一、牛客SQL题
简单
1. 查找最晚入职员工的所有信息
#入职最晚的不止一个人
select *
from employees
where hire_date = (
select max(hire_date)
from employees
)
2. 入职员工时间排名倒数第三的员工所有信息
select *
from employees
where hire_date = (
select distinct hire_date
from employees
order by hire_date desc
limit 1 offset 2 #
#从第二个开始,选一个,也就是第三个
);
3. 各个部门领导薪水详情以及其对应部门编号dept_no
select s.*,d.dept_no
from salaries s
join dept_manager d
on s.emp_no = d.emp_no
and s.to_date = '9999-01-01'
and d.to_date = '9999-01-01'
4. 查找所有已经分配部门的员工
select e.last_name,e.first_name,d.dept_no
from employees e
join dept_emp d
on e.emp_no=d.emp_no
#未分配部门的员工不显示
where d.dept_no is not null;
5. 查找薪水记录超过15次的员工
select s.emp_no,count(s.salary) c
from salaries s
group by s.emp_no
having c>15
6. 所有非部门领导的员工emp_no
select emp_no
from employees
where emp_no not in (
select emp_no
from dept_manager
)
7. 获取所有的员工和员工对应的经理
如果员工本身是经理的话则不显示
select e.emp_no,d.emp_no manager
from dept_emp e,dept_manager d
where e.dept_no = d.dept_no
and e.emp_no <> d.emp_no
8. emp_no为奇数,且last_name不为Mary
select *
from employees e
where e.emp_no%2 = 1 (或者e.emp_no&1=1 )
and e.last_name!='Mary'
order by e.hire_date desc
9. 各个title类型的平均工资avg
select t.title,avg(s.salary) as average
from titles as t
join salaries as s
on t.emp_no = s.emp_no
group by t.title
order by average
10. 三表连接
select e.last_name,e.first_name,d.dept_name
from employees e
left join dept_emp de on e.emp_no=de.emp_no
left join departments d on de.dept_no=d.dept_no
11.更新操作:薪水增加10%
update salaries as s join emp_bonus as e on s.emp_no=e.emp_no
set salary=salary*1.1
where to_date='9999-01-01'
中等
1. 获取薪水第二多的员工(多个,不用order by)
-- 方法一
select s.emp_no, s.salary, e.last_name, e.first_name
from salaries s join employees e
on s.emp_no = e.emp_no
where s.salary = -- 第三步: 将第二高工资作为查询条件
(
select max(salary) -- 第二步: 查出除了原表最高工资以外的最高工资(第二高工资)
from salaries
where salary <
(
select max(salary) -- 第一步: 查出原表最高工资
from salaries
where to_date = '9999-01-01'
)
and to_date = '9999-01-01'
)
and s.to_date = '9999-01-01'
2. 入职以来的薪水涨幅情况
select b.emp_no,(b.salary-a.salary) as growth
from
(select e.emp_no,s.salary
from employees e
left join salaries s
on e.emp_no=s.emp_no
and e.hire_date=s.from_date)a -- 入职工资表
inner join
(select e.emp_no,s.salary
from employees e
left join salaries s
on e.emp_no=s.emp_no
where s.to_date='9999-01-01')b -- 现在工资表
on a.emp_no=b.emp_no
order by growth
3.非manager员工薪水情况
思路:先找到所有非manager员工emp_no,再内连接工资表和部门表即可
select de.dept_no,a.emp_no,s.salary
from
(select emp_no
from employees
where emp_no not in (select emp_no
from dept_manager)
) a
inner join dept_emp de on a.emp_no=de.emp_no
inner join salaries s on a.emp_no=s.emp_no
where s.to_date='9999-01-01'
开窗
1. 所有部门中员工薪水最高的相关信息
select t.dept_no,t.emp_no,t.salary from
(
select
de.dept_no,de.emp_no,s.salary,
row_number() over(partition by de.dept_no order by s.salary desc) as rk
from (
select * from dept_emp where to_date='9999-01-01') de
inner join
(select * from salaries where to_date='9999-01-01') s on de.emp_no=s.emp_no
)t
where t.rk=1;
2.薪水排名
select emp_no,salary,
dense_rank() over (order by salary desc) as rank
from salaries
