问题
讯飞文字转写长语音只有5h免费,想要体验50000分钟白嫖的,看我另一篇文章
最近在看一些教程,发现没有字幕,网络上也没有匹配的,看着很别扭
因此我使用au处理了视频,得到了视频声音,wav格式,20多分钟长度
然后使用讯飞的语音识别接口识别了下,得到了每句话识别的文字和视频对应的时间
然后按照srt格式对其进行了输出
这样就能给那些没有字幕的视频自动添加字幕了
我的需求大致满足了,记录一下。
解决
截图
视频字幕效果


字幕是语音识别自动添加的
代码框输出格式
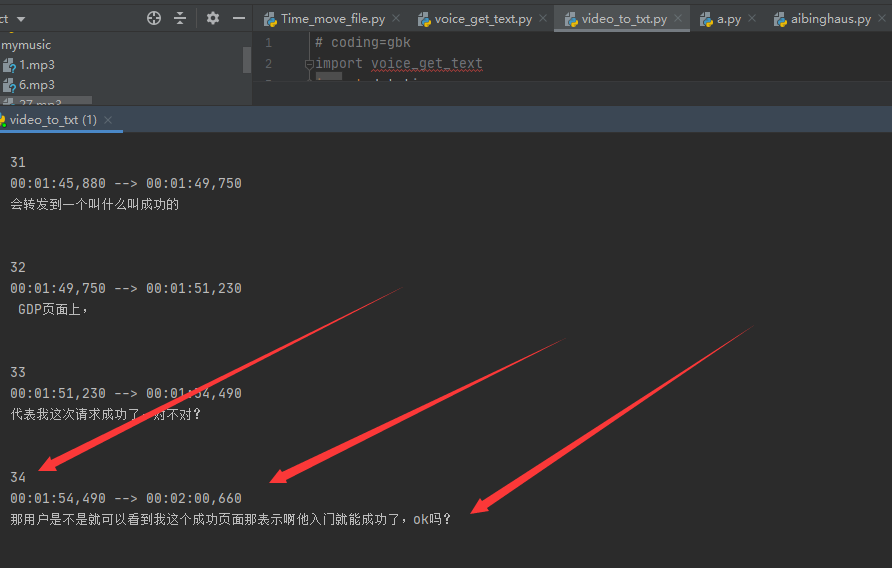
最后会生成srt字幕文件
srt格式原理

如图,第一个是序号,第二个是字幕显示时间段,精确到微秒,底下就是文字,中英文随意
字幕序号一般是顺序增加的,但是对视频没用,主要还是为了方便翻译人员翻译和观看,但是不可或缺,这是必要的格式
更加详细的看这个链接,这是我查的资料https://www.cnblogs.com/tocy/p/subtitle-format-srt.html
识别语音的讯飞接口调用函数
这个直接复制粘贴就行,只是一个调用的函数,非常通用,下面的另外一个函数是调用他的,位于同一个文件夹下的两个py文件
voice_get_text.py
# -*- coding: utf-8 -*-
#
#
# 非实时转写调用demo
import base64
import hashlib
import hmac
import json
import os
import time
import requests
lfasr_host = 'http://raasr.xfyun.cn/api'
# 请求的接口名
api_prepare = '/prepare'
api_upload = '/upload'
api_merge = '/merge'
api_get_progress = '/getProgress'
api_get_result = '/getResult'
# 文件分片大小10M
file_piece_sice = 10485760
# ——————————————————转写可配置参数————————————————
# 参数可在官网界面(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看,根据需求可自行在gene_params方法里添加修改
# 转写类型
lfasr_type = 0
# 是否开启分词
has_participle = 'false'
has_seperate = 'true'
# 多候选词个数
max_alternatives = 0
# 子用户标识
suid = ''
class SliceIdGenerator:
"""slice id生成器"""
def __init__(self):
self.__ch = 'aaaaaaaaa`'
def getNextSliceId(self):
ch = self.__ch
j = len(ch) - 1
while j >= 0:
cj = ch[j]
if cj != 'z':
ch = ch[:j] + chr(ord(cj) + 1) + ch[j + 1:]
break
else:
ch = ch[:j] + 'a' + ch[j + 1:]
j = j - 1
self.__ch = ch
return self.__ch
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self.appid = appid
self.secret_key = secret_key
self.upload_file_path = upload_file_path
# 根据不同的apiname生成不同的参数,本示例中未使用全部参数您可在官网(https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html)查看后选择适合业务场景的进行更换
def gene_params(self, apiname, taskid=None, slice_id=None):
appid = self.appid
secret_key = self.secret_key
upload_file_path = self.upload_file_path
ts = str(int(time.time()))
m2 = hashlib.md5()
m2.update((appid + ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
# 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {
}
if apiname == api_prepare:
# slice_num是指分片数量,如果您使用的音频都是较短音频也可以不分片,直接将slice_num指定为1即可
slice_num = int(file_len / file_piece_sice) + (0 if (file_len % file_piece_sice == 0) else 1)
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['file_len'] = str(file_len)
param_dict['file_name'] = file_name
param_dict['slice_num'] = str(slice_num)
elif apiname == api_upload:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['slice_id'] = slice_id
elif apiname == api_merge:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
param_dict['file_name'] = file_name
elif apiname == api_get_progress or apiname == api_get_result:
param_dict['app_id'] = appid
param_dict['signa'] = signa
param_dict['ts'] = ts
param_dict['task_id'] = taskid
return param_dict
# 请求和结果解析,结果中各个字段的含义可参考:https://doc.xfyun.cn/rest_api/%E8%AF%AD%E9%9F%B3%E8%BD%AC%E5%86%99.html
def gene_request(self, apiname, data, files=None, headers=None):
response = requests.post(lfasr_host + apiname, data=data, files=files, headers=headers)
result = json.loads(response.text)
if result["ok"] == 0:
print("{} success:".format(apiname) + str(result))
return result
else:
print("{} error:".format(apiname) + str(result))
exit(0)
return result
# 预处理
def prepare_request(self):
return self.gene_request(apiname=api_prepare,
data=self.gene_params(api_prepare))
# 上传
def upload_request(self, taskid, upload_file_path):
file_object = open(upload_file_path, 'rb')
try:
index = 1
sig = SliceIdGenerator()
while True:
content = file_object.read(file_piece_sice)
if not content or len(content) == 0:
break
files = {
"filename": self.gene_params(api_upload).get("slice_id"),
"content": content
}
response = self.gene_request(api_upload,
