开窗函数格式:函数名(列) over (选项)
SQL标准允许将所有聚合函数用作开窗函数,使用over关键字来区分这两种用法。
PARTITION BY 子句
与group by子句不同,partition by子句创建的分区是独立于结果集的,partition by创建的分区只是供进行聚合运算的。
--显示每一个人员的信息以及所属城市的人员数
select fname,fcity,fage,fsalary,
count(*) over(partition by fcity) 所在城市人数 from t_person
在同一个SELECT语句中可以同时使用多个开窗函数,而且这些开窗函数并不会相互干扰。比如下面的SQL语句用于显示每一个人员的信息、所属城市的人员数以及同龄人的人数:
--显示每一个人员的信息、所属城市的人员数以及同龄人的人数:
select fname,
fcity,
fage,
fsalary,
count(*) over(partition by fcity) 所属城市的人个数,
count(*) over(partition by fage) 同龄人个数
from t_person
ORDER BY子句
使用ORDER BY子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。ORDER BY子句的语法为:
ORDER BY 字段名 RANGE|ROWS BETWEEN 边界规则1 AND 边界规则2
RANGE表示按照值的范围进行范围的定义,
ROWS表示按照行的范围进行范围的定义;
边界规则的可取值见下表:

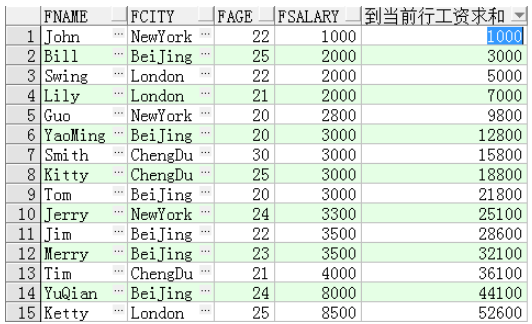
例子一:查询从第一行到当前行的工资总和
select fname,
fcity,
fage,
fsalary,
sum(salary) over(order by fsalary rows between unbounded preceding and current row) 到当前工资求和
from t_person
可以简化为:
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary) 到当前行工资求和
from t_person

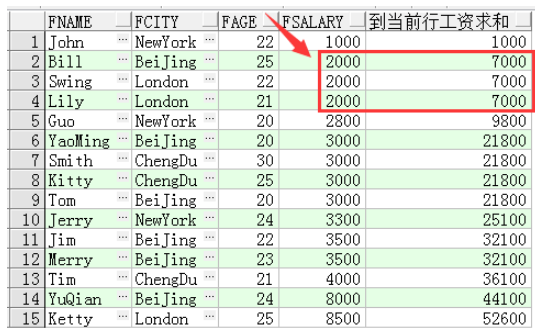
例子二:把例子程序一的row换成了range,是按照范围进行定位的
select fname,
fcity,
fage,
fsalary,
sum(fsalary) over(order by fsalary range between unbounded preceding and current row) 到当前行工资求和
from t_person
高级开窗函数/ 排名的实现ROW_NUMBER();rank() ,dense_rank()
SELECT FName, FSalary,FAge,
RANK() OVER(ORDER BY fsalary desc) f_RANK,
DENSE_RANK() OVER(ORDER BY fsalary desc) f_DENSE_RANK,
ROW_NUMBER() OVER(ORDER BY fsalary desc) f_ROW_NUMBER
FROM T_Person;
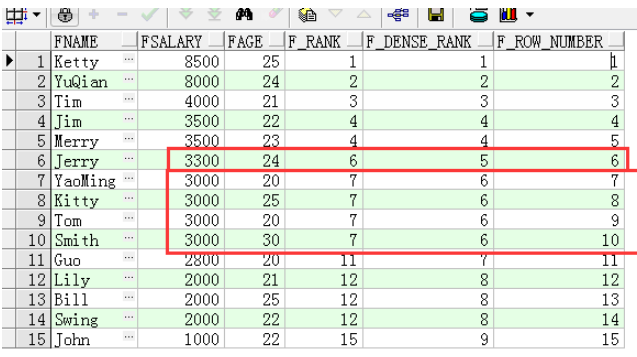
dence_rank在并列关系是,相关等级不会跳过。rank则跳过
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
【语法】
RANK ( ) OVER ( [query_partition_clause] order_by_clause )
dense_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
ROW_NUMBER()
【语法】ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)
【功能】表示根据COL1分组,在分组内部根据 COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)
row_number() 返回的主要是“行”的信息,并没有排名
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100177.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
