1. NoSQL 简介
NoSQL(NoSQL = Not Only SQL ),意即”不仅仅是SQL”。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDMBSs)来处理。 1970年 E.F.Codd’s提出的关系模型的论文 “A relational model of data for large shared data banks”,这使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
1.1 什么是NoSQL
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
对NoSQL最普遍的解释是”非关联型的”,强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1.2 为什么使用NoSQL ?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
2. MongoDB简介
Mongodb由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。,是专为可扩展性,高性能和高可用性而设计的数据库, 是非关系型数据库中功能最丰富,最像关系型数据库的,它支持的数据结构非常散,是类似 json 的 bjson 格式,因此可以存储比较复杂的数据类型。
MongoDB的(来自于英文单词“了Humongous”,中文含义为“庞大”)是可以应用于各种规模的企业,各个行业以及各类应用程序的开源数据库。作为一个适用于敏捷开发的数据库,MongoDB的的数据模式可以随着应用程序的发展而灵活地更新。
MongoDB 以一种叫做 BSON(二进制 JSON)的存储形式将数据作为文档存储。具有相似结构的文档通常被整理成集合。可以把这些集合看成类似于关系数据库中的表: 文档和行相似, 字段和列相似。
2.1 MongoDB数据格式
2.1.1 JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C、 C++、 C#、 Java、JavaScript、 Perl、 Python等)。这些特性使JSON成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。JSON 的官方 MIME 类型是 application/json,文件扩展名是 .json。
MongoDB 使用JSON(JavaScript ObjectNotation)文档存储记录。
JSON简单说就是JavaScript中的对象和数组,通过对象和数组可以表示各种复杂的结构。
对象:
对象在js中表示为“{}”括起来的内容,数据结构为 {key: value,key: value,…}的键值对的
结构,在面向对象的语言中, key为对象的属性, value为对应的属性值,所以很容易理
解,取值方法为 对象.key 获取属性值,这个属性值的类型可以是 数字、字符串、数组、
对象几种。
例如: {"FirstName":"ke","LastName":"me","email":"hikeme@aa"}
取值方式和所有语言中一样,使用key获取,字段值的类型可以是 数字、字符串、数组、对象几种。
2.1.2 BSON
BSON是一种类JSON的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。
它的优点是灵活性高,但它的缺点是空间利用率不是很理想。
BSON有三个特点:轻量性、可遍历性、高效性。
对JSON来说,数据存储是无类型的,比如你要修改基本一个值,从9到10,由于从一个字符变成了两个,所以可能其后面的所有内容都需要往后移一位才可以。而使用BSON,你可以指定这个列为数字列,那么无论数字从9长到10还是100,我们都只是在存储数字的那一位上进行修改,不会导致数据总长变大。当然,在MongoDB中,如果数字从整形增大到长整型,还是会导致数据总长变大的。
有时BSON相对JSON来说也并没有空间上的优势,比如对{“sex”:1},在JSON的存储上
1只使用了一个字节,而如果用BSON,那就是至少4个字节
2.2 MongoDB 特点
高性能: Mongodb 提供高性能的数据持久性,尤其是支持嵌入式数据模型减少数据库系统上的 I/O操作,索引支持能快的查询,并且可以包括来嵌入式文档和数组中的键
丰富的语言查询: Mongodb 支持丰富的查询语言来支持读写操作(CRUD)以及数据汇总,文本搜索和地理空间索引
高可用性: Mongodb 的复制工具,成为副本集,提供自动故障转移和数据冗余,
水平可扩展性: Mongodb 提供了可扩展性,作为其核心功能的一部分,分片是将数据分,在一组计算机上。
支持多种存储引擎: WiredTiger 存储引擎和、 MMAPv1存储引擎和 InMemory 存储引擎
MongoDB Server
是一个文档数据库,具有您需要的可扩展性和灵活性,丰富的查询和索引,
当前最高稳定版本4.0

MongoDB Drivers
官方MongoDB客户端库提供C, C ++, C#, Java, Node.JS, Perl, PHP,Python, Ruby和Scala驱动程序的参考指南。
MongoDB Stitch
为开发人员提供了一个API到MongoDB和其他后端服务。保持MongoDB的全部功能和灵性,同时受益于强大的系统来配置细粒度的数据访问控制。
MongoDB Atlas
MongoDB在云中部署,操作和扩展的最佳方式。适用于AWS,Azure和Google Cloud Platform。轻松将数据迁移到MongoDB Atlas,零停机
MongoDB Cloud Manager
是一个用于管理MongoDB部署的软件包。 Ops Manager提供Ops Manager监控和Ops Manager备份,可帮助用户优化群集并降低操作风险
MongoDB Charts
可以最快速最简单的创建Mongodb可视化图表
MongoDB Connector for BI
MongoDB商业智能连接器(BI)允许用户使用SQL创建查询,并使用现有的关系商业智能工具(如Tableau, MicroStrategy和Qlik)对其MongoDB Enterprise数据进行可视化,图形化和报告。
MongoDB Compass
通过从集合中随机抽样一个文档子集,为用户提供其MongoDB模式的图形视图。采样文件可最大程度地降低对数据库的影响,并能快速产生结果。有关 抽样的更多信息
MongoDB Spark Connector
使用连接器,您可以访问所有使用MongoDB数据集的Spark库:用SQL进行分析的数据集(受益于自动模式推理),流式传输,机器学习和图形API。您也可以使用连接器与Spark Shell。
3. MongoDB 安装
我的操作系统版本
[root@mongo-160 ~]# cat /etc/redhat-release
CentOS Linux release 7.2.1511 (Core)
官方文档手册
# 官方文档手册
https://docs.mongodb.com/manual/
我安装的是MongoDB 3.4 版本的,选择3.4版本查看相应手册
3.1 安装方式
我使用的是二进制包方式
3.2 目录规划
mongo软件以软连接形式放在/opt 目录下
mongo数据存放目录存放在/data/mongo
3.3 软件安装
[root@mongo-160 ~]# mkdir -p /data/soft
[root@mongo-160 ~]# cd /data/soft/
[root@mongo-160 soft]# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.20.tgz
[root@mongo-160 soft]# tar zxvf mongodb-linux-x86_64-3.4.20.tgz -C /opt/
[root@mongo-160 soft]# cd /opt/
[root@mongo-160 opt]# ln -s mongodb-linux-x86_64-3.4.20/ mongodb
[root@mongo-160 opt]# ll
total 0
lrwxrwxrwx. 1 root root 28 Jun 5 18:09 mongodb -> mongodb-linux-x86_64-3.4.20/
drwxr-xr-x. 3 root root 86 Jun 5 17:56 mongodb-linux-x86_64-3.4.20
# 为什么做软链接了,以后后续版本做升级,
# 可以快速回滚到原来版本 这是最根本的
# 还可以做多实例
# 创建数据目录
[root@mongo-160 opt]# mkdir -p /data/mongodb
[root@mongo-160 opt]# mkdir -p /opt/mongodb/{conf,logs,pid}
[root@mongo-160 mongodb]# cd /opt/mongodb/
[root@mongo-160 mongodb]# ll
total 120
drwxr-xr-x. 2 root root 4096 Jun 5 17:56 bin
drwxr-xr-x. 2 root root 6 Jun 5 18:13 conf
-rw-r--r--. 1 root root 34520 Mar 13 06:02 GNU-AGPL-3.0
drwxr-xr-x. 2 root root 6 Jun 5 18:13 logs
-rw-r--r--. 1 root root 16726 Mar 13 06:02 MPL-2
drwxr-xr-x. 2 root root 6 Jun 5 18:13 pid
-rw-r--r--. 1 root root 2266 Mar 13 06:02 README
-rw-r--r--. 1 root root 55625 Mar 13 06:02 THIRD-PARTY-NOTICES
3.4 配置文件
mongodb.conf 配置文件是yaml格式的
看看官方文档3.4版本的配置手册:
https://docs.mongodb.com/v3.4/reference/configuration-options/
我的环境配置文件如下:
[root@mongo-160 ~]# cat /opt/mongodb/conf/mongodb.conf
systemLog:
destination: file #Mongodb 日志输出的目的地,指定一个 file 或者 syslog,如果指定 file,必须指定systemlog.path
logAppend: true #当实例重启时,不创建新的日志文件,在老的日志文件末尾继续添加
path: /opt/mongodb/logs/mongodb.log #日志路径
storage:
dbPath: /data/mongodb #数据存储目录
journal: #回滚日志
enabled: true
directoryPerDB: true #默认 false,不适用 inmemory engine
wiredTiger:
engineConfig:
cacheSizeGB: 1 #将用于所有数据缓存的最大小
directoryForIndexes: true #默认 false 索引集合 storage.dbPath 存储在数据单独子目录
processManagement: #使用处理系统守护进程的控制处理
fork: true # fork and run in background 后台运行
pidFilePath: /opt/mongodb/pid/mongod.pid # location of pidfile 创建 pid 文件
net:
port: 27017 #监听端口
bindIp: 127.0.0.1,10.0.0.160 #绑定 ip
#replication:
# oplogSizeMB: 1024 #复制操作日志的大小
# replSetName: xxx #副本集名称,同一个副本集的所有主机必须设置相同的名称
3.5 管理 mongo
3.5.1 启动和关闭 mongo
#开启mongo
[root@mongo-160 ~]# /opt/mongodb/bin/mongod -f /opt/mongodb/conf/mongodb.conf
about to fork child process, waiting until server is ready for connections.
