
数据科学家Jeremy Howard在fast.ai的《生成对抗网络(GAN)》课程中曾经讲过这样一句话:
“从本质上来说,生成对抗网络(GAN)是一种特殊的损失函数。”
你是否能够理解这句话的意思?读完本文,你会更好的理解这句话的含义。
神经网络的函数逼近理论
在数学中,我们可以将函数看做一个“机器”或“黑匣子”,我们为这个“机器”或“黑匣子”提供了一个或多个数字作为输入,则会输出一个或多个数字,如下图所示:


将函数可以比喻成一个“机器”或“黑匣子”
一般来说,我们可以用一个数学表达式来表示我们想要的函数。但是,在一些特殊的情况下,我们就没办法将函数写成一堆加法和乘法的明确组合,比如:我们希望拥有这样一个函数,即能够判断输入图像的类别是猫还是狗。
如果不能用明确的用数学表达式来表达这个函数,那么,我们可以用某种方法近似表示吗?
这个近似方法就是神经网络。通用近似定理表明,如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以表示任何一个函数。
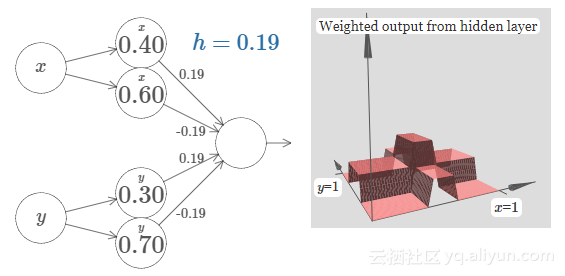
具有4个隐藏单元的简单神经网络逼近函数
作为损失函数的神经网络
现在,我们希望设计一个猫和狗的分类器。但我们没办法设计一个特别明确的分类函数,所以我们另辟蹊径,构建一个神经网络,然后一步一步逐渐实现这一目标。
为了更好的逼近,神经网络需要知道距离目标到底还有多远。我们使用损失函数表示误差。
现在,存在很多种类型的损失函数,使用哪种损失函数则取决于手头上的任务。并且,他们有一个共同的属性,即这些损失函数必须能够用精确的数学表达式来表示,如:
1.L1损失函数(绝对误差):用于回归任务。
2.L2损失函数(均方误差):和L1损失函数类似,但对异常值更加敏感。
3.交叉熵损失函数:通常用于分类任务。
4.Dice系数损失函数:用于分割任务。
5.相对熵:又称KL散度,用于测量两个分布之间的差异。
在构建一个性能良好的神经网络时,损失函数非常有用。正确深入的理解损失函数,并适时使用损失函数实现目标,是开发人员必备的技能之一。
如何设计一个好的损失函数,也是一个异常活跃的研究领域。比如:《密度对象检测的焦点损失函数(Focal Loss)》中就设计了一种新的损失函数,称为焦点损失函数,可以处理人脸检测模型中的差异。
可明确表示损失函数的一些限制
上文提到的损失函数适用于分类、回归、分割等任务,但是如果模型的输出具有多模态分布,这些损失函数就派不上用场了。比如,对黑白图像进行着色处理。
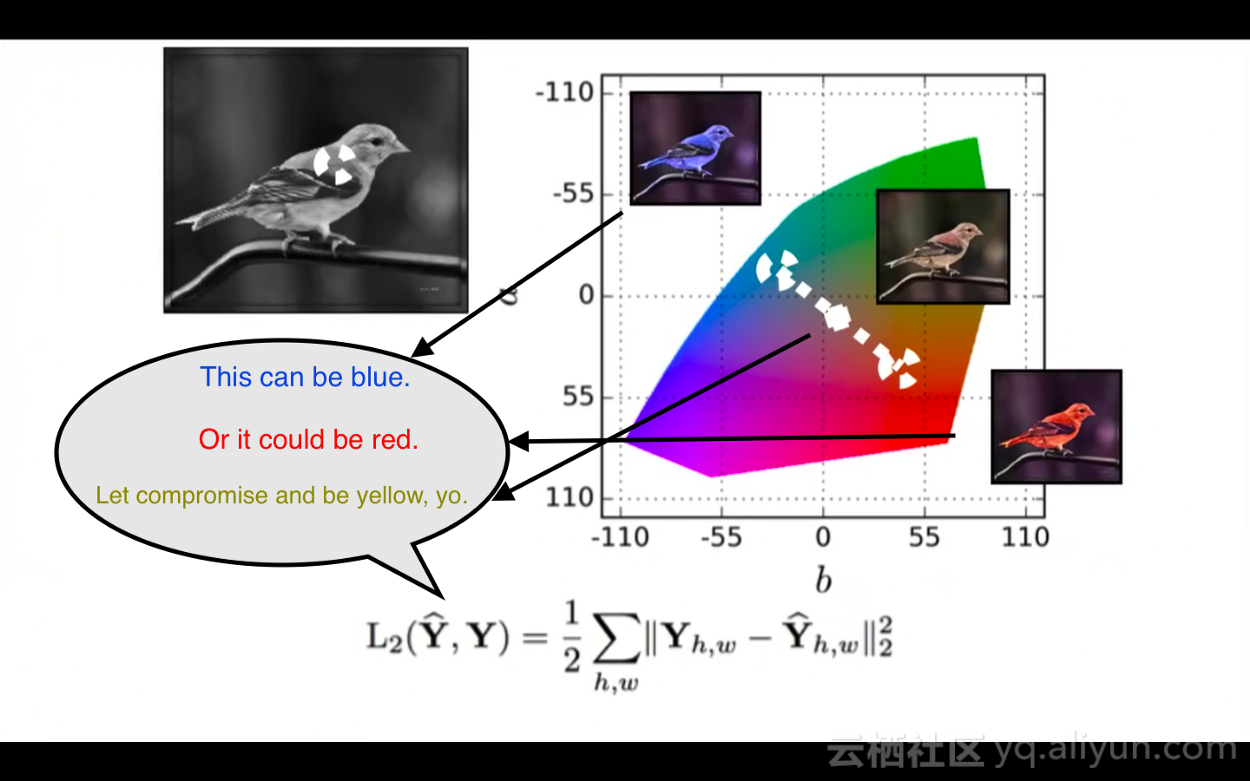
如上图所示:
1.输入图像是个黑白鸟类图像,真实图像的颜色是蓝色。
2.使用L2损失函数计算模型输出的彩色图像和蓝色真实图像之间的差异。
3.接下来,我们有一张非常类似的黑白鸟类图像,其真实图像的颜色是红色。
4.L2损失函数现在尝试着将模型输出的颜色和红色的差异最小化。
5.根据L2损失函数的反馈,模型学习到:对于类似的鸟类,其输出可以接近红色,也可以接近蓝色,那么,到底应该怎么做呢?
