python爬虫-数据解析(正则)
正则解析案例–爬取糗事百科的图片
糗事百科URL
https://www.qiushibaike.com/imgrank/page/2/
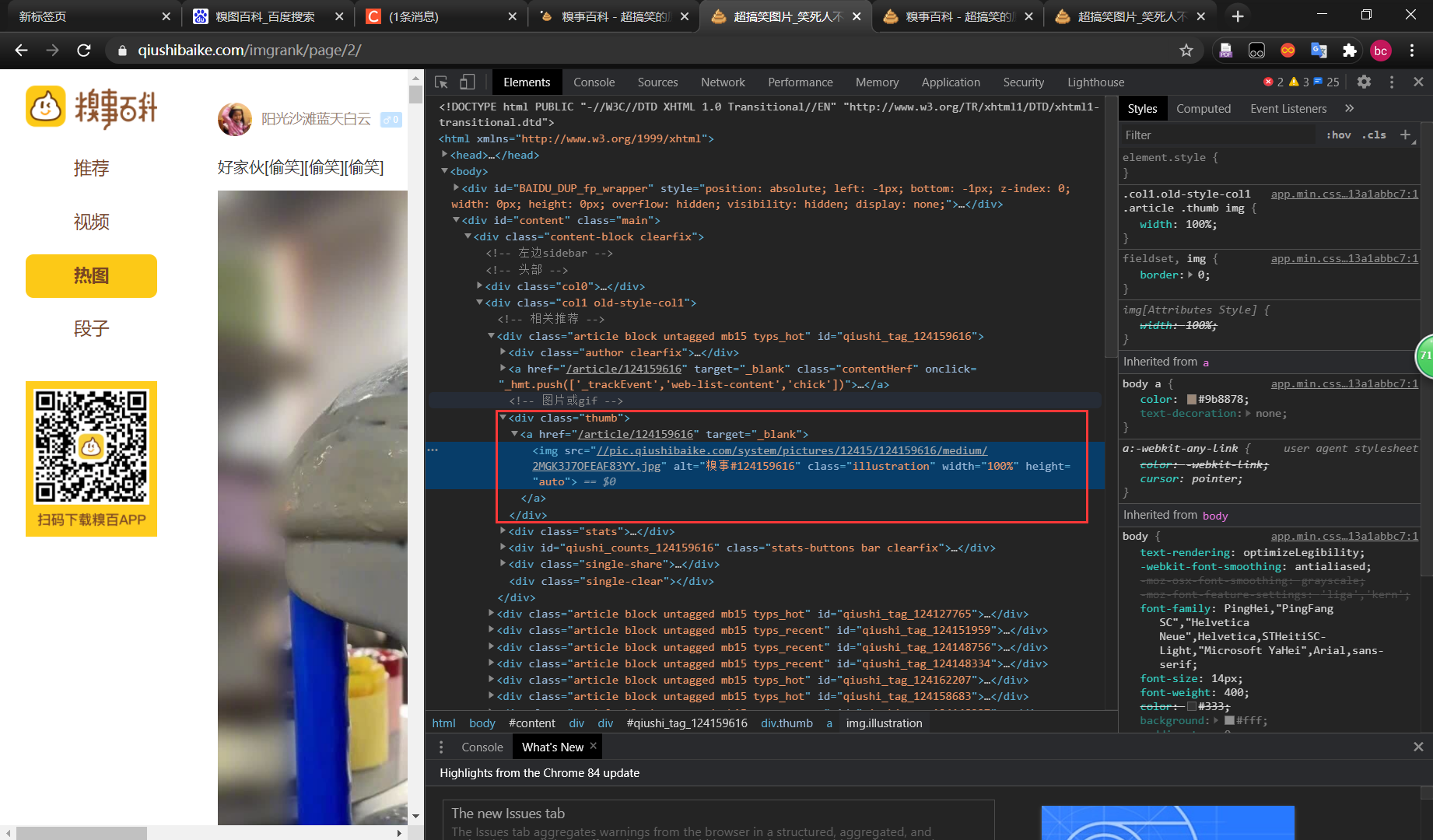

查看网页源代码,发现图片储存的地址
import requests
import re
import os
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
#判断是否存在qiushi文件夹,如果不存在就创建一个
if not os.path.exists('./qiushi'):
os.mkdir('./qiushi')
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
for pageNum in range(1,3):
new_url = format(url%pageNum)
#通用爬虫请求页面数据
gate_text = requests.get(url=new_url,headers=headers).text
ex = '<div class="thumb">.*?<img src="(.*?)" alt=.*?</div>'
#正则匹配,匹配出图片地址
ex_data = re.findall(ex,gate_text,re.S)
for src in ex_data:
#拼接出完整的图片URL
src = 'https:'+src
#请求图片二进制数据
img_data = requests.get(url=src,headers=headers).content
img_name = src.split('/')[-1]
img_path = './qiushi/' + img_name
#创建并写入图片二进制数据
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'success!!')