forked process: 14662
child process started successfully, parent exiting
#检查是否有mongo进程
[root@mongo-160 ~]# ps aux | grep mongo
root 14662 0.9 2.1 942708 43296 ? Sl 09:51 0:00 /opt/mongodb/bin/mongod -f /opt/mongodb/conf/mongodb.conf
root 14691 0.0 0.0 112644 948 pts/0 R+ 09:53 0:00 grep --color=auto mongo
#检查mongo的端口号
[root@mongo-160 ~]# netstat -ntulp | grep mongo
tcp 0 0 10.0.0.160:27017 0.0.0.0:* LISTEN 14662/mongod
tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN 14662/mongod
#检查mongo数据文件是否生成,没生成以前默认是空的
[root@mongo-160 ~]# cd /data/mongodb/
[root@mongo-160 mongodb]# ls
admin journal _mdb_catalog.wt sizeStorer.wt WiredTiger WiredTiger.lock WiredTiger.wt
diagnostic.data local mongod.lock storage.bson WiredTigerLAS.wt WiredTiger.turtle
#关闭mongo
[root@mongo-160 mongodb]# /opt/mongodb/bin/mongod -f /opt/mongodb/conf/mongodb.conf --shutdown
killing process with pid: 14662
# 再次查看还有没有端口号,没有了
[root@mongo-160 mongodb]# netstat -ntulp | grep mongo
注意一下: 尽量少用kill -9
如果用kill 建议用
shell> kill -2 PID
原理:-2表示向mongod进程发送SIGINT信号。这是终端等同于ctrl+c
或
shell> kill -4 PID
原理:-4表示向mognod进程发送SIGTERM信号。
mongod进程收到SIGINT信号或者SIGTERM信号,会做一些处理
> 关闭所有打开的连接
> 将内存数据强制刷新到磁盘
> 当前的操作执行完毕
> 安全停止
切忌kill -9
3.5.2 写入环境变量
[root@mongo-160 mongodb]# echo 'PATH=$PATH:/opt/mongodb/bin' >> /etc/profile
[root@mongo-160 mongodb]# tail -n 1 /etc/profile
PATH=$PATH:/opt/mongodb/bin
[root@mongo-160 mongodb]# source /etc/profile
#查看有哪些mongo命令,是否写入环境变量成功了,有就是成功了
[root@mongo-160 mongodb]# mongo
mongo mongodump mongofiles mongooplog mongoreplay mongos mongotop
mongod mongoexport mongoimport mongoperf mongorestore mongostat 3.5.3 创建 hosts 解析
[root@mongo-160 ~]# echo "10.0.0.160 mongo-160" >> /etc/hosts
[root@mongo-160 ~]# ping mongo-160
PING mongo-160 (10.0.0.160) 56(84) bytes of data.
64 bytes from mongo-160 (10.0.0.160): icmp_seq=1 ttl=64 time=0.060 ms3.5.4 连接 mongo
# 开启mongo
[root@mongo-160 ~]# mongod -f /opt/mongodb/conf/mongodb.conf
# 连接mongo
[root@mongo-160 ~]# mongo mongo-160:27017
MongoDB shell version v3.4.20
connecting to: mongodb://mongo-160:27017/test
MongoDB server version: 3.4.20
Welcome to the MongoDB shell.
...
> exit
bye
3.5.5 mongo 终端停止服务
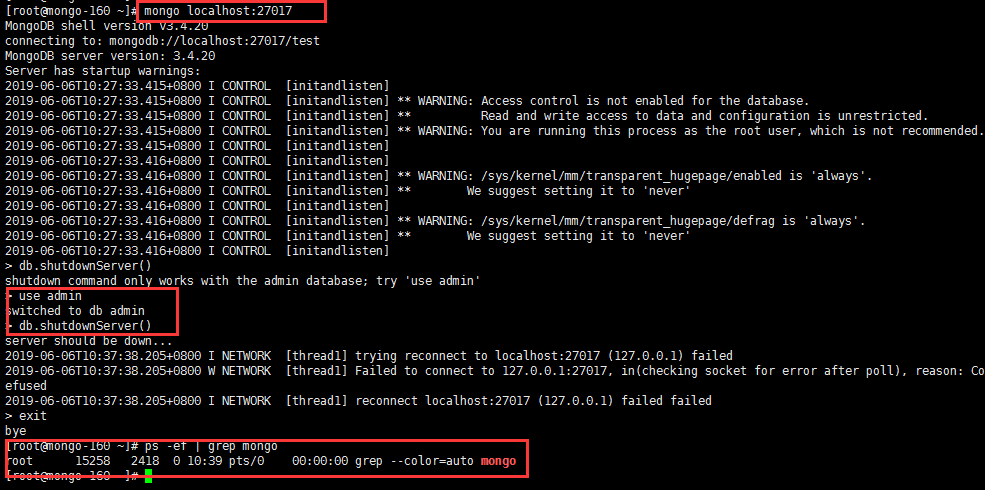
注意,关闭命令建议使用 mongo 内置的 db.shutdownServer()命令
使用这条命令的前提是必须使用 localhost 登陆mongo,否则会提示报错
[root@mongo-160 ~]# mongo localhost:27017
MongoDB shell version v3.4.20
connecting to: mongodb://localhost:27017/test
MongoDB server version: 3.4.20
...
> db.shutdownServer()
server should be down...
2019-06-06T10:37:38.205+0800 I NETWORK [thread1] trying reconnect to localhost:27017 (127.0.0.1) failed
> exit
bye
[root@mongo-160 ~]# ps -ef | grep mongo
root 15258 2418 0 10:39 pts/0 00:00:00 grep --color=auto mongo
4.MongoDB 日志的警告信息

** WARNING: Access control is not enabled for the database.
** Read and write access to data and configuration is unrestricted.
对数据库来说访问控制是没有开启的,读取和写入数据和配置是不受限制的。需要我们创建个用户,
开启认证。
** WARNING: You are running this process as the root user, which is not recommended.
不推荐以root用户来运行mongo
** WARNING: /sys/kernel/mm/transparent_hugepage/enabled is 'always'.
** We suggest setting it to 'never'
** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'.
** We suggest setting it to 'never'
自CentOS6版本开始引入了Transparent Huge Pages(THP),从CentOS7版本开始,该特性默认就会启用。尽管THP的本意是为提升内存的性能,不过某些数据库厂商还是建议直接关闭THP(比如说Oracle、MariaDB、 MongoDB等),透明的Huge Pages可能会在运行时引起内存分配延迟。
查看THP的启动状态:
[root@mongo-160 ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
[root@mongo-160 ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
[always] madvise never
透明的大页(THP)是一种Linux内存管理系统,它可以减少机器w上的翻译后备缓冲区(TLB)查找的开销
always - always use THP
never - disable THP
运行以下命令即时禁用THP
[root@mongo-160 ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@mongo-160 ~]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@mongo-160 ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
[root@mongo-160 ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[root@mongo-160 ~]# chmod +x /etc/rc.d/rc.local
[root@mongo-160 ~]# vim /etc/rc.d/rc.local
#添加如下两行内容
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@mongo-160 ~]# tail -n 2 /etc/rc.d/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
5. MongoDB 的 CRUD操作
CRUD 操作是 create(创建), read(读取), update(更新)和 delete(删除) 文档
MongoDB 3.x 不支持多文档事务(mongodb4.0 开始支持 )。但是 MongoDB 确实在一个文档上提供了原子操作。尽管集合中的文档通常都是相同的,但是 MongoDB 中的集合不需要指定 schema。
MongoDB 不支持 SQL 但是支持自己的丰富的查询语言。