6.最后,模型输出鸟类的颜色为黄色,这就是处于红色和蓝色中间的颜色,并且是差异最小化的安全选择,即便是模型以前从未见过黄色的鸟,它也会这样做。
7.但是,自然界中没有黄色的鸟类,所以模型的输出并不真实。
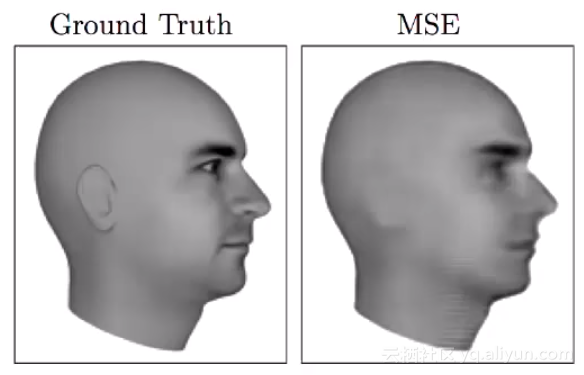
使用MSE预测的下一帧图像非常模糊
在很多情况下,这种平均效果并不理想。举个例子来说,如果需要模型预测视频中下一个帧图像,下一个帧有很多种可能,你肯定希望模型输出其中一种可能,然如果使用L1或L2损失函数,模型会将所有可能性平均化,输出一个特别模型的平均图像,这就和我们的目标相悖。
生成对抗网络——一种新的损失函数
如果我们没办法用明确的数学表达式来表示这个损失函数,那么,我们就可以使用神经网络进行逼近,比如,函数接收一组数字,并输出狗的真实图像。
神经网络需要使用损失函数来反馈当前结果如何,但是并没有哪个损失函数可以很好的实现这一目标。
会不会有这样一种方法?能够直接逼近神经网络的损失函数,但是我们没必要知道其数学表达式是什么,这就像一个“机器”或“黑匣子”,就跟神经网络一样。也就是说,如果使用一个神经网络模型替换这个损失函数,这样可以吗?
对,这就是生成对抗网络(GAN)。
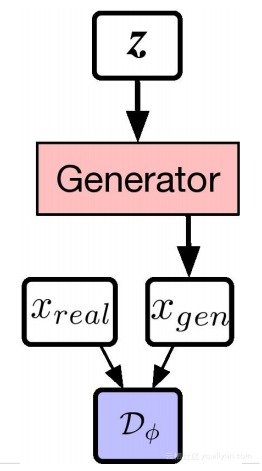
Vanilla-GAN架构
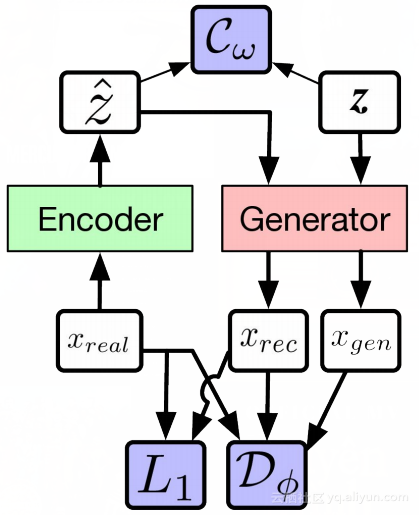
Alpha-GAN架构
我们来看上面两个图,就可以更好的理解损失函数。在上图中,白色框表示输入,粉色和绿色框表示我们要构建的神经网络,蓝色表示损失函数。
在vanilla GAN中,只有一个损失函数,即判别器D,这本身就是一个特殊的神经网络。
而在Alpha-GAN中,有3个损失函数,即输入数据的判别器D,编码潜在变量的潜在判别器C和传统的像素级L1损失函数。其中,D和C不是明确的损失函数,而是一种逼近,即一个神经网络。
梯度
如果使用损失函数训练生成网络(和Alpha-GAN网络中的编码器),那么,应该使用哪种损失函数来训练判别器呢?
判别器的任务是区分实际数据分布和生成数据分布,使用监督的方式训练判别器比较容易,如二元交叉熵。由于判别器是生成器的损失韩式,这就意味着,判别器的二进制交叉熵损失函数产生的梯度也可以用来更新生成器。
结论
考虑到神经网络可以代替传统的损失函数,生成对抗网络就实现了这一目标。两个网络之间的相互作用,可以让神经网络执行一些以前无法实现的任务,比如生成逼真的图像等任务。
转载于:https://my.oschina.net/u/1464083/blog/2991465
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/101242.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
