1. 主从复制
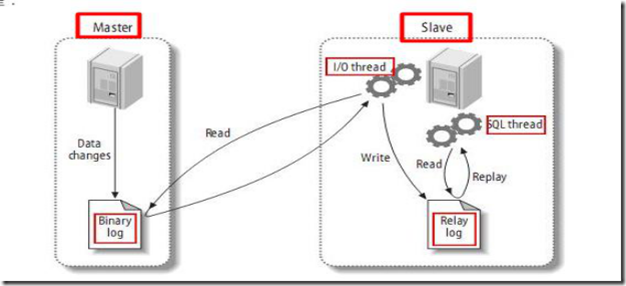

箭头顺序依次从左到右
注:slave端也有 binlog
延迟分析
读写:
Data changes: 顺序的写操作,比较快,不太会发生延迟。一个大文件和多个小文件相比,大文件读取更快(顺序读写),因为小文件需要频繁多次寻址(随机读写)。kafka消息队列,数据放在磁盘上,只支持append操作(append的大多数是顺序读写),包括大数据分布式的也是,不支持Insert和update
I/O Thread读操作:顺序读取,几乎不延迟。(异地,不在同一个局域网,用专用光纤传输,此处不要省钱)
I/O Thread 顺序写入 Relay log,无延迟
SQL Thread读取Relay log: 顺序读
SQL Thread 写的时候(找到对应的sql语句进行修改)是随机的,可能会延迟
- 例如:update table set name=zhiang where id=1
- update table set name lsi where id=200
注:append是顺序的,update和insert是随机的
-
整体流程分析:
- 前面都是顺序的,不延迟
- 只在SQL Thread写时延迟,因为是随机读写的
- 可能会造成relay log堆积
怎么解决延迟问题
MTS:multi-thread salve
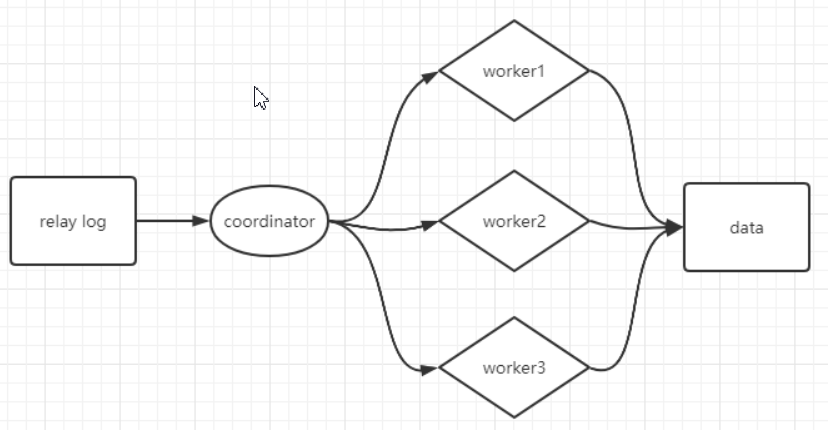
SQL Thread并行复制,多线程
并行复制的粒度:库、表、行
查看粒度: show variables like’%parallel%’
会显示slave_parallel_type = DATABASE(这是库级别的)|| ROW(行)
2. 主从复制延迟产生的原因
- 备库机器性能比主库差
- 主库主要是写,备库主要读,若查询压力大,备库的查询消耗大量CPU资源,影响同步速度
- 大事务执行,如果主库的一个事务执行了10分钟,而binlog的写入必须要等待事务完成之后,才会传入备库,那么在开始执行时就延迟了
- 主库的写操作是顺序写binlog,从库单线程去主库顺序读binlog,从库取到binlog之后再本地执行。mysql的主从复制都是单线程操作,但由于主库是顺序写的,所以效率很高,而从库也是顺序读取主库的日志,此时的效率也比较高,但当数据拉取回来之后变成了随机操作,而不是顺序的,所以成本会提高。
- 从库在同步数据的同时,可能跟其他查询的线程发生锁抢占情况,也会发生延迟
- 当主库的TPS(服务器每秒处理的事务数)并发非常高时,产生的DDL数量超过了一个线程所能承受的范围,那么也可能会带来延迟
- 在进行binlog日志传输的时候,如果网络带宽不是很好,网络延迟也会造成数据同步延迟
3. 如何解决复制延迟问题
Mysql版本5.6之后引入并行复制的概念
问题:
- 在并行操作(多个worker并行)的时候,可能会有并发的事务问题,我们的备库在执行的时候可以按照轮训的方式发送给各个worker吗? 不可以
- 同一个事务的不同sql语句,可以分发给不同的worker执行? 不可以
规则:
更新同一行的多个事务,必须要分发到同一个worker中执行
同一个事务不能被拆开,必须要放到同一个worker中执行
库——》worker上必须要加标识——》db
表——》worker上必须要加标识——》库名:表名
行——》worker上必须要加标识——》库名:表名+唯一值(不一定是主键)
GTID:全局事务ID
由两部分组成:服务器的唯一标识 + 递增的事务id
GTID工作原理简单介绍
- master更新数据的时候,会在事务前产生GTID,一同记录到binlog日志中。
- slave端的io线程将binlog写入到本地relay log中。
- 然后SQL线程从relay log中读取GTID,设置gtid_next的值为该gtid,然后对比slave端的binlog是否有记录
- 如果有记录的话,说明该GTID的事务已经运行,slave会忽略
- 如果没有记录的话,slave就会执行该GTID对应的事务,并记录到binlog中
4. 并行复制策略