在 MongoDB 中,存储在集合中的每个文档都需要一个唯一的 _id 字段,作为主键。如果插入的文档省略了该_id 字段,则 MongoDB 驱动程序将自动为该字段生成一个 ObjectId_id。也用于通过更新操作插入的文档upsert: true.如果文档包含一个_id 字段,该_id 值在集合中必须是唯一的,以避免重复键错误。
在 MongoDB 中,插入操作针对单个集合。 MongoDB 中的所有写操作都是在单个文档的级别上进行的
5.1 一些帮助命令
help: 显示帮助。
db.help() 显示数据库方法的帮助。
db.<collection>.help() 显示收集方法的帮助, <collection>可以是现有的集合或不存在的集合的名称。
show dbs 打印服务器上所有数据库的列表。
use <db> 将当前数据库切换到<db>。该 mongoshell 变量 db 被设置为当前数据库。
show collections 打印当前数据库的所有集合的列表。
show users 打印当前数据库的用户列表。
show roles 打印用于当前数据库的用户定义和内置的所有角色的列表。
show profile 打印需要 1 毫秒或更多的五个最近的操作。有关详细信息,请参阅数据库分析器上的文档。
show databases 打印所有可用数据库的列表。
5.2 插入数据
官方文档:
https://docs.mongodb.com/v3.4/tutorial/insert-documents/
MongoDB提供了将文档插入到集合中的以下方法: db.collection.insertOne() 将单个文档插入到集合中。 db.collection.insertMany() 将多个 文档插入到集合中。 db.collection.insert() 将单个文档或多个文档插入到集合中。 db.collection.save() 根据文档参数更新现有文档或插入新文档
5.2.1 单条插入
命令集合:
db.test.insert( {"name":"keme","age":18,"ad":"北京市朝阳区"} )
db.test.insert( {"name":"xiaoke","age":17,"ad":"北京市朝阳区"} )
db.test.insert( {"name":"aaa","age":20,"ad":"北京市朝阳区"} )
db.test.insert( {"name":"xiaoxi","age":21,"ad":"北京市朝阳区"} )
db.test.insert( {"name":"xiaojian","age":28,"ad":"北京市朝阳区","sex":"boy"} )
执行结果
登录mongo
[root@mongo-160 ~]# mongo localhost:27017
>db.test.insert( {"name":"keme","age":18,"ad":"北京市朝阳区"} )
>db.test.insert( {"name":"xiaoke","age":17,"ad":"北京市朝阳区"} )
>db.test.insert( {"name":"aaa","age":20,"ad":"北京市朝阳区"} )
>db.test.insert( {"name":"xiaoxi","age":21,"ad":"北京市朝阳区"} )
>db.test.insert( {"name":"xiaojian","age":28,"ad":"北京市朝阳区","sex":"boy"} )
#查看插入结果
> db.test.find()
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afa"), "name" : "keme", "age" : 18, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afb"), "name" : "xiaoke", "age" : 17, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afc"), "name" : "aaa", "age" : 20, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afd"), "name" : "xiaoxi", "age" : 21, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4eceada13ff76c3afe"), "name" : "xiaojian", "age" : 28, "ad" : "北京市朝阳区", "sex" : "boy" }
5.2.2 多行插入
官方文档例子
#命令
db.inventory.insertMany( [
{ "item": "journal", "qty": 25, "size": { "h": 14, "w": 21, "uom": "cm" }, "status": "A" },
{ "item": "notebook", "qty": 50, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "A" },
{ "item": "paper", "qty": 100, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "D" },
{ "item": "planner", "qty": 75, "size": { "h": 22.85, "w": 30, "uom": "cm" }, "status": "D" },
{ "item": "postcard", "qty": 45, "size": { "h": 10, "w": 15.25, "uom": "cm" }, "status": "A" }
]);
执行结果
> db.inventory.insertMany( [
... { "item": "journal", "qty": 25, "size": { "h": 14, "w": 21, "uom": "cm" }, "status": "A" },
... { "item": "notebook", "qty": 50, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "A" },
... { "item": "paper", "qty": 100, "size": { "h": 8.5, "w": 11, "uom": "in" }, "status": "D" },
... { "item": "planner", "qty": 75, "size": { "h": 22.85, "w": 30, "uom": "cm" }, "status": "D" },
... { "item": "postcard", "qty": 45, "size": { "h": 10, "w": 15.25, "uom": "cm" }, "status": "A" }
... ]);
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5cfdc5eaceada13ff76c3b02"),
ObjectId("5cfdc5eaceada13ff76c3b03"),
ObjectId("5cfdc5eaceada13ff76c3b04"),
ObjectId("5cfdc5eaceada13ff76c3b05"),
ObjectId("5cfdc5eaceada13ff76c3b06")
]
}
5.3 查询数据
db.collection.find(query , projection )
选择集合或视图中的文档,并将光标返回 到所选文档参数query类型是文件,可选的。用查询运算符指定选择过滤器要返回集合中的所有文档请忽略此参数或传递一个空的文档参数projection类型是文件,可选的。指定在与查询过滤器匹配的文档中返回的字段。要返回匹配文档中的所有字段, 返回: 一个光标匹配的文件query 标准。当find()方法“返回文档”时
,该方法实际上将光标返回到文档。 $or 或者关系, $in 匹配多个件键
虽然可以使用$or运算符来表达下面查询,但在同一字段上执行相等检查时,请使用$in运算符而不是$or运算符。
5.3.1 一般查询
查询所有
db.<collection>.find()
查询单条
db.<collection>.findOne()
> db.test.findOne()
{
"_id" : ObjectId("5cfdbd4bceada13ff76c3afa"),
"name" : "keme",
"age" : 18,
"ad" : "北京市朝阳区"
}
5.3.2 条件查询
很多都是看官方文档
> myCursor = db.inventory.find( { status: "D" } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b04"), "item" : "paper", "qty" : 100, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "status" : "D" }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b05"), "item" : "planner", "qty" : 75, "size" : { "h" : 22.85, "w" : 30, "uom" : "cm" }, "status" : "D" }
# 相当于SQL语句的 select * from inventory where status="D";
示例2
