概念
自动化测试模型可以看作自动化框架与工具设计得思想。自动化不仅仅式单纯的写写脚本运行就可以了,还需要考虑如何使脚本运行效率提高,代码复用、参数化等问题。自动化模型主要分为四大类:线性模型,模块化驱动,驱动数据,关键字驱动。
线性模型
线性脚本中每个脚本相互独立,且不会产生其他依赖与调用,其实就是简单的模拟用户某个操作流程的脚本。贴代码:
# -*- coding: utf-8 -*-
# @Time : 2019/1/10 11:27 PM
# @Author : 余少琪
# @FileName: test.py
# @email : 1603453211@qq.com
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
#使用class_name定位元素
driver.find_element_by_class_name("s_ipt").send_keys("selenium")
sleep(3)
driver.find_element_by_id("su").click()
sleep(2)
driver.quit()
模块化驱动测试
线性模型虽然每个用例都可以拿来单独运行,但是用例之间重复代码很多,开发、维护成功高。其实把重复操作代码封装为独立公共模块,
当用例执行时需要用到这部分,直接调用即可,这就是模块驱动的方式。比如登录系统,退出登录,截图函数等。
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('http://localhost:8080/login')
time.sleep(3)
class UserLogin:
def __init__(self,mobile,password):
self.mobile = mobile
self.password = password
"""输入登录账号"""
def user_mobile(self):
user_mobile_01 = driver.find_element_by_xpath('//*[@id="name"]')
user_mobile_01.send_keys(self.mobile)
"""登录密码"""
def user_password(self):
user_psaaword_01 = driver.find_element_by_xpath('//*[@id="pwd"]')
user_psaaword_01.send_keys(self.password)
"""点击登录"""
def login_botton(self):
driver.find_element_by_xpath('//*[@id="login"]').click()
Login = UserLogin
Login.user_mobile()
Login.user_name = 1770****92
Login.password()
Login.login_word = 123456
print(Login)
Login.login_botton()
time.sleep(10)
driver.close()
数据驱动
模块驱动的模型虽然解决了脚本重复问题,但是需要测试不同数据的用例时,模块驱动的方式就不合适了。数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。装载数据的方式可以是列表,字典或者外部文件(txt、csv、xml、excel),目的就是实现数据和脚本的分离。
这里,我们会使用@ddt装饰器和结合excel读取数据,来实现数据驱动。
安装依赖:
pip insatll xlrd
pip install ddt
- @ddt
数据驱动原理
1、测试数据为多个字典的list类型
2、测试类前面加@ddt.ddt修饰
3、case前加@ddt.data()修饰
4、用例会单独运行多次(取决于测试数据的个数)
# -*- coding:utf-8 -*-
import unittest
import ddt
from po.login_page import LoginPage
from selenium import webdriver
'''测试数据'''
test_data = [{
"username": "zhangsan", "password": "zhangsan"},
{
"username": "lisi", "password": "lisi"},
{
"username": "wangwu", "password": "wangwu"},
]
@ddt.ddt
class Case01(unittest.TestCase):
''''登录乐学'''
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.url = "http://www.5itest.cn/login"
# self.username = "183****9237"
# self.password = "123456"
#用例执行体
@ddt.data(*test_data)
# 这边@ddt会将test_data进行解包
def test_login_lexue(self, data):
#声明登录页面类对象
login_page = LoginPage(self.driver,self.url,u"乐学")
#调用打开页面组件
login_page.open()
#调用用户名输入组件
login_page.input_username(data["username"])
#调用输入密码组件
login_page.input_password(data["password"])
#调用点击登录按钮组件
login_page.click_submit()
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()
- 从excel中读取数据,首先,我们要先知道从excel中读取数据的方法
import xlrd
class ReadExcel:
def __init__(self, excel_path, sheet_name):
#打开excel表格
self.data = xlrd.open_workbook(excel_path)
#通过列表名字获取
self.table = self.data.sheet_by_name(sheet_name)
#获取第一行key值
self.keys = self.table.row_values(0)
#获取总行数
self.rownum = self.table.nrows
#获取总列数
