文章目录
python爬虫—–request模块学习及案例
基本知识
str和bytes的区别
python3中:
str 使用encode方法转化为 bytes
bytes通过decode转化为str
在Python 3中把两者给分开了这个在使用中需要注意。实际应用中在互联网上是通过二进制进行传输,所以就需要将str转换成bytes进行传输,而在接收中通过decode()解码成我们需要的编码进行处理数据这样不管对方是什么编码而本地是我们使用的编码这样就不会乱码。
str1 = '人生苦短'
b = str1.encode()
str1 = b.decode()
print(str1)
print(type(str1))
print('***************')
print(b)
print(type(b))
结果输出
人生苦短
<class 'str'>
***************
b'\xe4\xba\xba\xe7\x94\x9f\xe8\x8b\xa6\xe7\x9f\xad'
<class 'bytes'>
urllib库
常见方法
1.request.urlopen()
import urllib
urllib.request.urlopen(url,data,timeout)
- 第一个参数ur即为URL,第二个参数data是访问URL时要传送的数据, 第三个timeout是设置超时时间。
- 第二三个参数是可以不传送的,data默认为空None, timeout默认为socket._GLOBAL DEFAULT _TIMEOUT
- 第一个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,执行urlopen方法之后, 返回一个response对象,返回信息便保存在这里面。
2.read()
- read()方法就是读取文件内的全部内容,返回bytes类型
3.getcode()
- 返回HTTP的响应码,成功返回200,4服务器页面出错,5服务器问题
4.info()
- 返回服务器响应HTTP报头
import urllib.request
url1 = "http://www.baidu.com/"
f = urllib.request.urlopen(url1)
info = f.read()
#print(info.decode())
print(f.geturl())
print('***********************')
print(f.getcode())
print('***********************')
print(f.info())
输出结果
http://www.baidu.com/
***********************
200
***********************
Bdpagetype: 1
Bdqid: 0x853689130000c1c9
Cache-Control: private
Content-Type: text/html;charset=utf-8
Date: Tue, 16 Mar 2021 12:20:23 GMT
Expires: Tue, 16 Mar 2021 12:19:47 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Set-Cookie: BAIDUID=E5EA9206E149F08295546FF28C768CE2:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=E5EA9206E149F08295546FF28C768CE2; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1615897223; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=E5EA9206E149F0825C2486BEC5C001D3:FG=1; max-age=31536000; expires=Wed, 16-Mar-22 12:20:23 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=33257_33344_31253_33594_33570_33392_26350_22158; path=/; domain=.baidu.com
Traceid: 161589722302381870189599010370484224457
Vary: Accept-Encoding
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
Connection: close
Transfer-Encoding: chunked
Request对象
但是如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
User-Agent
我们用一个合法的身份去请求别人网站,显然人家就是欢迎的,所以我们就应该给我们的这个代码加上一个身份,就是所谓的User-Agent头。
如果我们希望我们的爬虫程序更像一个真实用户,那我们第一步,就是需要伪装成一个被公认的浏览器。用不同的浏览器在发送请求的时候,会有不同的User-Agent头。
from urllib.request import urlopen,Request
url1 = "http://www.baidu.com"
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"
}
req = Request(url1,headers=head)
print(req.get_header('User-agent'))
resp = urlopen(req)
info1 = resp.read()
print(info1.decode())
Get请求方法
GET请求一般用于我们向服务器获取数据.