# 这是找出json 里面的值
> myCursor = db.inventory.find( { "size.uom": "in" } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b03"), "item" : "notebook", "qty" : 50, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "status" : "A" }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b04"), "item" : "paper", "qty" : 100, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "status" : "D" }
示例3:and
> myCursor = db.inventory.find( { status: "A", qty: { $lt: 30 } } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b02"), "item" : "journal", "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "status" : "A" }
相当于sql 语句
select * from inventory where status="A" and qty< 30;
示例4:or
> myCursor = db.inventory.find( { $or: [ { status: "A" }, { qty: { $lt: 30 } } ] } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b02"), "item" : "journal", "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "status" : "A" }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b03"), "item" : "notebook", "qty" : 50, "size" : { "h" : 8.5, "w" : 11, "uom" : "in" }, "status" : "A" }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b06"), "item" : "postcard", "qty" : 45, "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "status" : "A" }
相当于sql 语句:
select * from inventory where status=A or qty<30;
示例5:正则
myCursor = db.inventory.find( {status: "A",$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]} )
或者:
myCursor = db.inventory.find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} )
执行结果
> myCursor = db.inventory.find( {
... status: "A",
... $or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
... } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b02"), "item" : "journal", "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "status" : "A" }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b06"), "item" : "postcard", "qty" : 45, "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "status" : "A" }
# 相当于sql语句
SELECT * FROM inventory WHERE status = "A" AND ( qty < 30 OR item LIKE "p%")
5.3.3 比较运算符
-
$eq 匹配等于指定值的值。
-
$gt 匹配大于指定值的值。
-
$gte 匹配大于或等于指定值的值。
-
$in 匹配数组中指定的任何值。
-
$lt 匹配小于指定值的值。
-
$lte 匹配小于或等于指定值的值。
-
$ne 匹配不等于指定值的所有值。
-
$nin不匹配数组中指定的值。
5.3.4 逻辑查询运算符
-
$and 使用逻辑连接查询子句AND返回与两个子句的条件相匹配的所有文档。
-
$not 反转查询表达式的效果,并返回与查询表达式不匹配的文档。
-
$nor 使用逻辑连接查询子句NOR返回所有无法匹配两个子句的文档。
-
$or 使用逻辑连接查询子句OR返回与任一子句的条件相匹配的所有文档
5.4 更新数据
MongoDB提供以下方法来更新集合中的文档:
db.collection.updateOne(<filter>, <update>, <options>)即使可能有多个文档通过过滤条件匹配到,但是也最多也只更新一个文档
db.collection.updateMany(<filter>, <update>, <options>) 更新所有通过过滤条件匹配到的文档
db.collection.replaceOne(<filter>, <replacement>, <options>) 即使可能有多个文档通过过滤条件匹配到,但是也最多也只替换一个文档
db.collection.update()即使可能有多个文档通过过滤条件匹配到,但是也最多也只更新或者替换一个文档。
示例1:更新单条数据
db.inventory.updateOne(
{ "item" : "paper" }, // specifies the document to update
{
$set: { "size.uom" : "cm", "status" : "P" },
$currentDate: { "lastModified": true }
}
)
执行结果
> db.inventory.updateOne(
... { "item" : "paper" }, // specifies the document to update
... {
... $set: { "size.uom" : "cm", "status" : "P" },
... $currentDate: { "lastModified": true }
... }
... )
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
# 查看更新是否成功
> myCursor = db.inventory.find( { "item": "paper" } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b04"), "item" : "paper", "qty" : 100, "size" : { "h" : 8.5, "w" : 11, "uom" : "cm" }, "status" : "P", "lastModified" : ISODate("2019-06-10T03:32:31.190Z") }
更新成功了
示例2:更新多条数据
db.inventory.updateMany(
{ "qty" : { $lt: 50 } }, // specifies the documents to update
{
$set: { "size.uom" : "cm", "status": "P" },
$currentDate : { "lastModified": true }
}
)
执行结果
> db.inventory.updateMany(
... { "qty" : { $lt: 50 } }, // specifies the documents to update
... {
... $set: { "size.uom" : "cm", "status": "P" },
... $currentDate : { "lastModified": true }
... }
... )
{ "acknowledged" : true, "matchedCount" : 2, "modifiedCount" : 2 }
#查看修改的数据
> myCursor = db.inventory.find( { "qty": { $lt: 50 } } )
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b02"), "item" : "journal", "qty" : 25, "size" : { "h" : 14, "w" : 21, "uom" : "cm" }, "status" : "P", "lastModified" : ISODate("2019-06-10T03:35:53.575Z") }
{ "_id" : ObjectId("5cfdc5eaceada13ff76c3b06"), "item" : "postcard", "qty" : 45, "size" : { "h" : 10, "w" : 15.25, "uom" : "cm" }, "status" : "P", "lastModified" : ISODate("2019-06-10T03:35:53.575Z") }
5.5 删除数据
MongoDB提供以下方法来删除集合的文档:
db.collection.remove() 删除单个文档或与指定过滤器匹配的所有文档。 参数{},清空集合
db.collection.drop()此方法获取受影响的数据库上的写入锁定,并将阻止其他操作,直到
其完成。 不加参数删除所有数据包括索引