where to_date='9999-01-01'
order by emp_no asc,rank asc
3. salary累计和
--前N个当前( to_date = '9999-01-01')员工的salary累计和
select emp_no,
salary,
sum(salary) over(order by emp_no) as running_total
from salaries
where to_date="9999-01-01"
不常用操作
1. last_name和first_name连接
select concat_ws(' ', last_name, first_name) as Name
from employees
2. 建表
CREATE TABLE actor(
actor_id smallint(5) primary key,
first_name varchar(45) not null,
last_name varchar(45) not null,
last_update date not null);
常规创建
create table if not exists 目标表
复制表格
create 目标表 like 来源表
将table1的部分拿来创建table2
create table if not exists actor_name
(
first_name varchar(45) not null,
last_name varchar(45) not null
)
select first_name,last_name
from actor
3. 批量插入数据
INSERT INTO actor(actor_id,
first_name,
last_name,
last_update)
VALUES(1,'PENELOPE','GUINESS','2006-02-15 12:34:33'),
(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
4. 建索引
ALTER TABLE tbl_name ADD PRIMARY KEY (col_list);
// 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
ALTER TABLE tbl_name ADD UNIQUE index_name (col_list);
// 这条语句创建索引的值必须是唯一的。
ALTER TABLE tbl_name ADD INDEX index_name (col_list);
// 添加普通索引,索引值可出现多次。
ALTER TABLE tbl_name ADD FULLTEXT index_name (col_list);
// 该语句指定了索引为 FULLTEXT ,用于全文索引。
--删除索引
DROP INDEX index_name ON tbl_name;
// 或者
ALTER TABLE tbl_name DROP INDEX index_name;
ALTER TABLE tbl_name DROP PRIMARY KEY;
5. 建视图
CREATE VIEW actor_name_view
AS
SELECT first_name AS first_name_v, last_name AS last_name_v
FROM actor;
6.表增加一列
--alter table添加表列的语法:
ALTER TABLE table_name
ADD column_name datatype;
--举例
alter table actor
add create_date datetime not null default "2020-10-01 00:00:00";
7. 更新操作
update titles_test
set to_date = NUll,
from_date="2001-01-01"
where to_date="9999-01-01"
--将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现,直接使用update会报错。
update titles_test
set emp_no=replace(emp_no,10001,10005)
where id=5
8.创建外键
--在audit表上创建外键约束,其emp_no对应employees_test表的主键id
alter table audit
add constraint fk_audit_empployee
foreign key(Emp_no) references employees_test(ID)
9.查找逗号出现的次数
思路:
把串 "10,A,B" 中的 逗号用空串替代, 变成了 "10AB"
然后原来串的长度 - 替换之后的串的长度 就是 被替换的 逗号的个数
select (length("10,A,B") - length(replace("10,A,B",",","")) )
10. 字符串截取
RIGHT(s,n),返回字符串 s 的后 n 个字符。
select first_name
from employees
order by right(first_name,2)
SUBSTR(s, start, length),从字符串 s 的 start 位置截取长度为 length 的子字符串。
select first_name
from employees
order by substr(first_name,-2,2)
11 group_concat()
--group_concat()函数将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
select dept_no, group_concat(emp_no) as employees
from dept_emp
group by dept_no
分页查询
--分页查询employees表,每5行一页,返回第2页的数据
select *
from employees
limit 5 offset 5
case when
select e.emp_no,
e.first_name,
e.last_name,
eb.btype,
s.salary,
(
case when eb.btype=1 then s.salary*0.1
when eb.btype=2 then s.salary*0.2
else s.salary*0.3
end
) as bonus from employees e join emp_bonus eb on e.emp_no=eb.emp_no
join salaries s on eb.emp_no=s.emp_no
where s.to_date="9999-01-01"
牛客每个人最近的登录日期(二)
统计一下牛客每个用户最近登录是哪一天,用的是什么设备
两个join,连接三个表
#1.先根据用户分组,查出每个用户登录的最新日期(一)