在其中我们可以看到在请求部分里,http://www.baidu.com/s? 之后出现一个长长的字符串,其中就包含我们要查询的关键词传智播客,于是我们可以尝试用默认的Get方式来发送请求。
方法1:
from urllib.request import Request,urlopen
from urllib.parse import quote
url1 = 'https://www.baidu.com/s?wd={}'.format(quote('社区'))
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
request = Request(url1,headers=headers)
response = urlopen(request)
print(response.read().decode())
方法2:
from urllib.request import urlopen,Request
from urllib.parse import urlencode
agre = {
'wd':'社区',
'ie':'utf-8'
}
print(urlencode(agre))
url = "https://www.baidu.com/s?[]".format(urlencode(agre))
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
req = Request(url,headers=headers)
res = urlopen(req)
print(res.read().decode())
下载百度贴吧案例
from urllib.request import Request,urlopen
from urllib.parse import urlencode
def get_html(url):
head = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
req = Request(url,headers=head)
info = urlopen(req)
return info.read()
def save_html(filename,html_bytes):
with open(filename,'wb') as f:
f.write(html_bytes)
print(html_bytes)
def main():
content = input("请输入要下载的内容:")
size = int(input("请输入要下载的页数:"))
base_url = 'https://tieba.baidu.com/f?ie=utf-8&{}'
for pn in range(size):
args = {
'pn': pn * 50,
'kw': content
}
args = urlencode(args)
html_bytes = get_html(base_url.format(args))
print('正在下载第{}页'.format(pn))
filename = '第{}页.html'.format(pn)
save_html(filename,html_bytes)
if __name__ == '__main__':
main()
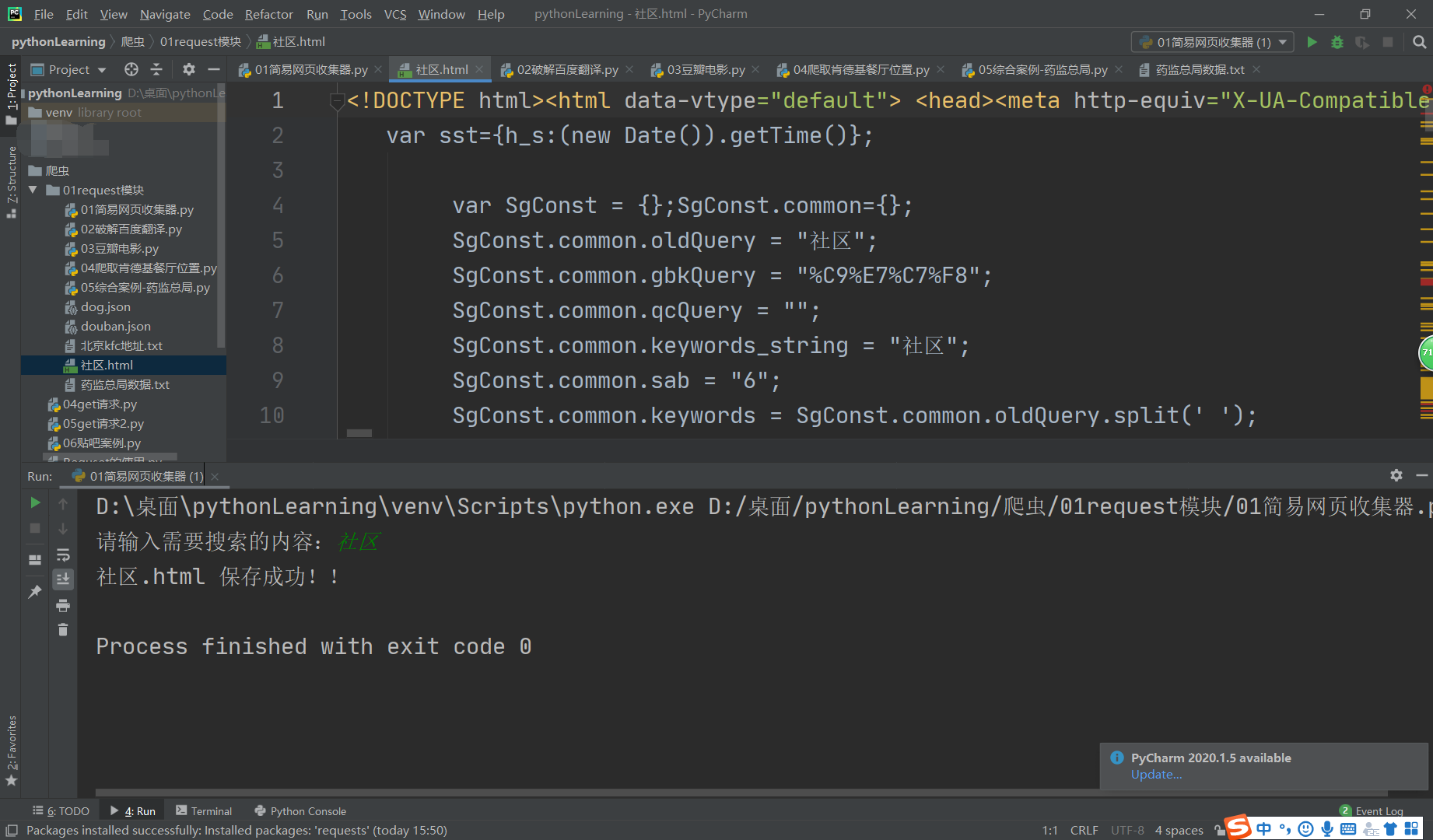
1.简单的网页收集器
import requests
if __name__ == '__main__':
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
url = 'https://www.sogou.com/sie'
kw = input("请输入需要搜索的内容:")
param = {
'query':kw
}
response = requests.get(url=url,params=param,headers=head)
page_text = response.text
filename = kw + '.html'
with open(filename,'w',encoding='utf-8',) as fp:
fp.write(page_text)
print(filename,'保存成功!!')