db.collection.deleteOne() 最多删除与指定过滤器匹配的单个文档,即使多个文档可能与指定的过滤器匹配。
db.collection.deleteMany() 删除与指定过滤器匹配的所有文档。
示例
> show dbs
admin 0.000GB
local 0.000GB
test 0.000GB
> use test
switched to db test
> show collections
inventory
test
# 删除单条数据
db.inventory.deleteOne(
{ "status": "D" } // specifies the document to delete
)
# 删除多条数据
db.inventory.deleteMany(
{ "status" : "P" } // specifies the documents to delete
)
6. Mongodb 索引
默认情况下,创建索引将阻止数据库上的所有其他操作。在集合上构建索引时,保存集合的数据库对于读取或写入操作是不可用的,直到索引构建完成。任何需要对所有数据库(例如listDatabases)进行读或写锁定的操作将等待前台索引构建完成。
对于可能需要长时间运行的索引创建操作,可以考虑 background 选项,这样MongoDB数据库在索引创建期间仍然是可用的。例如,在 people 集合的 zipcode 键上创建一个索引,这个过程在后台运行,可以使用如下方式:
db.people.createIndex( { zipcode: 1}, {background: true} )
默认 MongoDB 索引创建的 background 是 false
索引优化: db.test.find({“id”:100}).explain()
6.1 MongoDB 有哪些索引:
单键索引(Single Field Indexes):
在一个键上创建的索引就是单键索引,单键索引是最常见的索引,如MongoDB默认创建的_id的索引就是单键索引。
复合索引(Compound Indexes):
在多个键上建立的索引就是复合索引。
多键索引(Multikey Index):
如果在一个数组上面创建索引, MongoDB会自己决定,是否要把这个索引建成多键索引。
地理空间索引(Geospatial Indexes and Queries):
MongoDB支持几种类型的地理空间索引。其中最常用的是 2dsphere 索引(用于地球表面类型的地图)和 2d 索引(用于平面地图和时间连续的数据)经度和纬度。
2d:
2d 索引用于扁平化表面,而不是球体表面,否则极点附近会出现大量的扭曲变形。
全文索引(Text Indexes):
当文本块比较大的时候,正则表达式搜索会非常慢,而且无法处理语言理解的问题(如entry 和 entries 应该算是匹配的)。使用全文索引可以非常快地进行文本搜索,就如同内置了多种语言分词机制的支持一样。创建索引的开销都比较大,全文索引的开销更大。创建索引时,需后台或离线创建。
哈希索引(Hashed Index):
哈希索引可以支持相等查询,但是哈希索引不支持范围查询。您可能无法创建一个带有哈希索引键的复合索引或者对哈希索引施加唯一性的限制。但是,您可以在同一个键上同时创建一个哈希索引和一个递增/递减(例如,非哈希)的索引,这样MongoDB对于范围查询就会自
动使用非哈希的索引。
示例:创建一个索引
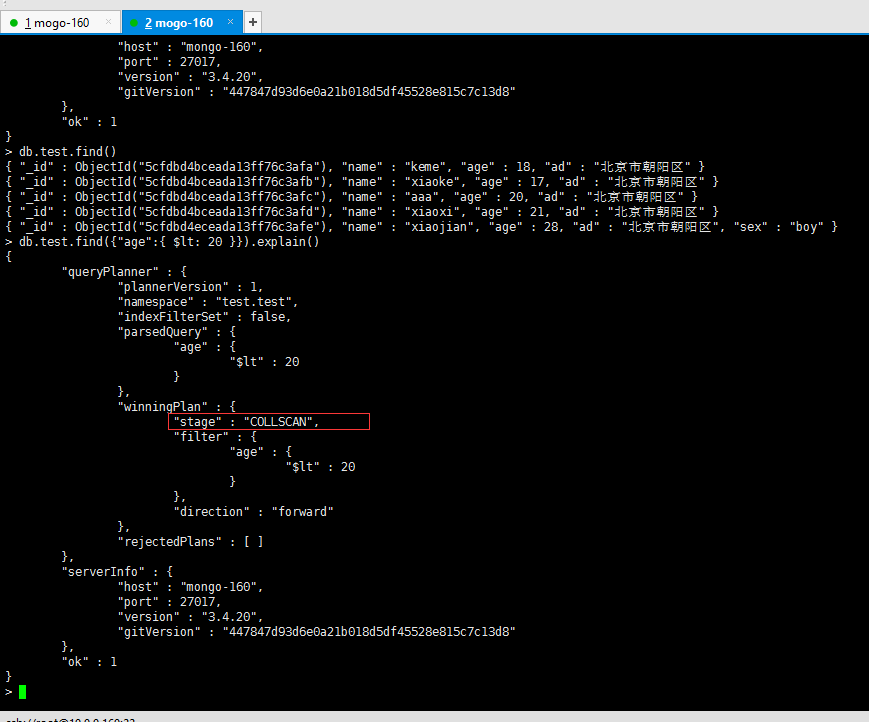
# 查看默认集合文档信息,也就是没有索引
> db.test.find()
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afa"), "name" : "keme", "age" : 18, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afb"), "name" : "xiaoke", "age" : 17, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afc"), "name" : "aaa", "age" : 20, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afd"), "name" : "xiaoxi", "age" : 21, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4eceada13ff76c3afe"), "name" : "xiaojian", "age" : 28, "ad" : "北京市朝阳区", "sex" : "boy" }
> db.test.find({"age":{ $lt: 20 }}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "test.test",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$lt" : 20
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"age" : {
"$lt" : 20
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "mongo-160",
"port" : 27017,
"version" : "3.4.20",
"gitVersion" : "447847d93d6e0a21b018d5df45528e815c7c13d8"
},
"ok" : 1
}
创建一个索引
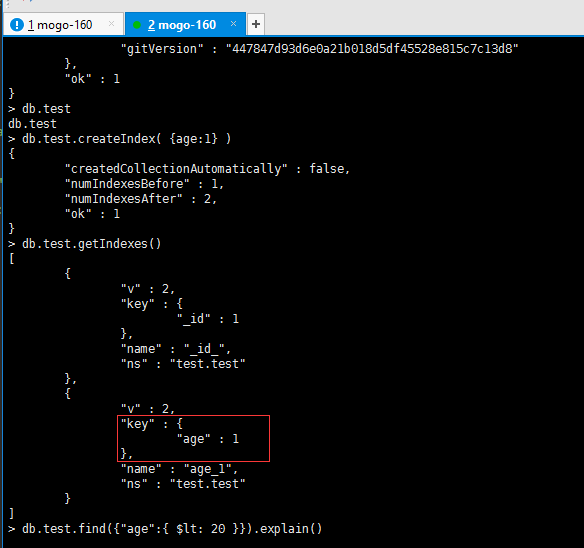
> db.test.createIndex( {age:1} )
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
# 得到集合的所有索引
> db.test.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "test.test"
},
{
"v" : 2,
"key" : {
"age" : 1
},
"name" : "age_1",
"ns" : "test.test"
}
]
再次查看执行计划
> db.test.find({"age":{ $lt: 20 }}).explain()
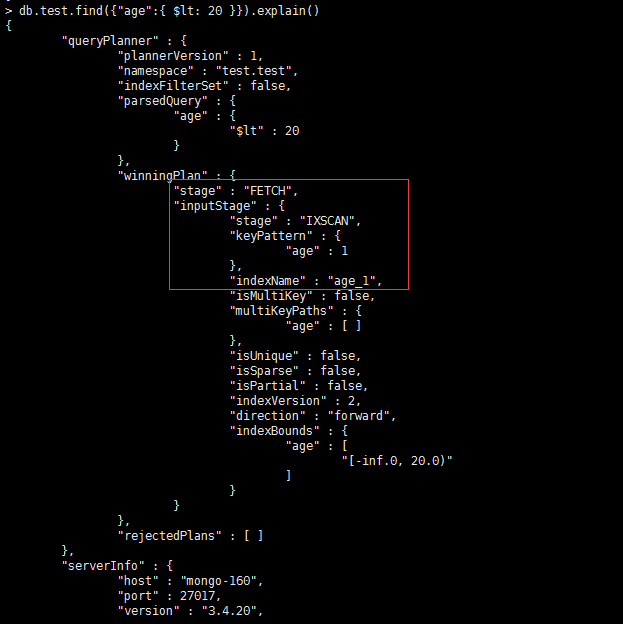
删除索引
> db.test.dropIndex( {age:1} )
{ "nIndexesWas" : 2, "ok" : 1 }
7 MongoDB 组件
官方文档:
https://docs.mongodb.com/v3.4/reference/program/
7.1 mongo
mongo 是MongoDB的交互式JavaScript shell接口,为系统管理员提供强大的界面,也为开发
人员直接用数据库测试查询和操作的方式。 mongo还提供了一个功能齐全的JavaScript环境,与MongoDB一起使用。本文档介绍了mongoshell 的基本调用及其用法概述。
7.2 mongod
mongod 是 Mongodb 系统的主要守护进程,它处理数据请求,管理数据访问,并执行后台管理操作。启动进程指定配置文件,控制数据库的行为
7.3 mongos
mongos 对于“MongoDB Shard”,是用于处理来自应用层的查询的MongoDB分片配置的路由服务,并确定此数据在分片集群中的位置, 以完成这些操作。从应用程序的角度来看,一个 mongos实例与任何其他MongoDB实例的行为相同。
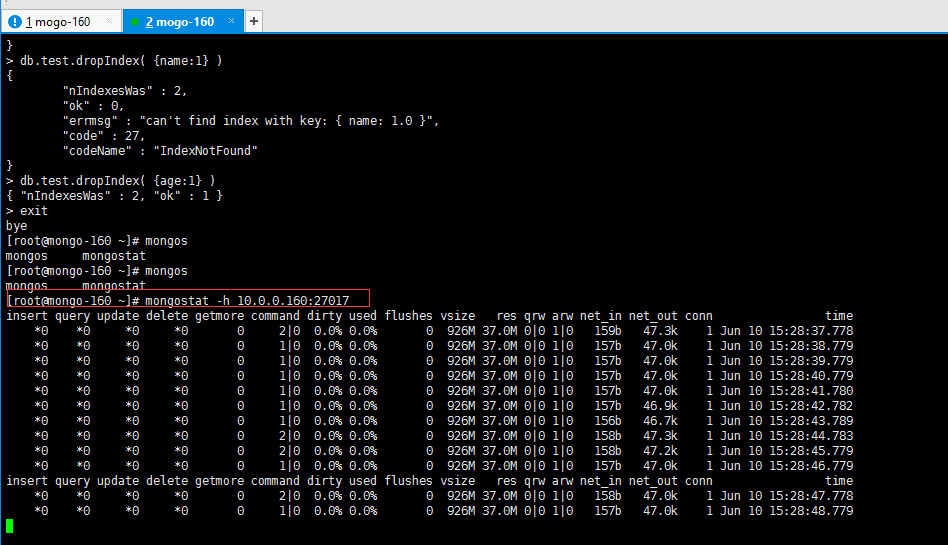
7.4 mongostat
mongostat 实用程序可以快速概览当前正在运行的mongod 或mongos 实例的状态。mongostat在功能上类似于UNIX / Linux文件系统实用程序vmstat,但提供有关的数据 mongod和mongos实例。
[root@mongo-160 ~]# mongostat -h 10.0.0.160:27017
#如果开启用户认证:需要添加-u -p --authenticationDatabase=
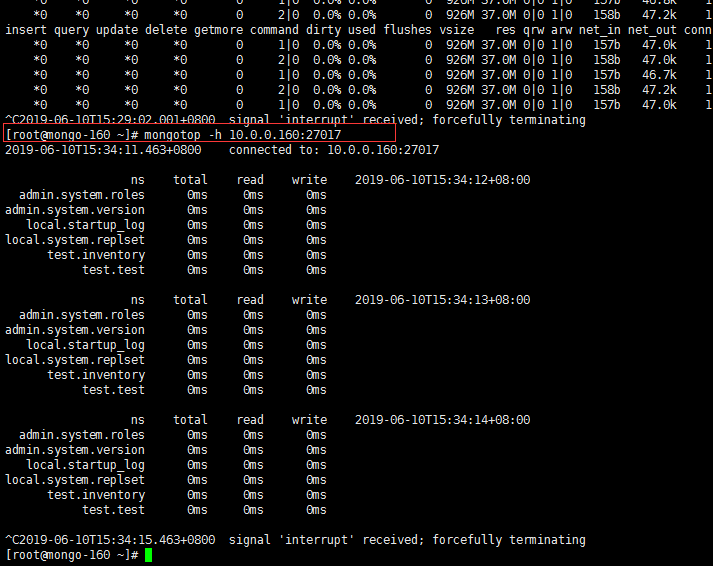
7.5 mongotop
mongotop提供了一种跟踪MongoDB实例读取和写入数据的时间量的方法。 mongotop 提供每个收集级别的统计信息。默认情况下, mongotop每秒返回一次值
[root@mongo-160 ~]# mongotop -h 10.0.0.160:27017
如果开启用户认证:需要添加 -u -p --authenticationDatabase=
自己的实验机器没什么读写
7.6 mongoplog
mongooplog是一个简单的工具,可以从远程服务器的复制 oplog轮询操作,并将其应用于本地服务器。此功能支持某些类型的实时迁移,这些迁移要求源服务器保持联机并在整个迁移过程中运行。通常,此命令将采用以下形式:mongooplog - from mongodb0.example.net --host mongodb1.example.net
mongoperf是一种独立于MongoDB检查磁盘I / O性能的实用程序。它是随机磁盘I / O的测试 ,并呈现结果。
例如:
echo “{nThreads: 16, fileSizeMB: 10000, r: true, w: true}” | mongoperf
在这个操作中:
mongoperf 测试直接物理随机读写io的,使用16个并发阅读器线程。
mongoperf 使用10 GB的测试文件。
或者参数写入文件里 mongoperf < config
7.7 mongoexport
mongoexport是一个实用程序,可以导出存储在MongoDB实例中的数据,生成一个JSON或
CSV