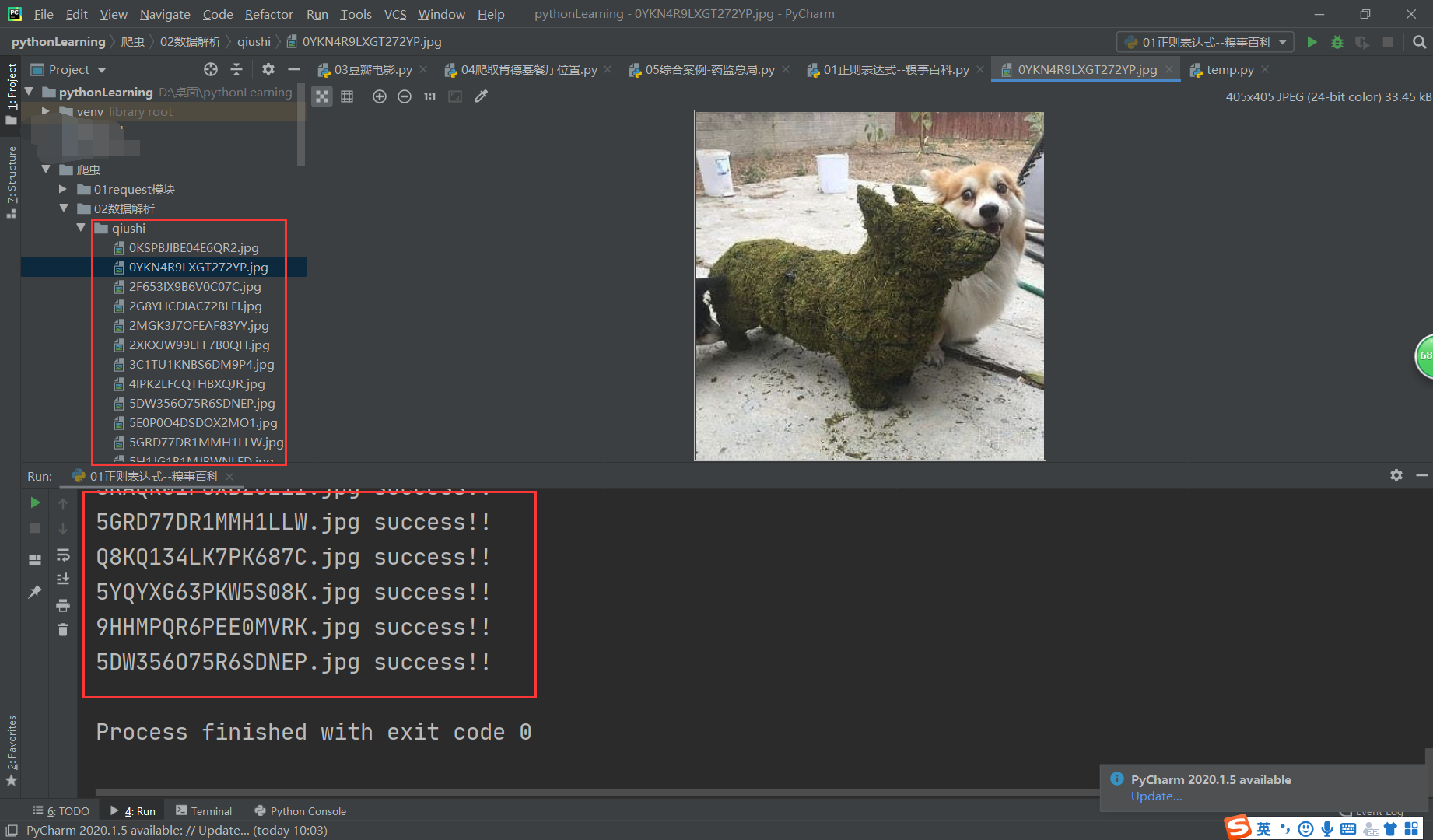
爬取结果
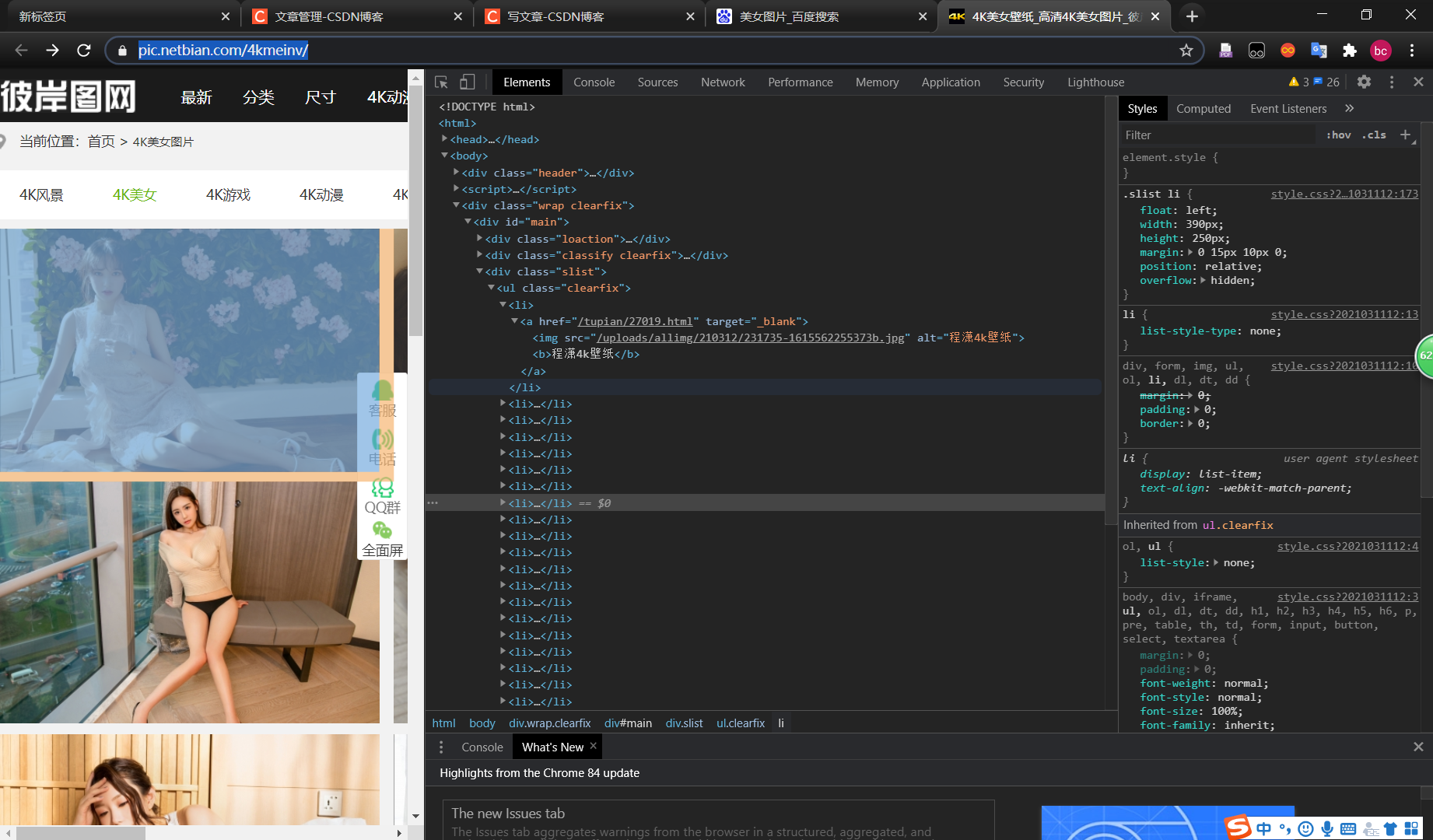
练习
https://pic.netbian.com/4kmeinv/
import re
import requests
import os
if __name__ == '__main__':
if not os.path.exists('./meinv'):
os.mkdir('./meinv')
url = 'https://pic.netbian.com/4kmeinv/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text
ex = '<li><a href=".*?target=".*?<img src="(.*?)" alt=.*?</a></li>'
ex_data = re.findall(ex,page_text,re.S)
for src in ex_data:
src = 'https://pic.netbian.com/'+src
img_data = requests.get(url=src,headers=headers).content
img_name = src.split('/')[-1]
img_path = './meinv/' + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, 'success!!')
