1 月 24 日,英特尔发表博文宣布开源其分布式深度学习平台Nauta。Nauta 使用业界领先的Kubernetes 和 Docker 平台运行,以实现可扩展性和易管理性。
GitHub开源地址:https://github.com/intelAI/Nauta
随着越来越多的企业探索在业务中使用 AI 来改善商业模式,AI 继续不断发展。根据 Gartner 最近一份报告显示,AI 部署已经产生巨大实际价值,2022 年价值有望达到 4 万亿美元。AI 中的深度学习也获得快速发展,据德勤一份 2018 年地调查显示,有将近 50% 的受访者表示已经采用了深度学习。虽然业务价值持续增长,并且企业对深度学习的兴趣显而易见,但集成、验证和优化深度学习解决方案仍然是一项复杂,有风险且耗时的工作。这就是英特尔使用 Kubernetes 为分布式深度学习引入Nauta 开源平台的原因。
Nauta是什么?
Nauta 提供了一个多用户的分布式计算环境,用于运行深度学习模型训练实验。它可以使用命令行界面、Web UI和/或TensorBoard 查看和监控实验结果。你可以使用现有数据集,自己的数据或在线下载的数据创建公共或私人文件夹,更轻松地在团队之间进行协作。
Nauta 使用业界领先的 Kubernetes 和 Docker 平台运行,以实现可扩展性和易管理性。为了让创建和运行单节点和多节点深度学习训练实验更简单,该平台兼容各种深度学习框架和工具的模板包(并可自定义),而无需标准容器环境所需的所有系统开销和脚本。
在模型测试中,Nauta 还支持批量和流式推理,所有工作在一个平台上完成。
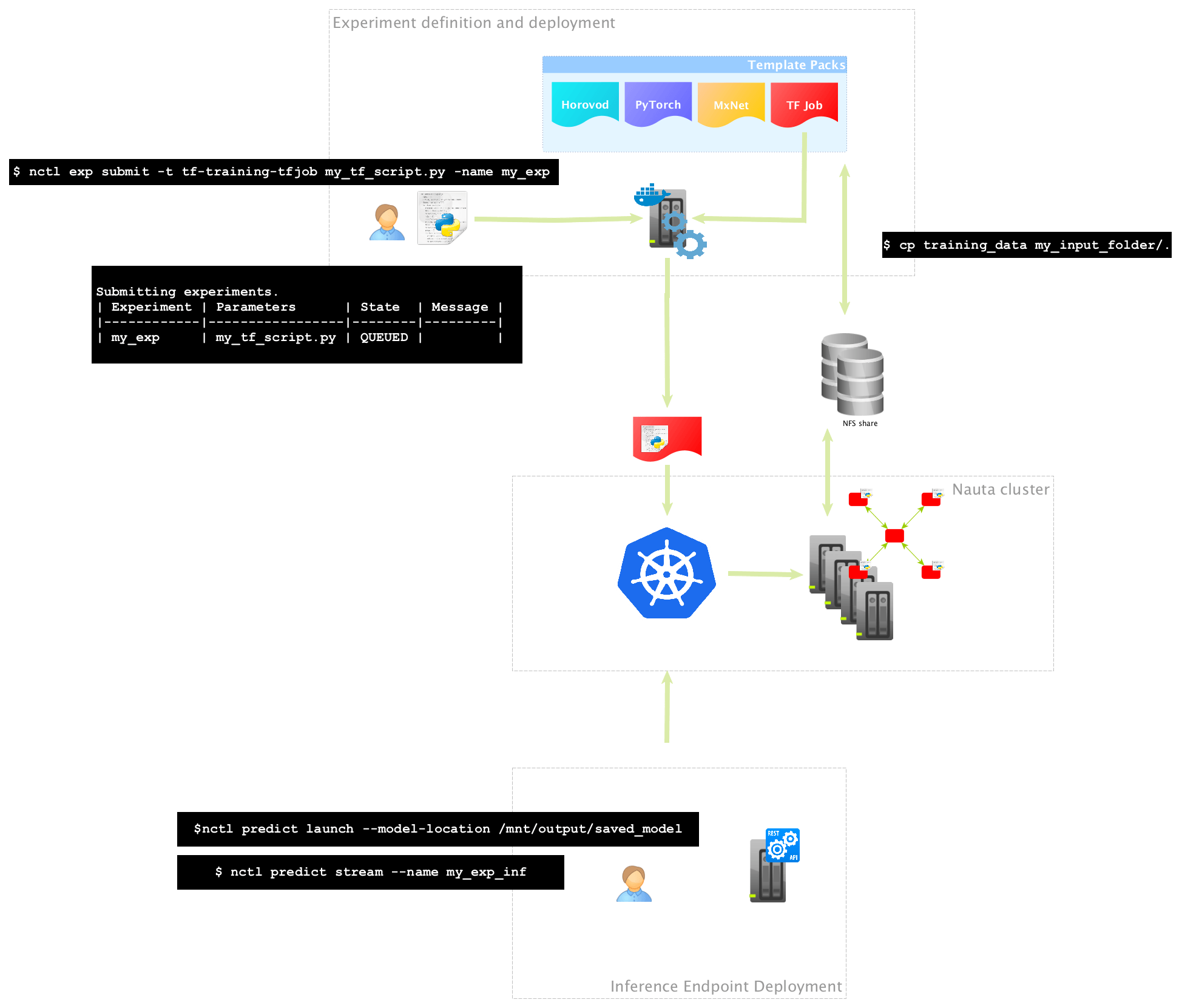

面向开发人员,支持Kubernetes和容器化