# 导出test库下的test集合中 ,条件为 age 大于等于17 并且小于等于20 ,导出文件为test.json
[root@mongo-160 ~]# mongoexport -h 10.0.0.160:27017 -d test -c test -o test.json -q '{"age" : {$gte:17,$lte:20}}'
2019-06-10T16:46:32.312+0800 connected to: 10.0.0.160:27017
2019-06-10T16:46:32.312+0800 exported 3 records
# 查看导出的内容
[root@mongo-160 ~]# cat test.json
{"_id":{"$oid":"5cfdbd4bceada13ff76c3afa"},"name":"keme","age":18.0,"ad":"北京市朝阳区"}
{"_id":{"$oid":"5cfdbd4bceada13ff76c3afb"},"name":"xiaoke","age":17.0,"ad":"北京市朝阳区"}
{"_id":{"$oid":"5cfdbd4bceada13ff76c3afc"},"name":"aaa","age":20.0,"ad":"北京市朝阳区"}
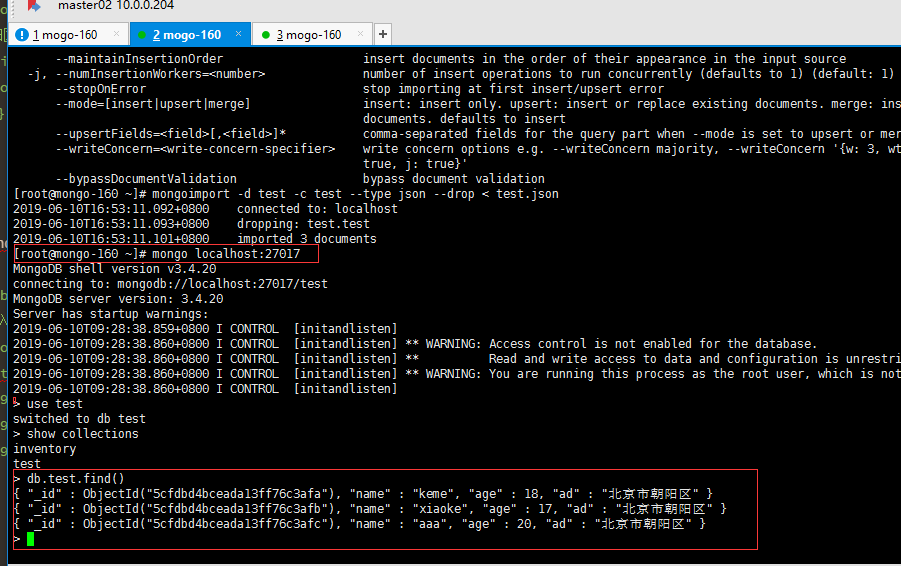
7.8 mongoimport
mongoimport工具从由其他第三方导出工具创建或可能的扩展JSON, CSV或TSV导出导入内容
#导入到test库下的test集合,导入之前删除原来的集合
[root@mongo-160 ~]# mongoimport -d test -c test --type json --drop < test.json
2019-06-10T16:53:11.092+0800 connected to: localhost
2019-06-10T16:53:11.093+0800 dropping: test.test
2019-06-10T16:53:11.101+0800 imported 3 documents
避免使用mongoimport和mongoexport完全实例生产备份。它们不可靠地保存所有丰富的 BSON数据类型,因为JSON只能表示BSON支持的类型的一个子集,使用该 –type=csv选项为输出指定CSV格式
7.9 bsondump
bsondump 转换BSON文件转换为我们可直接读的格式,包括JSON。例如,
bsondump对于读取mongodump输出文件很有用。bsondump 是用于检查BSON文件的诊断工具,而不是用于数据摄取或其他应用程序使用的工具
找个备份文件
# 我这没有bson 文件,先标注用法
shell> bsondump xxxx.bson > xxxx.json
mongofiles 实用程序可以从命令行操作在GridFS对象中存储在MongoDB实例中的文件。它特别有用,因为它提供了存储在文件系统和GridFS之间的对象之间的接口。
8. MongoDB 授权认证
官方文档:
https://docs.mongodb.com/v3.4/tutorial/enable-authentication/
8.1 授权介绍
认证是验证客户端身份的过程。当启用访问控制(即授权)时,MongoDB要求所有客户端进
行身份验证,以确定其访问。认证方法:为了验证用户,MongoDB提供了该 db.auth()方法。
对于mongoshell和MongoDB工具,可以通过从命令行传入用户身份验证信息来验证用户,认证机制
MongoDB支持多种认证机制:
-
SCRAM-SHA-1
3.0版中更改: 3.0中创建的新挑战响应用户将使用 SCRAM-SHA-1。如果使用2.6用户数据,MongoDB 3.0将继续使用MONGODB-CR。 -
x.509证书认证。
除了支持上述机制外,MongoDB Enterprise还支持以下机制:
- LDAP代理身份验证和Kerberos身份验证。
- 内部认证
除了验证客户端的身份之外,MongoDB还可以要求副本集和分片集群的成员对其各自的副本
集或分片集群进行身份验证。有关 详细信息,请参阅分片集上的认证
在分片集群中,客户端通常直接对mongos实例进行身份验证 。但是,某些维护操作可能需
要直接对特定的分片进行身份验证。
用户管理界面
要添加用户, MongoDB 提供了该 db.createUser()方法。添加用户时,您可以为用户分配色以授予权限。
注意:
在数据库中创建的第一个用户应该是具有管理其他用户的权限的用户管理员。
你还可以更新现有用户,例如更改密码并授予或撤销角色
认证数据库
添加用户时,可以在特定数据库中创建用户。该数据库是用户的身份验证数据库。
用户可以跨不同数据库拥有权限; 即用户的权限不限于认证数据库。通过分配给其他数据库中的用户角色,在一个数据库中创建的用户可以具有对其他数据库的操作权限。
用户名和认证数据库作为该用户的唯一标识符。也就是说,如果两个用户具有相同的名称,
但是在不同的数据库中创建,则它们是两个不同的用户。如果您打算拥有具有多个数据库权
限的单个用户,请在适用的数据库中创建具有角色的单个用户,而不是在不同数据库中多次
创建用户。
一些相关方法
db.auth() 将用户验证到数据库。
db.changeUserPassword() 更改现有用户的密码。
db.createUser() 创建一个新用户。
db.dropUser() 删除单个用户。
db.dropAllUsers() 删除与数据库关联的所有用户。
db.getUser() 返回有关指定用户的信息。
db.getUsers() 返回有关与数据库关联的所有用户的信息。
db.grantRolesToUser() 授予用户角色及其特权。
db.removeUser() 已过时。从数据库中删除用户。
db.revokeRolesFromUser() 从用户中删除角色。
db.updateUser() 更新用户数据。
db.createRole() 创建角色并指定其特权。
db.dropRole() 删除用户定义的角色。
db.dropAllRoles() 删除与数据库关联的所有用户定义的角色。
db.getRole() 返回指定角色的信息。
db.getRoles() 返回数据库中所有用户定义角色的信息。
db.grantPrivilegesToRole() 将权限分配给用户定义的角色。
db.revokePrivilegesFromRole() 从用户定义的角色中删除指定的权限
db.grantRolesToRole() 指定用户定义的角色从中继承权限的角色。
db.revokeRolesFromRole() 从角色中删除继承的角色。
db.updateRole() 更新用户定义的角色
8.2 用户角色
8.2.1 数据库用户角色
- read:提供对所有读取数据的能力非 -系统集合和下列系统集合: system.indexes, system.js和 system.namespaces收藏。该角色通过授予以下操作来提供读访问权限:
- readWrite:提供read角色的所有权限以及修改所有非系统集合和system.js集合上的数据的功能。
8.2.3 数据库管理角色
dbAdmin, dbOwner, userAdminAnyDatabase
提供在当前数据库上创建和修改角色和用户的功能。该角色还间接地提供 对数据库的超级用户访问,或者如果作用于admin数据库的集群。该userAdmin角色允许用户授予任何用户任何特权,包括自己。
8.2.4 集群管理角色
该admin数据库包括用于管理整个系统,而不仅仅是一个单一的数据库以下角色。这些角色包括但不限于复制集和分片集群管理功能。
-
clusterAdmin :提供最大的集群管理访问。这个角色组合由授予的权限clusterManager, clusterMonitor和hostManager角色。另外,角色提供了dropDatabase动作。
-
clusterManager : 在集群上提供管理和监控动作。具有该角色的用户可以访问config和local数据库,其在分片和复制所使用的
8.2.5 内部角色
- __system: MongoDB将此角色分配给表示集群成员的用户对象,如副本集成员和mongos实例。角色授权其持有人对数据库中的任何对象采取任何行动
8.2.6 自定义角色
# 创建角色
db.createRole( { role: “test”, privileges: [ { resource: { db: “test”, collection: “” }, actions: [ “insert”,“update”,remove] }, ], roles: [ { role: “read”, db: “test” } ] }, { w: “majority” , wtimeout: 5000 })
# 创建用户,添加到相应角色
db.createUser({user:"ke",pwd:"123456",roles:[ { role:"test", db:"test" }]})
#上面自定义角色这个模拟的语法示例,没在实验环境做演示
8.3 创建用户和角色
[root@mongo-160 ~]# mongo localhost:27017
#查看当前mongo实例有哪些用户
> db.getUsers()
[ ]
空的,没有用户
# 创建用户
> db.createUser({user: "admin",pwd: "123456",roles:[ { role: "root", db:"admin"}]})
Successfully added user: {
"user" : "admin",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
]
}
# 查看用户
> db.getUsers()
[
{
"_id" : "test.admin",
"user" : "admin",
"db" : "test",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
]
}