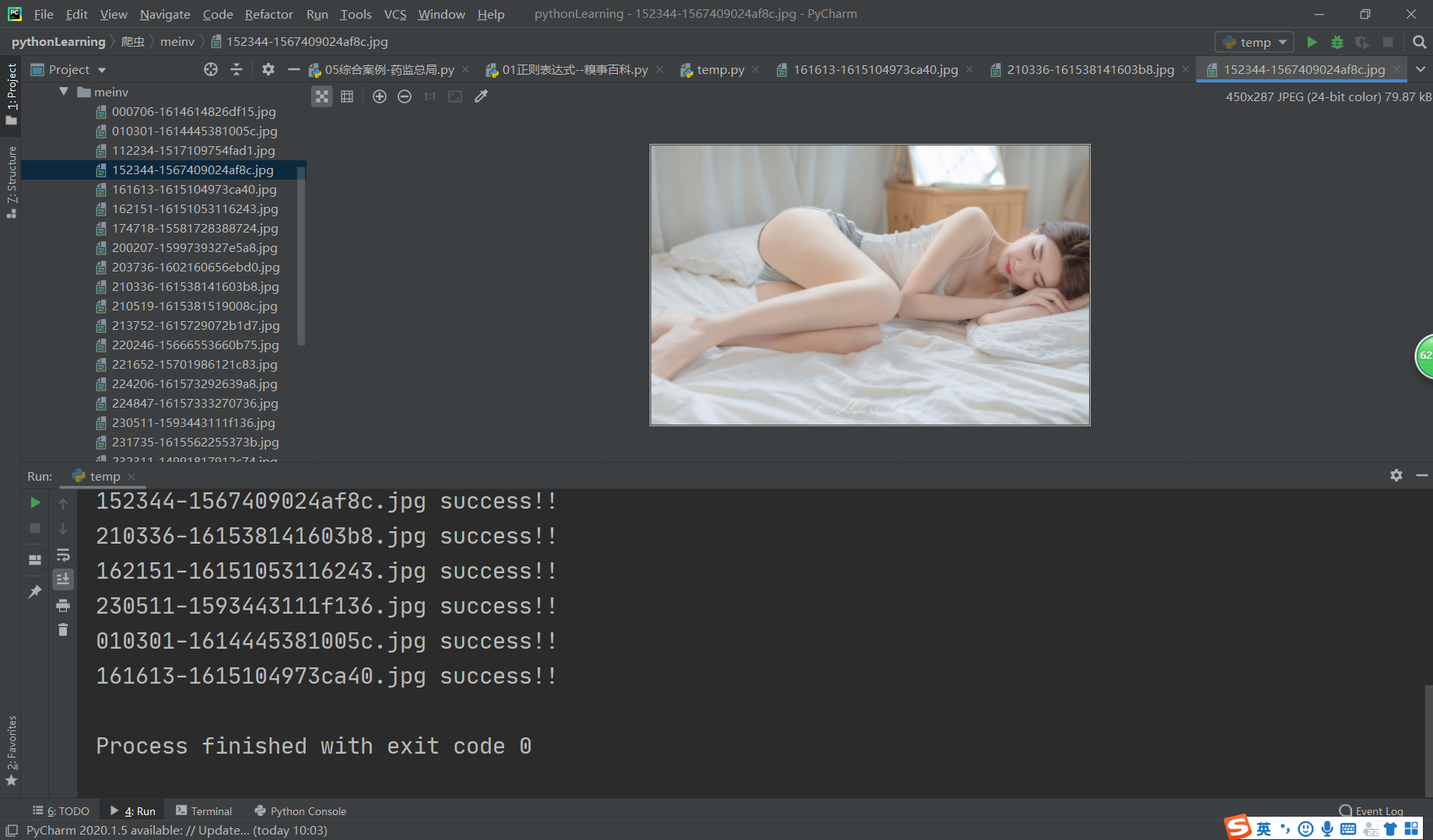
结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100112.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
