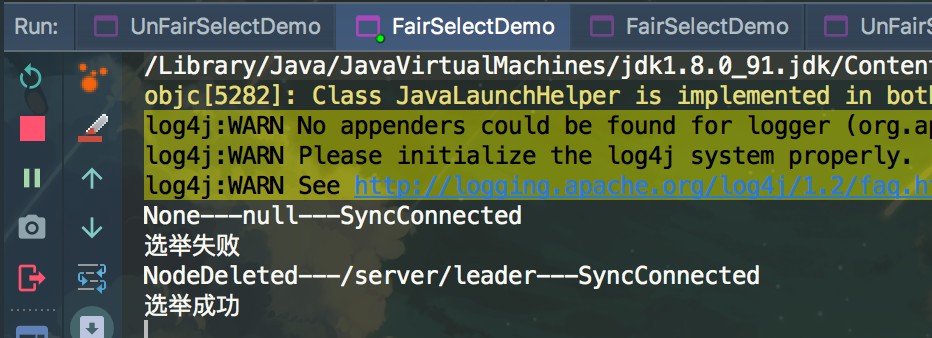
公平选举
非公平选举的区别是,增加了先来的优先被选为leader的保证。
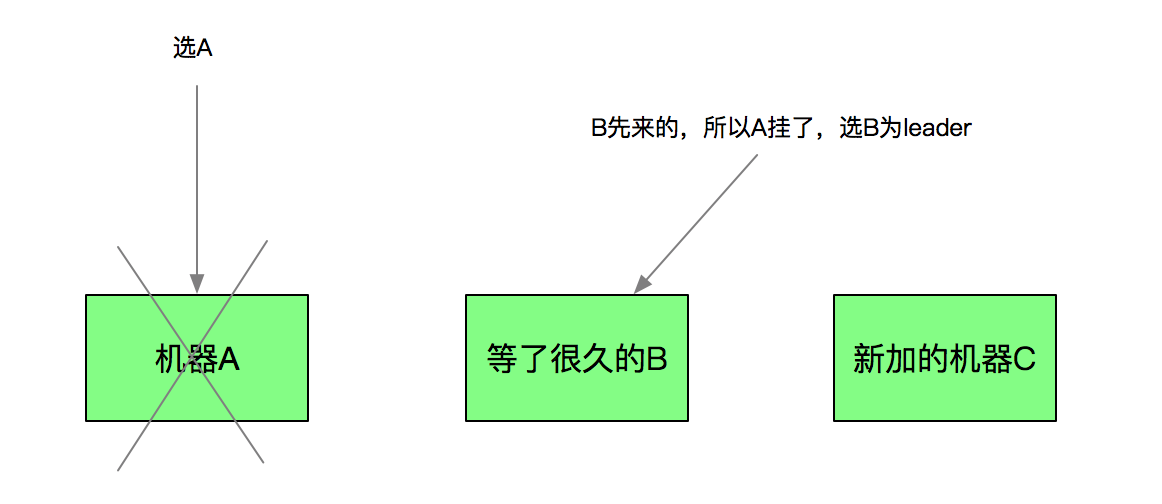
公平选举算法
1)首先通过zk创建一个 /server 的PERSISTENT节点
2)多台机器同时创建 /server/leader EPHEMERAL_SEQUENTIAL子节点
3)/server/leader000000xxx 后面数字最小的那个节点被选为leader节点
4)所有机器监听 前一个 /server/leader 的变化,比如 (leader00001监听 leader00002) 一旦节点被删除,就获取/server下所有leader,如果自己的数字最小那么自己就被选为leader
公平选举算法的实现
public static void main(String[] args) throws Exception {
zk = new ZooKeeper("127.0.0.1:2181", UnFairSelectDemo.SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "---" + event.getPath() + "---" + event.getState());
}
});
String leaderPath = "/server/leader";
//1、创建/server(这个通过zkCli创建好了),注意这里是EPHEMERAL_SEQUENTIAL的
//2、和非公平模式不一样,只需要创建一次节点就可以了
nodeVal = zk.create(leaderPath, "node1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
//System.out.println(nodeVal);
//启动后试着进行选举
selection();
TimeUnit.HOURS.sleep(1); //阻塞住
zk.close();
}
private static void selection() throws Exception {
//2、遍历/server下的子节点,看看自己的序号是不是最小的
List<String> children = zk.getChildren("/server", null);
Collections.sort(children);
String formerNode = ""; //前一个节点,用于监听
for (int i = 0; i < children.size(); i++) {
String node = children.get(i);