]

8.4 用户认证配置文件
末尾添加如下两行内容
[root@mongo-160 ~]# vim /opt/mongodb/conf/mongodb.conf
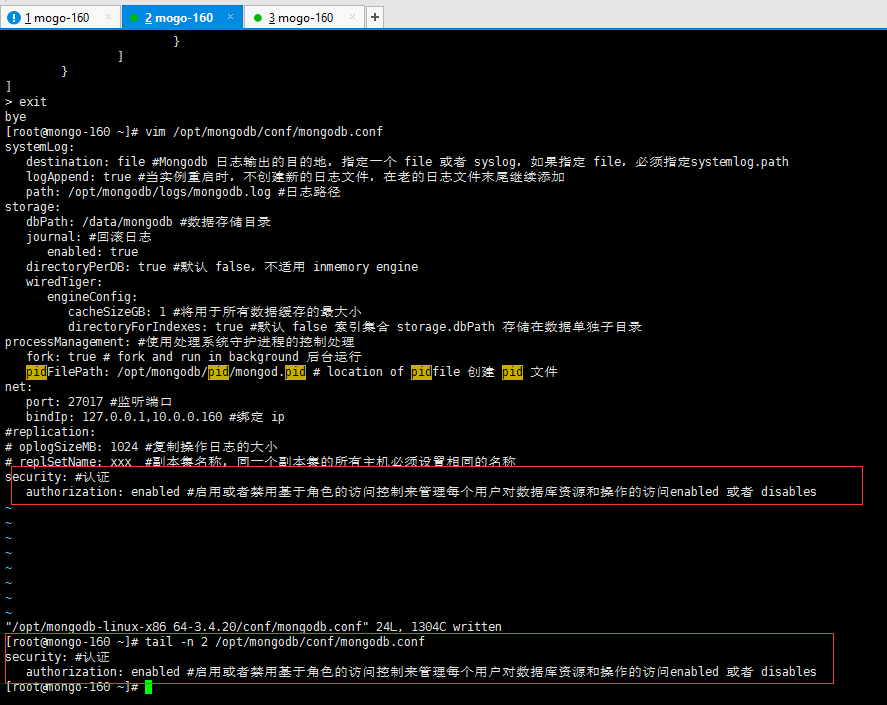
security: #认证
authorization: enabled #启用或者禁用基于角色的访问控制来管理每个用户对数据库资源和操作的访问enabled 或者 disables
#重启生效
[root@mongo-160 ~]# mongod -f /opt/mongodb/conf/mongodb.conf --shutdown
killing process with pid: 79647
[root@mongo-160 ~]# mongod -f /opt/mongodb/conf/mongodb.conf
about to fork child process, waiting until server is ready for connections.
forked process: 93037
child process started successfully, parent exiting
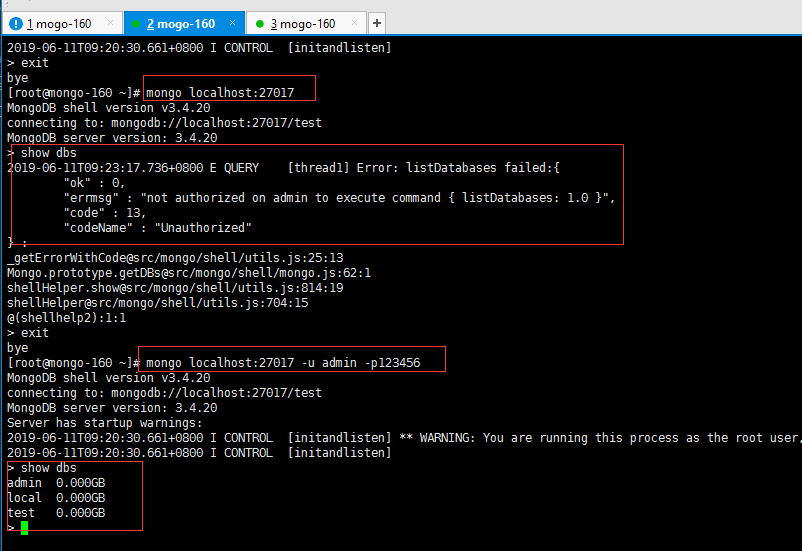
8.5 使用账号密码连接MongoDB
配置问权限认证后需要重启节点,再次登陆如果不使用账号密码就查看不了数据
[root@mongo-160 ~]# mongo localhost:27017 -u admin -p123456
> show dbs
admin 0.000GB
local 0.000GB
test 0.000GB
设置不同账号权限
# 用admin用户 创建一个schools 库, 创建一个students集合,插入一条数据
> use school
switched to db school
> show collections
> db.students.insert ( {"name":"keme"} )
WriteResult({ "nInserted" : 1 })
# 查看集合
> show collections
students
然后创建不同账号权限
use test
# 创建一个用户keme,在test 数据库下有读写, 在school 下只有读取
db.createUser(
{
user: "keme",
pwd: "123456",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "school" } ]
}
)
执行结果
> use test
switched to db test
> db.createUser(
... {
... user: "keme",
... pwd: "123456",
... roles: [ { role: "readWrite", db: "test" },
... { role: "read", db: "school" } ]
... }
... )
Successfully added user: {
"user" : "keme",
"roles" : [
{
"role" : "readWrite",
"db" : "test"
},
{
"role" : "read",
"db" : "school"
}
]
}
登陆keme用户查看
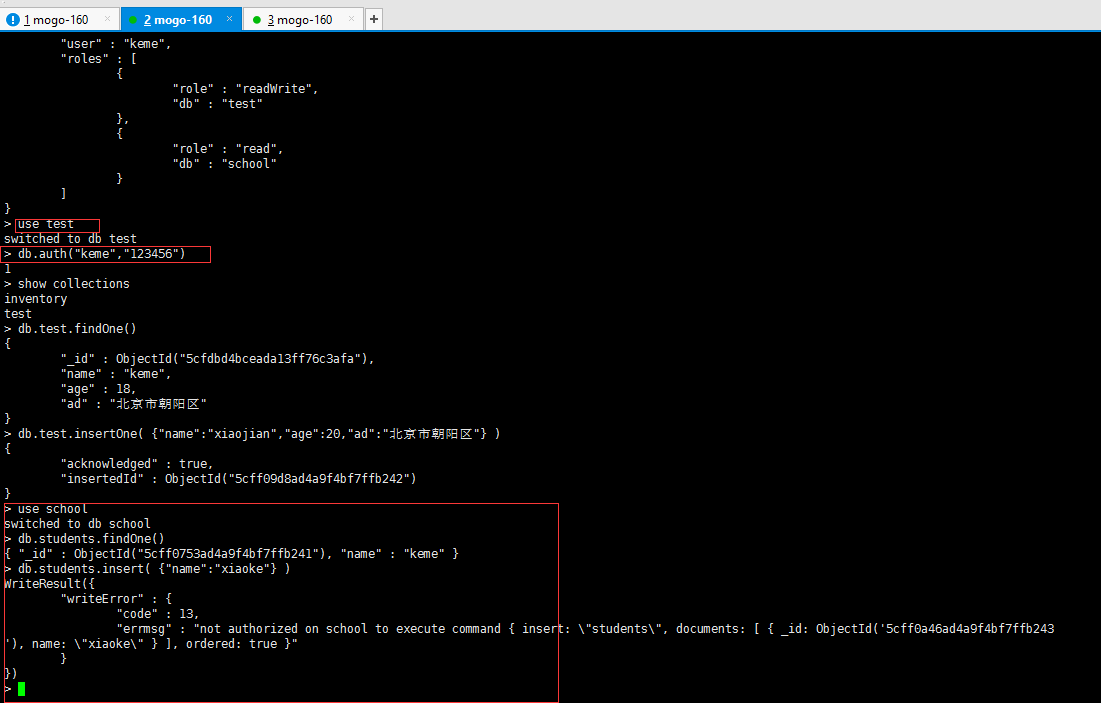
> use test
switched to db test
> db.auth("keme","123456")
1
> show collections
inventory
test
# 验证读
> db.test.findOne()
{
"_id" : ObjectId("5cfdbd4bceada13ff76c3afa"),
"name" : "keme",
"age" : 18,
"ad" : "北京市朝阳区"
}
# 验证写
> db.test.insertOne( {"name":"xiaojian","age":20,"ad":"北京市朝阳区"} )
{
"acknowledged" : true,
"insertedId" : ObjectId("5cff09d8ad4a9f4bf7ffb242")
}
# 切换到 school 库,发现可读不可写
> use school
switched to db school
#读取
> db.students.findOne()
{ "_id" : ObjectId("5cff0753ad4a9f4bf7ffb241"), "name" : "keme" }
#写入,报错
> db.students.insert( {"name":"xiaoke"} )
WriteResult({
"writeError" : {
"code" : 13,
"errmsg" : "not authorized on school to execute command { insert: \"students\", documents: [ { _id: ObjectId('5cff0a46ad4a9f4bf7ffb243'), name: \"xiaoke\" } ], ordered: true }"
}
})
9. mongod 运维
9.1 数据备份
简单的导入导出可以用mongoexport 和 mongoimport
9.1.2 mongodump 备份工具
mongodump的参数与mongoexport的参数基本一致
常用参数
参数 参数说明
-h 指明数据库宿主机的IP
-u 指明数据库的用户名
-p 指明数据库的密码
-d 指明数据库的名字
-c 指明collection的名字
-o 指明到要导出的文件名
-q 指明导出数据的过滤条件
--authenticationDatabase 验证数据的名称
--gzip 备份时压缩
举例:
# 创建一个备份目录点
[root@mongo-160 ~]# mkdir -p /data/backup/mongo/
[root@mongo-160 ~]# mongo 10.0.0.160:27017 -u admin -p 123456
>use admin
#创建相应的管理用户
>db.createUser(
{
user: "kemeadmin",
pwd: "123456",
roles: [ { role: "root", db: "admin" } ]
}
)
> exit
bye
#进行全备
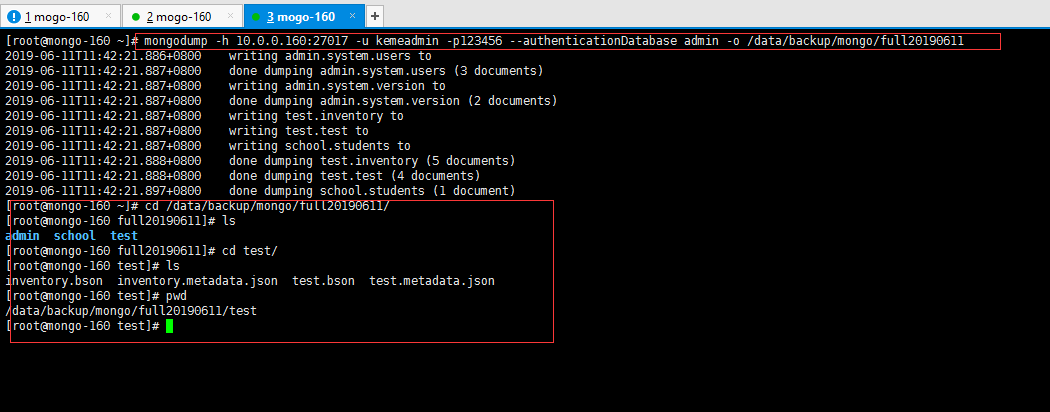
[root@mongo-160 ~]# mongodump -h 10.0.0.160:27017 -u kemeadmin -p123456 --authenticationDatabase admin -o /data/backup/mongo/full20190611
#查看是否备份成功
[root@mongo-160 ~]# cd /data/backup/mongo/full20190611/
[root@mongo-160 full20190611]# ls
admin school test
[root@mongo-160 full20190611]# cd test/
[root@mongo-160 test]# ls
inventory.bson inventory.metadata.json test.bson test.metadata.json
[root@mongo-160 test]# pwd
/data/backup/mongo/full20190611/test
备份某个库
# 备份test 库
mongodump -h 10.0.0.160:27017 -u kemeadmin -p123456 --authenticationDatabase admin -d test -o /data/backup/mongo
[root@mongo-160 ~]# cd /data/backup/mongo/
[root@mongo-160 mongo]# ls
full20190611 test
[root@mongo-160 mongo]# cd test/
[root@mongo-160 test]# ls
inventory.bson inventory.metadata.json test.bson test.metadata.json
# 备份test库下的inventory 集合
[root@mongo-160 ~]# mongodump -h 10.0.0.160:27017 -ukemeadmin -p123456 --authenticationDatabase admin -d test -c inventory -o /data/backup/mongo/
压缩备份
#压缩备份单个库
[root@mongo-160 ~]# mongodump -h 10.0.0.160:27017 -ukemeadmin -p123456 --authenticationDatabase admin -d school -o /data/backup/mongo/ --gzip
# 压缩备份某个集合也是一样的加上--gzip
9.2 数据恢复
9.2.1 mongorestore 恢复
mongorestore与mongoimport参数类似
常用参数如下:
参数 参数说明
-h 指明数据库宿主机的IP
-u 指明数据库的用户名
-p 指明数据库的密码
-d 指明数据库的名字
-c 指明collection的名字
-o 指明到要导出的文件名
-q 指明导出数据的过滤条件
--authenticationDatabase 验证数据的名称
--gzip 备份时压缩
--drop 恢复的时候把之前的集合drop掉
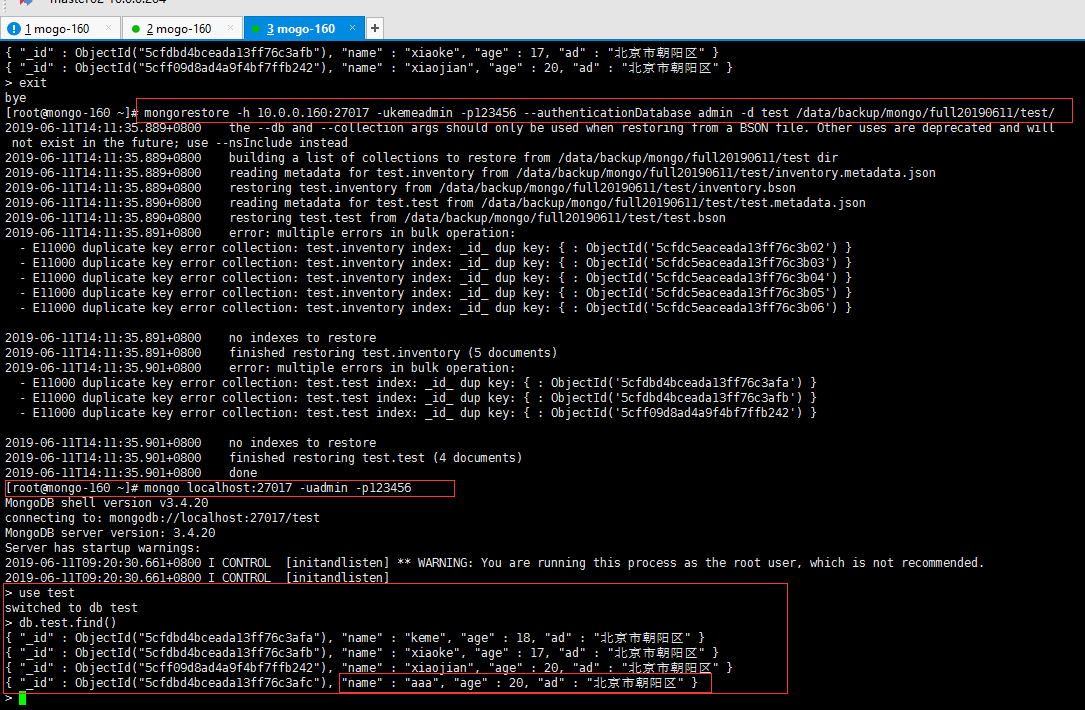
全库备份中恢复单库(基于之前的全库备份)