效果图

2.爬取百度翻译内容
import requests
import json
if __name__ == '__main__':
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.37'
}
query = input('请输入需要翻译的内容:')
data = {
'kw':query
}
response = requests.post(url=url,data=data,headers=headers)
dic_obj = response.json()
fileName = query+'.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print('保存成功!!')
效果图
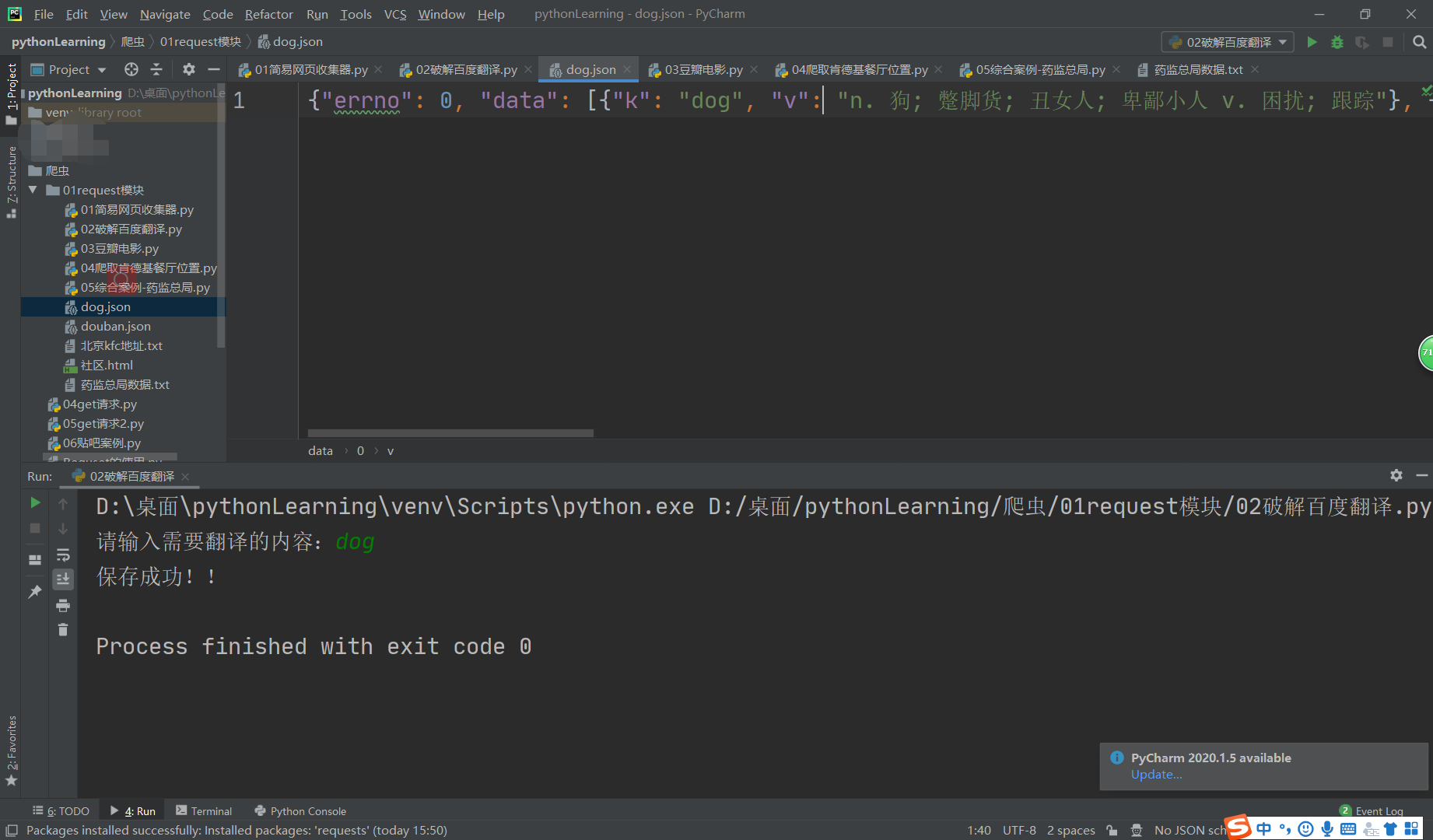
3.爬取豆瓣电影
import requests
import json
url = 'https://movie.douban.com/j/chart/top_list'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': '0',
'limit': '20'
}
response = requests.get(url=url,params=param,headers=headers)