if (nodeVal.equals("/server/" + node)) {
if (i == 0) {
//第一个
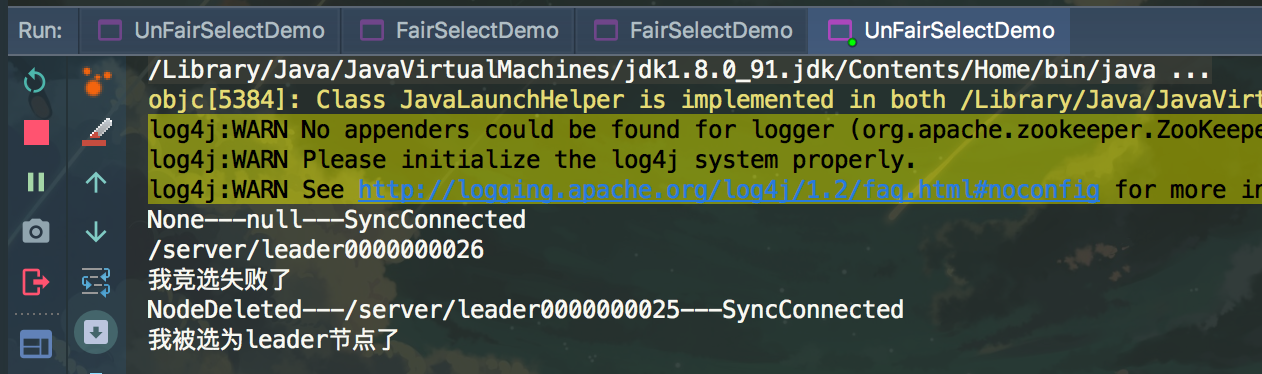
System.out.println("我被选为leader节点了");
} else {
formerNode = children.get(i - 1);
}
}
}
if (!"".equals(formerNode)) {
//自己不是第一个,如果是第一个formerNode应该没有值
System.out.println("我竞选失败了");
//3、监听前一个节点的删除事件,如果删除了,重新进行选举
zk.getData("/server/" + formerNode, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "---" + event.getPath() + "---" + event.getState());
try {
if (Objects.equals(event.getType(), Event.EventType.NodeDeleted)) {
selection();
}
} catch (Exception e) {
}
}
}, null);
}
//System.out.println("children:" + children);
}
测试结果
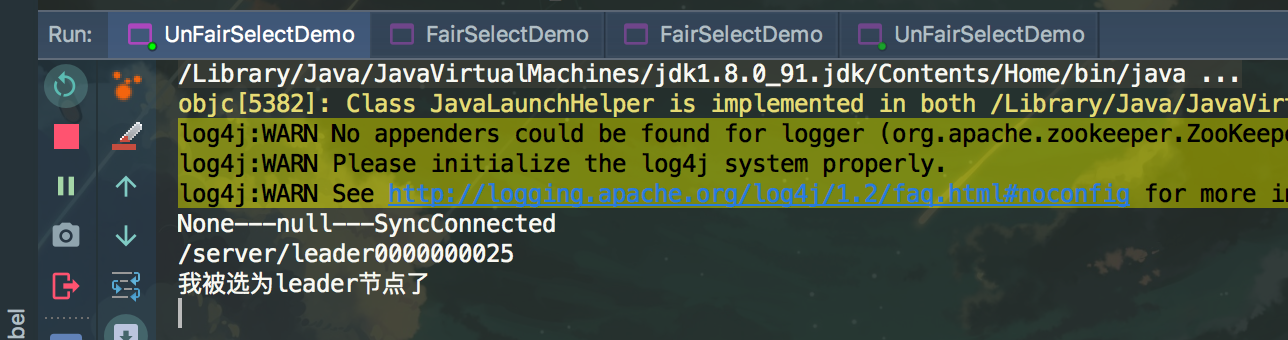
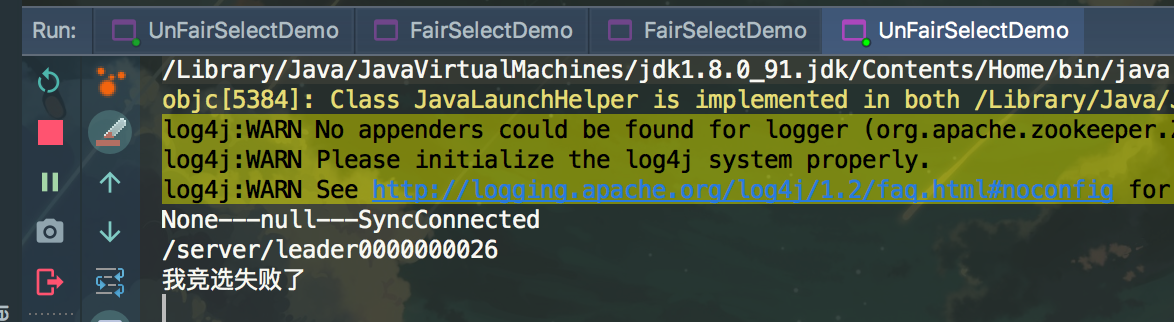
关闭被选为的leader节点后
总结
通过zookeeper的api,我们可以很容易实现集群的选举。当然此处介绍的zookeeper的选举比较适合于机器平权的情况,比如三台被选举的机器是一模一样的。如果有优先级,有调度,需要增加其他算法。这种方式就不适合了。
但是其实上述的写法不是很严谨,比如公平选举算法,如果中间一个节点挂掉了,假设有01,02,03,04节点 比如02挂掉了,03一直监听着02,那么这个时候03应该改为监听01,否则,当01挂了,没有任何节点能被选为leader。 除此之外,各种异常状态都需要我们自己处理。
为了更加方便的使用选举,我们可以使用Curator。Curator为我们封装了操作zookeeper底层的各种细节,比使用原生的zookeeper更为方便。下一篇博客会介绍下Curator的使用。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/101593.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