--查看并行的slave的线程的个数,默认是0,表示单线程,worker与核心CPU数保持一致最佳8~16
show global variables like 'slave_parallel_workers';
--设置并发复制方式:库、表
show global variables like '%slave_parallel_types%';
如何写binlog日志——》二阶段提交
数据更新流程
1.执行器先从引擎中找到数据,如果在内存中直接返回,如果不在内存中,查询后返回
2.执行器拿到数据之后会先修改数据,然后调用引擎接口重新写入数据
3. 引擎将数据更新到内存,同时写数据到redo中,此时处于prepare阶段,并通知执行器执行完成,随时可以操作
4. 执行器生成这个操作的binlog
5. 执行器调用引擎的事务提交接口,引擎把刚刚写完的redo改成commit状态,更新完成
redo log的两阶段提交/两个日志必须同时写
- 先写
redo log后写binlog:
redo log写完之后,系统即使崩溃,仍然能够把数据恢复回来。但由于binlog没写完,这时候binlog里就没有记录这个语句。因此,之后备份日志的时候,存起来的binlog里就没有这条语句,这时,若用binlog恢复临时库会少一次更新,与原库不一致。- 先写
binlog后写redo log:
如果binlog写完之后crash,由于redo log还没写,崩溃恢复以后这个事务无效,但用binlog恢复时多了一个事务,与原库不一致。
mysql5.7版本,根据mariaDB的并行复制策略,做了相应的优化调整后,提供了自己的并行复制策略,并且可通过参数slave-parallel-type来控制并行复制的策略:
- 当配置的值为databse时,表示使用5.6版本的按库并行策略
- 当为logical_clock时,表示跟mariaDB相同的策略。
同时处于执行状态的所有事务,是否可以并行?
不可以。因为多个执行中的事务是由可能出现锁冲突的,锁冲突之后会产生锁等待问题。
mysql5.7的并行复制策略的思想:(基于组提交)
- 同时处于prepare状态的事务,在备库执行时可以并行的
- 处于prepare状态的事务,与处于commit状态的事务之间,在备库上执行也是可以并行的。
以下讨论的前提 是设置MySQL的crash safe相关参数为双1:
sync_binlog=1
innodb_flush_log_at_trx_commit=1
组提交
是mysql处理日志的一种优化方式,主要为了解决写日志时频繁刷磁盘的问题。组提交伴随着Mysql的发展,已经支持了redo log和bin log组提交。
组提交的作用:
- 在没有开启binlog时,Redo log的刷盘操作将会是最终影响MySQL TPS的瓶颈所在。为了缓解这一问题,MySQL使用了组提交,将多个刷盘操作合并成一个,如果说10个事务依次排队刷盘的时间成本是10,那么将这10个事务一次性一起刷盘的时间成本则近似于1。
- 当开启binlog时为了保证Redo log和binlog的数据一致性,MySQL使用了二阶段提交,由binlog作为事务的协调者。而 引入二阶段提交 使得binlog又成为了性能瓶颈,先前的Redo log 组提交 也成了摆设。为了再次缓解这一问题,MySQL增加了binlog的组提交,目的同样是将binlog的多个刷盘操作合并成一个,结合Redo log本身已经实现的 组提交,分为三个阶段(Flush 阶段、Sync 阶段、Commit 阶段)完成binlog 组提交,最大化每次刷盘的收益,弱化磁盘瓶颈,提高性能。
MySQL组提交基于这样的处理机制,可以将大部分的日志处于prepare状态,因此可以设置:
- binlog_group_commit_sync_delay参数,表示延迟多少微妙采用fsync
- binlog_group_commit_sync_no_delay_count参数,表示累积多少次后才调用fsync
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100173.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