list_data = response.json()
fileName = 'douban.json'
fp = open(fileName,'w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
效果图
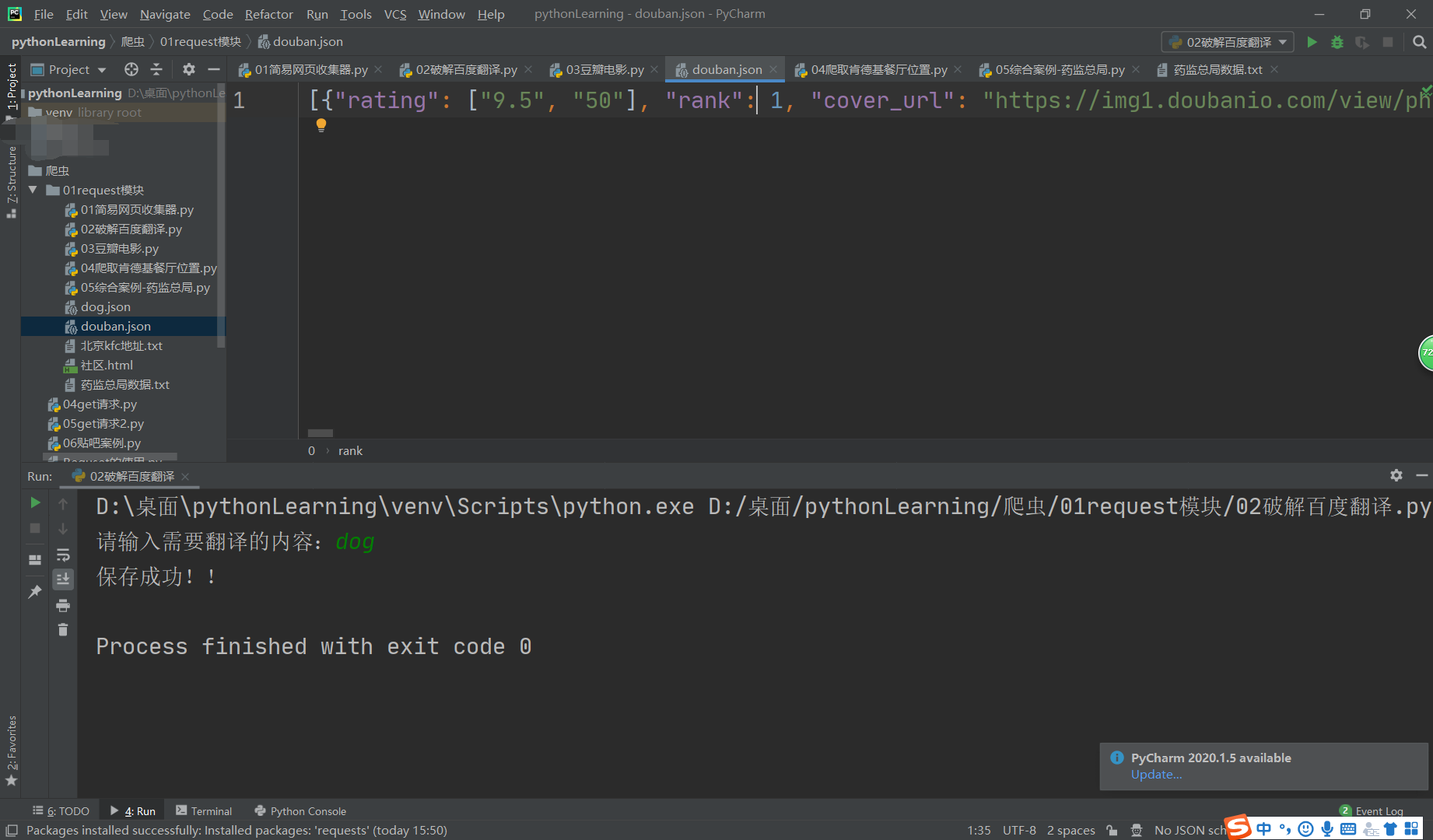
4.爬取kfc餐厅地址位置
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
kw = input('请输入想要查询的kfc地址:')
index = input('请输入想要查询的kfc地址第几页:')
data = {
'cname':'',
'pid':'' ,
'keyword': kw,
'pageIndex': index,
'pageSize': '10'
}
response = requests.post(url=url,data=data,headers=headers)
kfc_data = response.text
fileName = kw+'kfc地址.txt'
with open(fileName, 'w', encoding='utf-8', ) as fp:
fp.write(kfc_data)
print("over!!!")