select user_id,max(date)
from login
group by login.user_id;
#2. 然后查出所有用户的名字,所有的登录设备,所有的登录日期(二)
select user.name as u_n,client.name as c_n,login.date
from login
join user on login.user_id=user.id
join client on login.client_id=client.id;
#3.那么再根据用户id和最新的登录日期(一),
#可以在所有的数据(二)里面,从而确定唯一一组数据,最后再按照名字排序(三):
select user.name as u_n, client.name as c_n,login.date
from login
join user on login.user_id=user.id
join client on login.client_id=client.id
where (login.user_id,login.date) in
(select user_id,max(date) from login group by login.user_id )
order by user.name;
牛客每个人最近的登录日期(三)(留存率)
求次日成功留存率
次日成功留存率=(第一天登录的新用户并且第二天也登录的用户)/(总用户)
DATE_ADD函数
round
#1. 总用户
select count(distinct user_id) from login
#2. 找到每个用户第一天登录的日期
select user_id,min(date)
from login
group by user_id
#3. 第二天还登录的新用户
select user_id, DATE_ADD(MIN(date),INTERVAL 1 DAY)
from login
group by user_id
#整合
select
round(count(distinct user_id)*1.0/(select count(distinct user_id) from login),3)
#round( ,3)结果保留3位小数
from login
where (user_id,date)
in
(select user_id,date_add(min(date),interval 1 day)
from login
group by user_id);
最长连续登陆天数
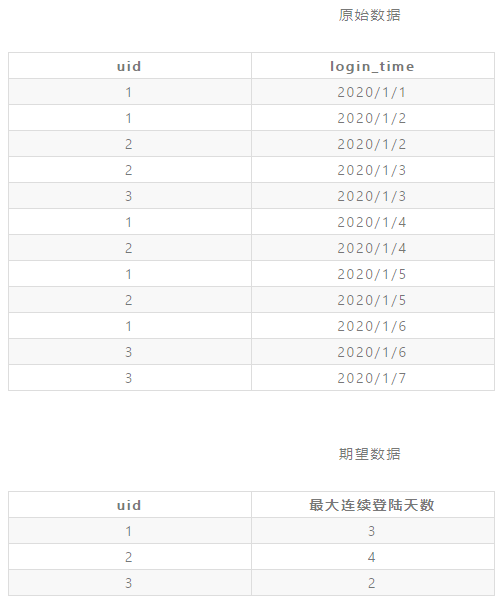
- 获取每个用户的数据信息,并按照时间进行排序
使用row_number()窗口函数,按uid分组,按照login_time排序
select uid,login_time,row_number() over(partition by uid order by login_time) as rank
from user_login
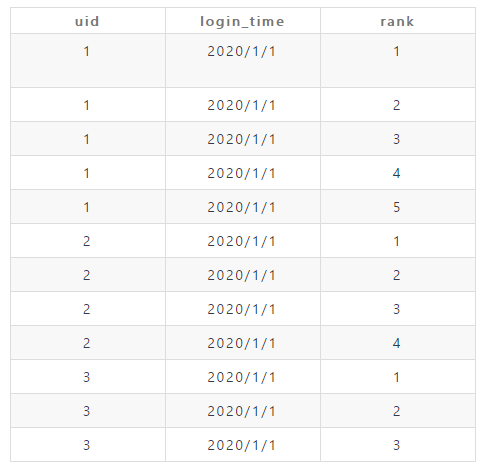

- 开始判断是否连续,通过将login_time和rank相减法,从而得出,是否连续。
连续登陆的天,对应的login_time-rank是相等的
例如:
login_time rank 相减
1.1 1 12.31
1.2 2 12.31
1.3 3 12.31
1.5 4 1.1
1.6 5 1.1
select uid,
date_sub(login_time,rank) as login_sub,
min(login_min) as login_min,
max(login_max) as login_max,
count(1) as login_con
from(
--根据用户分组,按照时间进行排序
select uid,login_time,
row_number() over(partition by uid order by login_time) as rank
from user_login
)a
group by uid,login_sub;
3.通过uid 分组,获得最大的login_con
select uid,max(login_con) as login_max from (
select
uid,
date_sub(login_time,rank) as login_sub,
min(login_time) as login_min,
max(login_time) as login_max,
count(1) as login_con
from (
-- 根据用户分组,按照时间进行排序(默认升序)
select
uid,
login_time,
row_number() OVER(PARTITION BY uid order by login_time) as rank
from user_login
) a
group by uid,date_sub(login_time,rank)
) b group by uid
开窗函数
--显示每一个人员的信息以及所属城市的人员数
select fname,fcity,fage,fsalary,
count(*) over(partition by fcity) 所在城市人数 from t_person
SELECT FName, FSalary,FAge,
RANK() OVER(ORDER BY fsalary desc) f_RANK,
DENSE_RANK() OVER(ORDER BY fsalary desc) f_DENSE_RANK,
ROW_NUMBER() OVER(ORDER BY fsalary desc) f_ROW_NUMBER
FROM T_Person;
考试分数大于平均数的数据
select a.* from
grade as a
left join
(select job, round(avg(score), 3) as score1 from grade group by job) AS b
on a.job = b.job
where a.score > b.score1
order by a.id;
每个岗位分数前2名的用户
select t1.id, t2.name, t1.score
from
(select id, language_id, score, dense_rank() over (partition by language_id order by score desc) as ranks from
grade) t1,
language t2
where
t1.ranks in (1,2)
and t1.language_id = t2.id
order by t2.name,t1.score desc, t1.id
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100174.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