data=self.gene_params(api_upload, taskid=taskid,
slice_id=sig.getNextSliceId()),
files=files)
if response.get('ok') != 0:
# 上传分片失败
print('upload slice fail, response: ' + str(response))
return False
print('upload slice ' + str(index) + ' success')
index += 1
finally:
'file index:' + str(file_object.tell())
file_object.close()
return True
# 合并
def merge_request(self, taskid):
return self.gene_request(api_merge, data=self.gene_params(api_merge, taskid=taskid))
# 获取进度
def get_progress_request(self, taskid):
return self.gene_request(api_get_progress, data=self.gene_params(api_get_progress, taskid=taskid))
# 获取结果
def get_result_request(self, taskid):
return self.gene_request(api_get_result, data=self.gene_params(api_get_result, taskid=taskid))
def all_api_request(self):
# 1. 预处理
pre_result = self.prepare_request()
taskid = pre_result["data"]
# 2 . 分片上传
self.upload_request(taskid=taskid, upload_file_path=self.upload_file_path)
# 3 . 文件合并
self.merge_request(taskid=taskid)
# 4 . 获取任务进度
while True:
# 每隔20秒获取一次任务进度
progress = self.get_progress_request(taskid)
progress_dic = progress
if progress_dic['err_no'] != 0 and progress_dic['err_no'] != 26605:
print('task error: ' + progress_dic['failed'])
return
else:
data = progress_dic['data']
task_status = json.loads(data)
if task_status['status'] == 9:
print('task ' + taskid + ' finished')
break
print('The task ' + taskid + ' is in processing, task status: ' + str(data))
# 每次获取进度间隔20S
time.sleep(20)
# 5 . 获取结果
aaa=self.get_result_request(taskid=taskid)
return aaa
print(aaa)
处理结果,得到字符
放入自己在讯飞申请的语音转文字功能的id与key,执行后会得到一个巨长的声音识别后的dict字符串,自己处理一下变成srt格式就行了。当然这里我写的输出就是srt
video_to_txt.py
# coding=gbk
import voice_get_text
import datetime
video_path=input("音频路径:").replace("\\",'/')
print("开始处理...请等待")
api = voice_get_text.RequestApi(appid="申请的id", secret_key="申请的key",
upload_file_path=video_path)
myresult=api.all_api_request()
def get_format_time(time_long):
def format_number(num):
if len(str(num))>1:
return str(num)
else:
return "0"+str(num)
myhour=0
mysecond=int(time_long/1000)
myminute=0
mymilsec=0
if mysecond<1:
return "00:00:00,%s"%(time_long)
else:
if mysecond>60:
myminute=int(mysecond/60)
if myminute>60:
myhour=int(myminute/60)
myminute=myminute-myhour*60
mysecond=mysecond-myhour*3600-myminute*60
mymilsec=time_long-1000*(mysecond+myhour*3600+myminute*60)
return "%s:%s:%s,%s"%(format_number(myhour),format_number(myminute),format_number(mysecond),\
format_number(mymilsec))
else:
mysecond=int(mysecond-myminute*60)
mymilsec=time_long-1000*(mysecond+myminute*60)
return "00:%s:%s,%s"%(format_number(myminute),format_number(mysecond),format_number(mymilsec))
else:
mymilsec=time_long-mysecond*1000
return "00:00:%s,%s"%(mysecond,mymilsec)
myresult_str=myresult["data"]
myresult_sp=myresult_str.split("},{")
myresult_sp=myresult_sp[1:-1]
myword=""
flag_num=0
for i in myresult_sp:
flag_num+=1
print(i)
word=[]
key=[]
a=i.split(",")
for j in a:
temp=j.split(":")
key.append(temp[0][1:-1])
word.append(temp[1][1:-1])
get_dic=dict(zip(key,word))
print(get_dic)
bg= get_format_time(int(get_dic["bg"]))
ed= get_format_time(int(get_dic["ed"]))
real_word=get_dic["onebest"]
newword=str(flag_num)+"\n"+bg+" --> "+ed+'\n'+real_word+"\n\n\n"
myword=myword+newword
print(myword)
# myword=video_path.split("/")[-1]+"\n"+myword
nowTime_str = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H-%M-%S')
path_file=r"C:\Users\Administrator.DESKTOP-KMH7HN6\Desktop\video_text\%s.srt"%(nowTime_str)
f = open(path_file,'a')
f.write(myword)
f.write('\n')
f.close()
print('已经识别完成,见输出目录下的srt文件')
input()
列表合成字典
这个无视即可,随手写的代码
# -*- coding: utf-8 -*-
keys = ['a', 'b', 'c']
values = [1, 2, 3]
mydic = dict(zip(keys, values))
print (mydic)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100245.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