self.colnum = self.table.ncols
def dict_data(self):
#判断总行数不小于1
if self.rownum <= 1:
print("总行数小于1")
else:
#定义一个空列表来存放表格中的数据
r = []
#初始化j,从第二行开始取数据
j = 1
#利用循环读取表格中的数据
for i in range(self.rownum - 1):
s = {
}
#从第二行取对应的values值
values = self.table.row_values(j)
for x in range(self.colnum):
s[self.keys[x]] = values[x]
r.append(s)
j += 1
return r
if __name__ == '__main__':
filepath = "test.xls"
sheetname = "Sheet1"
data = ReadExcel(filepath, sheetname)
print(data.dict_data())
将读取excel数据与测试用例结合
# Author:Xueyun
# -*- coding:utf-8 -*-
import unittest
import ddt
from exceldata import read_excel
from po.login_page import LoginPage
from selenium import webdriver
'''测试数据'''
filepath = "E:\\Pycharm_projects\\1\\exceldata\\test.xls"
sheetname = "Sheet1"
exce_data = read_excel.ReadExcel(filepath, sheetname)
test_data = exce_data.dict_data()
@ddt.ddt
class Case01(unittest.TestCase):
''''登录乐学'''
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.url = "http://www.5itest.cn/login"
# self.username = "183****9237"
# self.password = "123456"
#用例执行体
@ddt.data(*test_data)
def test_login_lexue(self, data):
#声明登录页面类对象
login_page = LoginPage(self.driver,self.url,u"乐学")
#调用打开页面组件
login_page.open()
#调用用户名输入组件
login_page.input_username(data["username"])
#调用输入密码组件
login_page.input_password(data["password"])
#调用点击登录按钮组件
login_page.click_submit()
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main()
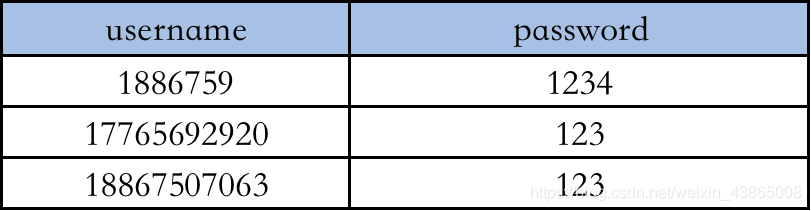
excel数据:

关键字驱动
关键字简单来说就是,把我们的执行操作每一个关键步骤当成一个关键字来对待,用来驱动程序的设计开发。例如:进行web自动化我们的首要是打开浏览器,是的 “打开浏览器” 我们就可以作为一个关键字来对待它,关键字就是来驱动我们程序设计的关键步骤。通过关键字的改变从而驱动自动化测试的执行,最终引起测试结果的改变。
对于测试一个注册页面,我们来梳理下看有哪些关键词,更深层次了解下关键词模型:
(1) 打开浏览器 —> 打开浏览器
(2) 输入注册页面的url —> 输入测试地址
(3) 页面加载等待 —> 页面加载等待
(4) 输入(注册邮箱、用户名、密码、验证码)—> 输入元素
(5) 点击注册按钮 —> 点击元素
(6) 退出浏览器
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
class RegisterKeyword(object):
def __init__(self, driver):
self.fe = FindElement(driver)
# 打开浏览器
def open_browser(self, browser):
if browser == 'chrome':
self.driver = webdriver.Chrome('../tools/chromedriver.exe')
elif browser == 'firefox':
self.driver = webdriver.Firefox()
else:
self.driver = webdriver.Edge()
# 输入测试地址
def get_url(self, url):
self.driver.get(url)
# 定位元素
def get_element(self, key):
return self.fe.get_element(key)
# 输入元素
def send_element_key(self, key, value):
get_element = self.get_element(key)
get_element.send_keys(value)
# 点击元素
def click_element(self, key):
self.fe.get_element(key).click()
# 页面等待
@staticmethod
def wait_loading():
sleep(3)
# 关闭浏览器
def close_browser(self):
self.driver.close()
if __name__ == "__main__":
register_url = 'http://www.5itest.cn/register'
driver = webdriver.Chrome('../tools/chromedriver.exe')
driver.get(register_url)
rk = RegisterKeyword(driver)
print(rk.get_element('register_email'))
driver.close()
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100702.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