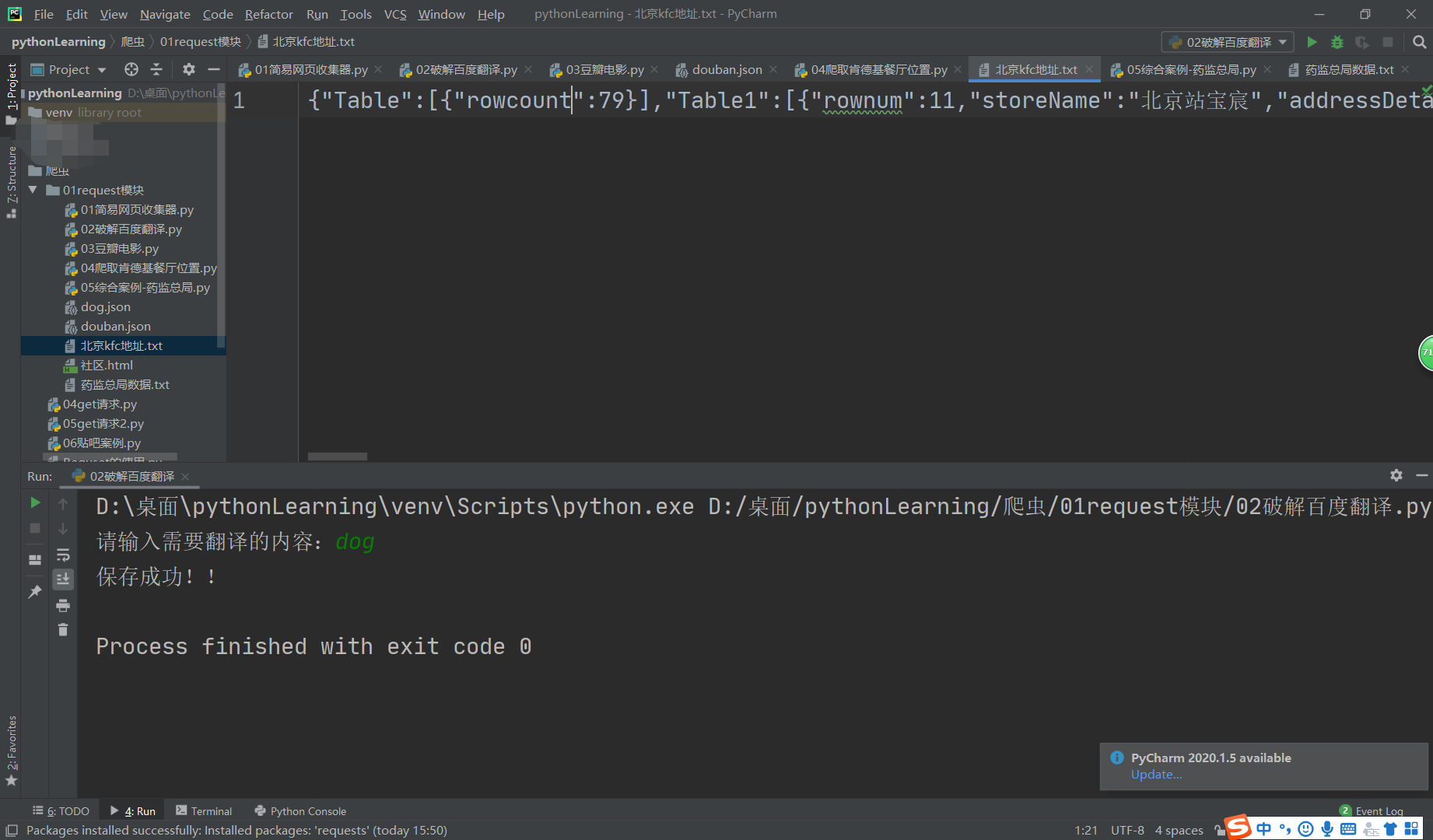
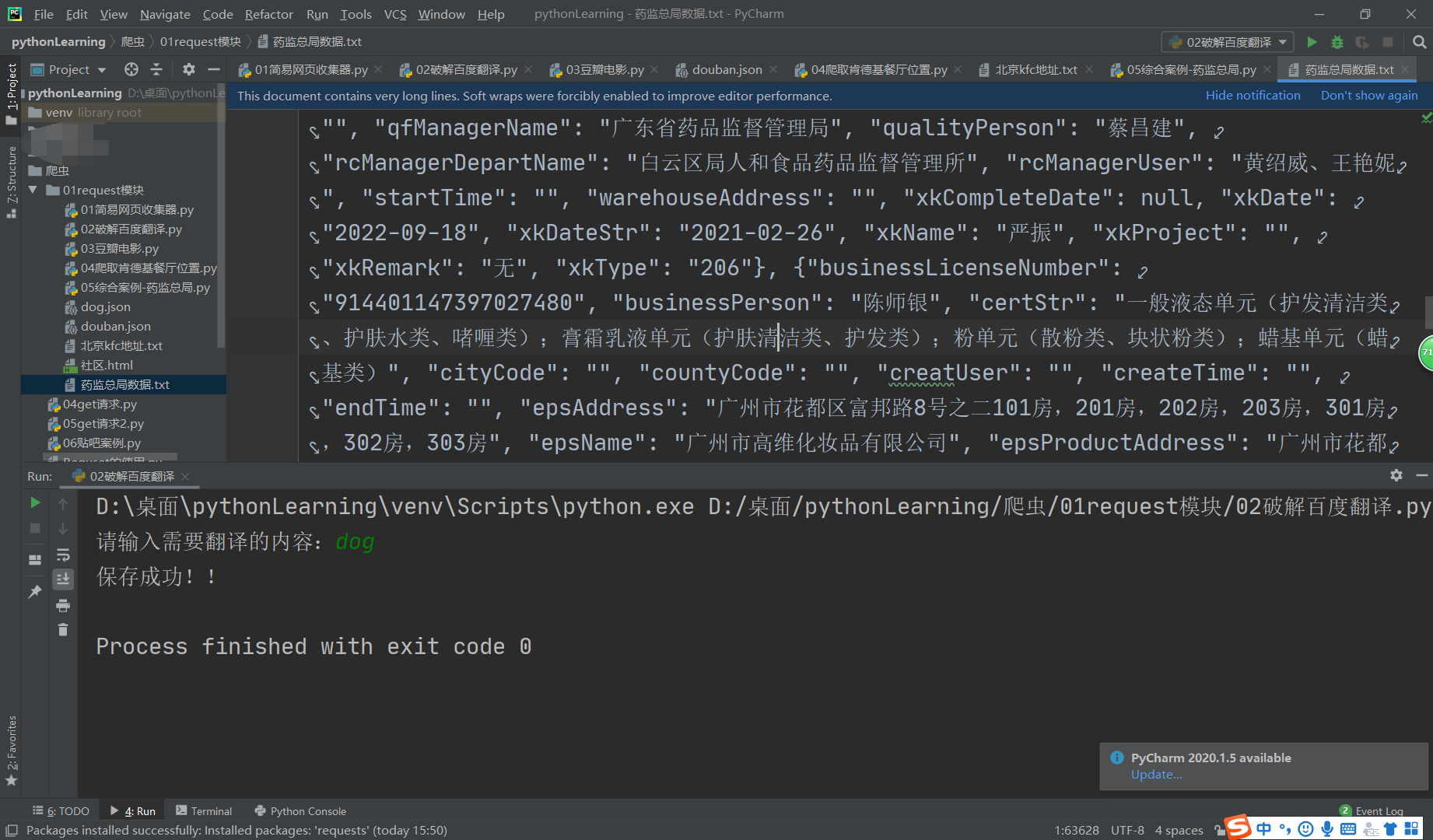
5.爬取药监总局
import requests
import json
if __name__ == '__main__':
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
all_data_list = []
id_list = [] # 储存企业id
for page in range(1,10):
data = {
'on': 'true',
'page': page,
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname': '',
}
json_id = requests.post(url=url,headers=headers,data=data).json()
for id in json_id['list']:
id_list.append(id['ID'])
post_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
detail_data = {
'id':id
}
detail_json = requests.post(url=post_url,data=detail_data,headers=headers).json()
all_data_list.append(detail_json)
fp = open('./药监总局数据.txt', 'w', encoding='utf-8')
json.dump(all_data_list, fp=fp, ensure_ascii=False)
print('Over!!!')
效果图
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100114.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