英特尔在创建 Nauta 工作流程中考虑到了开发人员和数据科学家。Nauta是一个企业级堆栈,适用于需要进行深度学习模型训练并在生产中部署团队。使用 Nauta,用户可以在单个或多个工作节点上使用 Kubernetes 定义并进行容器化的深度学习实验,并检查这些实验的状态和结果,以进一步调整和运行其他实验,或准备训练模型进行部署。
Nauta 特性
- Nauta 使用户能够利用来自经验丰富的机器学习开发人员和运营商的共享最佳实践,而不会牺牲灵活性。
- 在每个抽象级别,开发人员仍然有机会回退到 Kubernetes 并直接使用原语。
- Nauta让新手在有保障的情况下进行实验。精心挑选的组件和直观的用户体验减少了对开源DL服务的生产准备,配置和互操作性的担忧。
- 支持多团队成员协作,作业输入和输出可以在团队成员之间共享,并通过启动 TensorBoard来查看其他人的工作检查点,帮助调试问题。
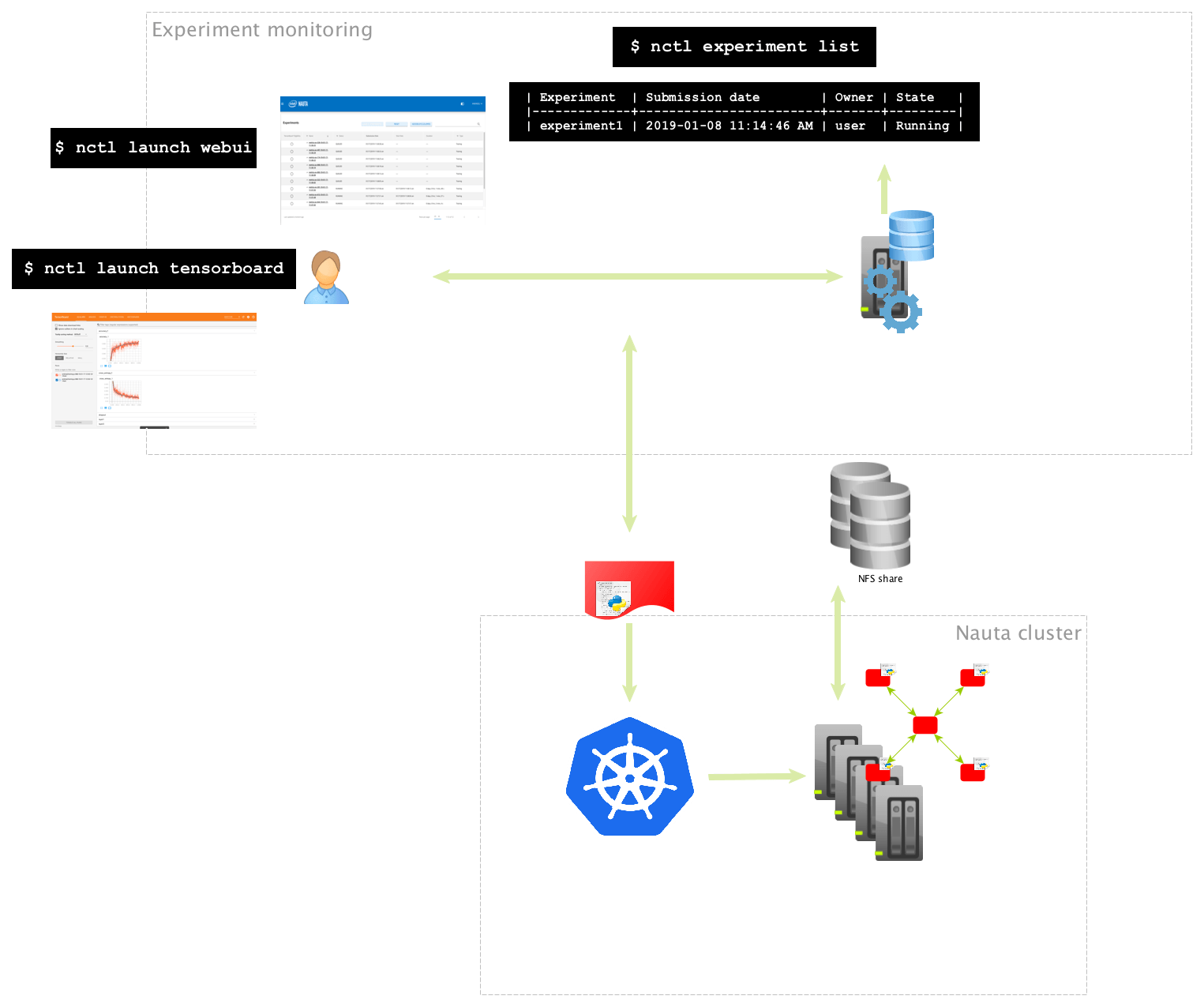
创建指南
2019年,Nauta 将在 Q1 及更高版本中进行更新,并通过landing page维护开发者社区,鼓励开发人员和数据科学家在他们自己的堆栈上尝试Nauta。
有关最新的技术信息,包括安装指南,用户文档以及如何参与项目,参见 Github:https://github.com/intelAI/Nauta
构建 Nauta 安装包并在Google Cloud Platform上顺利运行,请关注Google云平台上的Nauta 入门。
有关构建 Nauta 包的详细信息,参见如何构建指南 。
快速启动并运行,请查看入门指南 。
更多信息,请参阅以下文档:
Nauta、Kubeflow Pipeline、Azure Kubernetes、Acumos AI对比
Nauta 是可以使用 Kubernetes 或 Docker 容器的最新发布工具,这种方法让从业者在通过内部部署服务器还是云端部署AI之间进行选择。
11月,谷歌推出了一个Kubernetes工作流程 Kubeflow Pipeline,而微软上个月在公开预览中推出了 Azure Kubernetes 服务。
Kubeflow Pipeline GitHub:https://github.com/kubeflow/pipelines
Kubeflow是一个使用Kubeflow Pipelines SDK构建的可重复使用的端到端ML工作流程,致力于使 Kubernetes 上机器学习工作流的部署简单,可移植和可扩展。
Azure Kubernetes:https://azure.microsoft.com/en-us/services/kubernetes-service/
Azure Kubernetes简化Kubernetes管理、部署和运营,使用完全托管的 Kubernetes 容器编排服务。
另外,Linux 基金会的 LF 深度学习基金也于去年秋季推出了用于深度学习的 Acumos AI 平台和开源框架,可以轻松构建、共享和部署AI应用程序,标准化了运行开箱即用的通用 AI 环境所需的基础架构堆栈和组件。
参考链接:
https://venturebeat.com/2019/01/23/heartland-tech-weekly-indie-vcs-funding-model-could-be-promising-for-startups-in-middle-america/
https://www.acumos.org/
https://azure.microsoft.com/en-us/services/kubernetes-service/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/101155.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