# 从全库中恢复test库
[root@mongo-160 ~]# mongorestore -h 10.0.0.160:27017 -ukemeadmin -p123456 --authenticationDatabase admin -d test --drop /data/backup/mongo/full20190611/test
恢复某个库,不删除之前的集合看看数据有什么变化
做之前删除一条数据,好验证
> use test
switched to db test
> db.test.find()
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afa"), "name" : "keme", "age" : 18, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afb"), "name" : "xiaoke", "age" : 17, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afc"), "name" : "aaa", "age" : 20, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cff09d8ad4a9f4bf7ffb242"), "name" : "xiaojian", "age" : 20, "ad" : "北京市朝阳区" }
# 删除名字是aaa的数据
> db.test.deleteOne( {"name":"aaa"} )
{ "acknowledged" : true, "deletedCount" : 1 }
> db.test.find()
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afa"), "name" : "keme", "age" : 18, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afb"), "name" : "xiaoke", "age" : 17, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cff09d8ad4a9f4bf7ffb242"), "name" : "xiaojian", "age" : 20, "ad" : "北京市朝阳区" }
恢复test库,看看有没有aaa这个数据
[root@mongo-160 ~]# mongorestore -h 10.0.0.160:27017 -ukemeadmin -p123456 --authenticationDatabase admin -d test /data/backup/mongo/full20190611/test/
#登录查看
[root@mongo-160 ~]# mongo localhost:27017 -uadmin -p123456
> use test
switched to db test
> db.test.find()
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afa"), "name" : "keme", "age" : 18, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afb"), "name" : "xiaoke", "age" : 17, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cff09d8ad4a9f4bf7ffb242"), "name" : "xiaojian", "age" : 20, "ad" : "北京市朝阳区" }
{ "_id" : ObjectId("5cfdbd4bceada13ff76c3afc"), "name" : "aaa", "age" : 20, "ad" : "北京市朝阳区" }
ok ,恢复成功
mongoexport/mongoimport与mongodump/mongorestore的对比
-
mongoexport/mongoimport导入/导出的是JSON格式,而mongodump/mongorestore导入/导出的是BSON格式。
-
JSON可读性强但体积较大,BSON则是二进制文件,体积小但对人几乎没有可读性。
-
在一些mongodb版本之间,BSON格式可能会随版本不同而有所不同,所以不同版本之间用mongodump/mongorestore可能不会成功,具体要看版本之间的兼容性。当无法使用BSON进行跨版本的数据迁移的时候,使用JSON格式即mongoexport/mongoimport是一个可选项。跨版本的mongodump/mongorestore并不推荐,实在要做请先检查文档看两个版本是否兼容(大部分时候是的)。
-
JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。使用时应该注意。
9.3 备份恢复小结
备份不是想我那样写的那么简单,我上面只写了一些工具的用法,一些日常的维护。从长远考虑,还需要考虑更多
可以看看阿里云的云mongodb 一些备份恢复文档
https://help.aliyun.com/document_detail/55008.html?spm=a2c4g.11186623.6.677.4039d6afePr5YU
9.4 MongoDB 监控
监控及时获得应用的运行状态信息,在问题出现时及时发现。
监控哪些
CPU、内存、磁盘I/O、应用程序(MongoDB)、进程监控(ps -aux)、错误日志监控
一些内部状态可以查看:
db.serverStatus()
查看实例运行状态(内存使用、锁、用户连接等信息) 通过比对前后快照进行性能分析
"connections" # 当前连接到本机处于活动状态的连接数
"activeClients" # 连接到当前实例处于活动状态的客户端数量
"locks" # 锁相关参数
"opcounters" # 启动之后的参数
"opcountersRepl" # 复制想关
"storageEngine" # 查看数据库的存储引擎
"mem" # 内存相关
db.stats()
显示信息说明:
"db" : "test" ,表示当前是针对"test"这个数据库的描述。想要查看其他数据库,可以先运行$ use databasename(e.g $use admiin).
"collections" : 3,表示当前数据库有多少个collections.可以通过运行show collections查看当前数据库具体有哪些collection.
"objects" : 5,表示当前数据库所有collection总共有多少行数据。显示的数据是一个估计值,并不是非常精确。
"avgObjSize" : 36,表示每行数据是大小,也是估计值,单位是bytes
"dataSize" : 468,表示当前数据库所有数据的总大小,不是指占有磁盘大小。单位是bytes
"storageSize" : 13312,表示当前数据库占有磁盘大小,单位是bytes,因为mongodb有预分配空间机制,为了防止当有大量数据插入时对磁盘的压力,因此会事先多分配磁盘空间。
"numExtents" : 3,似乎没有什么真实意义。我弄明白之后再详细补充说明。
"indexes" : 1 ,表示system.indexes表数据行数。
"indexSize" : 8192,表示索引占有磁盘大小。单位是bytes
"fileSize" : 201326592,表示当前数据库预分配的文件大小,例如test.0,test.1,不包括test.ns。
9.4.1 mongostat 工具
mongostat在功能上类似于UNIX / Linux文件系统实用程序vmstat
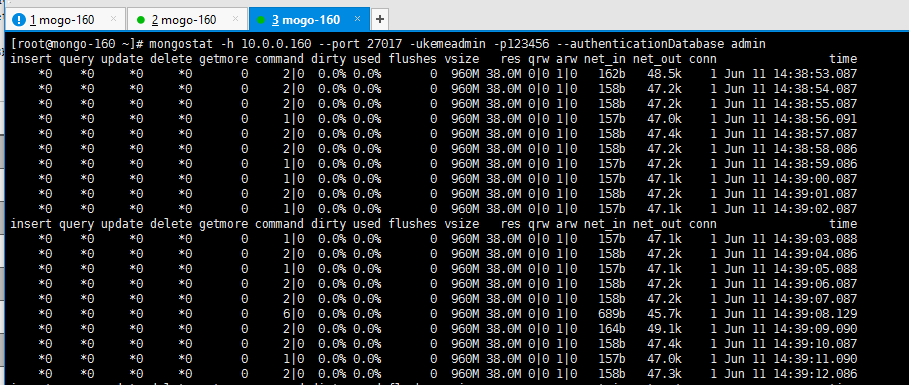
参数 参数说明
insert 每秒插入量
query 每秒查询量
update 每秒更新量
delete 每秒删除量
conn 当前连接数
qr|qw 客户端查询排队长度(读|写)最好为0,如果有堆积,数据库处理慢。
ar|aw 活跃客户端数量(读|写)
time 当前时间
9.4.2 mongotop
mongotop提供了一种跟踪MongoDB实例读取和写入数据的时间量的方法。
[root@mongo-160 ~]# mongotop -h 10.0.0.160:27017 -ukemeadmin -p123456 --authenticationDatabase admin
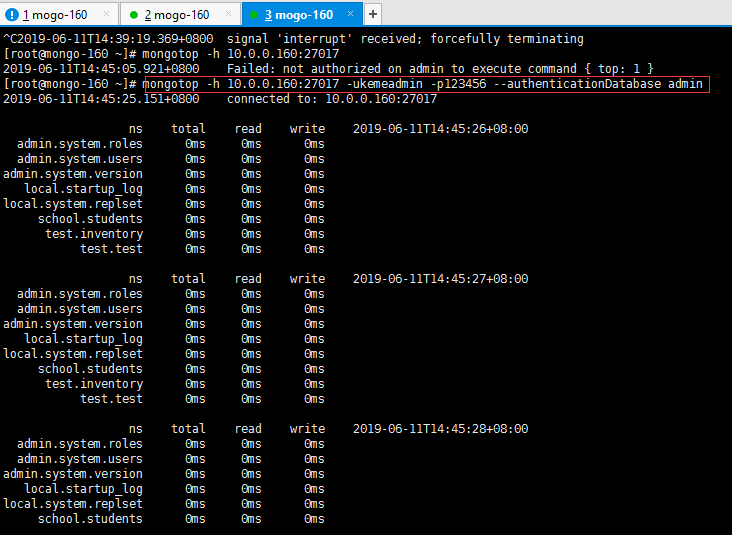
参数说明:
ns:数据库命名空间,后者结合了数据库名称和集合。
total:mongod在这个命令空间上花费的总时间。
read:在这个命令空间上mongod执行读操作花费的时间。
write:在这个命名空间上mongod进行写操作花费的时间。
9.4.3 db 级别命令
db.currentOp()
查看数据库当前执行什么操作。
用于查看长时间运行进程。
通过(执行时长、操作、锁、等待锁时长)等条件过滤。
如果发现一个操作太长,把数据库卡死的话,可以用这个命令杀死他:> db.killOp()
db.serverStatus()
db.stats()
10. 小结
-
禁止内存大页和root 用户操作
-
源码包安装(二进制)
-
备份、可能的话不同机房备份
-
开启认证、自定义角色、权限最小化、防火墙限制IP
-
索引后台创建,去掉程序用户创建索引权限
-
后台操作最好在业务低峰期
-
数据库监控
其实上面我全是用root 用户登录操作的,这只是为了我自己环境操作方便。应该有专门的程序用户来操作和管理mongodb应用。
转载于:https://www.cnblogs.com/keme/p/11004955.html
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100872.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
