python爬虫–验证码、cookie、代理
基本知识
模拟登陆:
爬取基于某些用户的用户信息
点击登陆按钮之后发起post请求
post请求中会携带登陆之前录入的相关登陆信息(用户名,密码,验证码。。。)
Cookie
http/https协议特性:无状态。
没有请求到对应页码数据的原因:
发起第二次基于个人主页的页面请求的时候,服务器端并不知到本次请求是基于登陆状态下的请求。
Cookie:用来让服务器端记录客户端的相关状态
手动处理:
通过抓包工具获取Cookie值,将该值封装到headers中
自动处理:
session会话对象:
- 1.可以进行请求的发送
- 2.如果请求过程中产生了cookie,则cookie会被自动存储/携带在该Session对象中
操作步骤:
- 1.创建一个session对象:session = requests.Session()
- 2.使用sess ion对象进行模拟登录post请求的发送( cookie就会被存储在session中)
- 3.session对象对个人主页对应的get请求进行发送(携带了cookie)
古诗文网验证码识别
https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx
代码
Classcjy
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf-8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
""" im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {
'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
""" im_id:报错题目的图片ID """
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
主程序
import requests
from lxml import etree
from Classcjy import Chaojiying_Client
def getCodeText(imgPath):
chaojiying = Chaojiying_Client('azb123 ', 'azb123', '914332') # 用户中心>>软件ID 生成一个替换 96001
im = open(imgPath, 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
img_code = chaojiying.PostPic(im, 1902)['pic_str']
return img_code
if __name__ == '__main__':
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text
tree = etree.HTML(page_text)
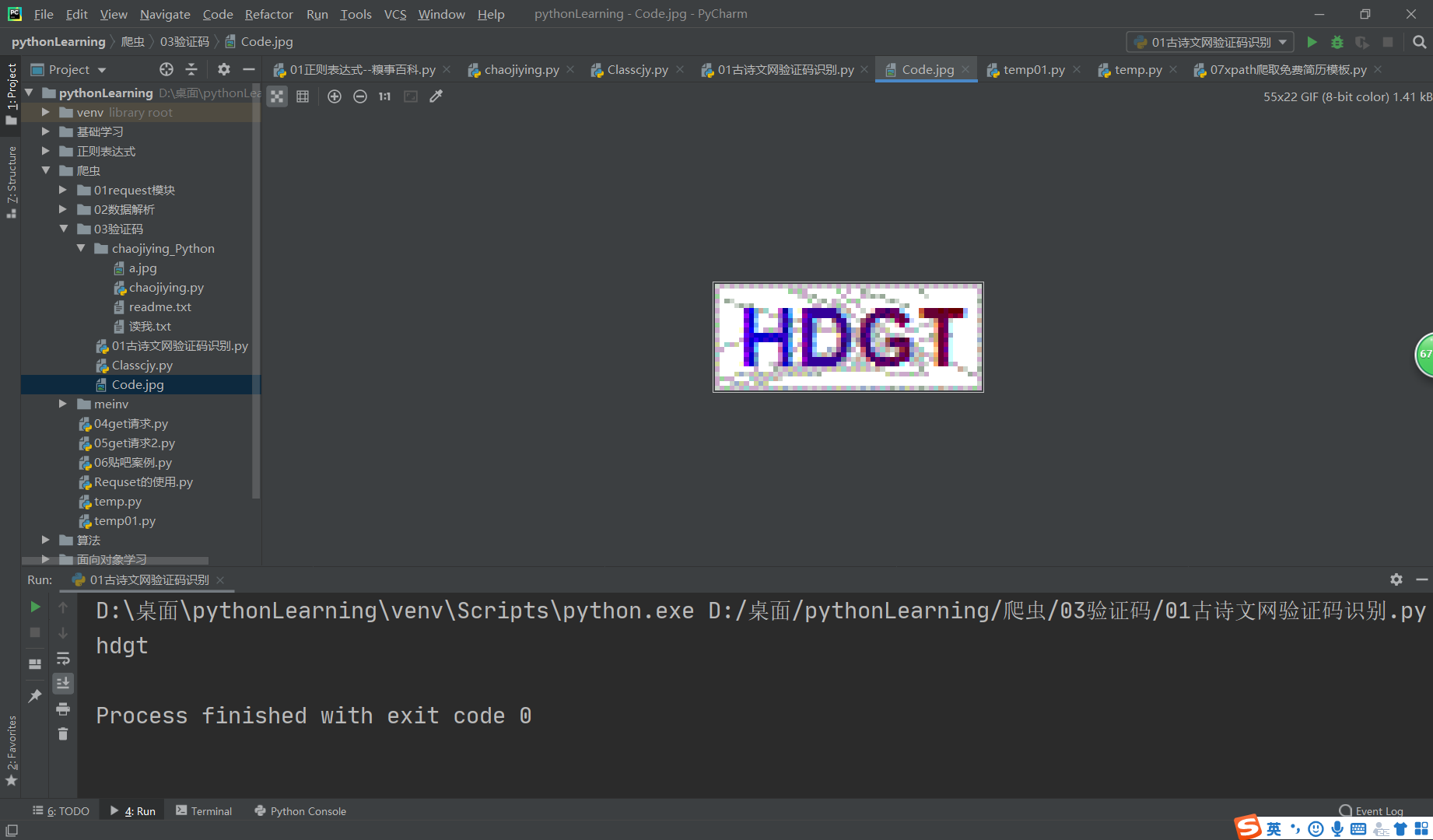
img_url = 'https://so.gushiwen.cn/'+tree.xpath('//*[@id="imgCode"]/@src')[0]
img_data = requests.get(url=img_url,headers=headers).content
with open('./Code.jpg','wb') as fp:
fp.write(img_data)
img_code = getCodeText('./Code.jpg')
print(img_code)

模拟古诗文网登陆
import requests
from lxml import etree
if __name__ == '__main__':
#通过Session对象记录获取cookie
session = requests.Session()
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
#获取登录页面,并建立etree对象
page_text = session.get(url=login_url,headers=headers).text
tree = etree.HTML(page_text)
#使用xpath解析验证码图片地址、动态属性
img_url = 'https://so.gushiwen.cn/'+tree.xpath('//*[@id="imgCode"]/@src')[0]
viewstate = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0]
viewstategenerator = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0]
#将验证码图片存储本地
img_data = session.get(url=img_url,headers=headers).content
with open('./Code.jpg','wb') as fp:
fp.write(img_data)
# 提示用户输入验证码
img_code = input('请输入验证码:')
data = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR':viewstategenerator,
'from':'http://so.gushiwen.cn/user/collect.aspx',
'email': '注册邮箱',
'pwd': '密码',
'code': img_code,
'denglu': '登录',
}
#post请求模拟登陆
index = session.post(url=login_url, headers=headers, data=data)
detial_url = 'https://so.gushiwen.cn/user/collectbei.aspx?sort=t'
detial_text = session.get(url=detial_url,headers=headers).text
with open('index.html', 'w', encoding='utf-8') as fp:
fp.write(detial_text)
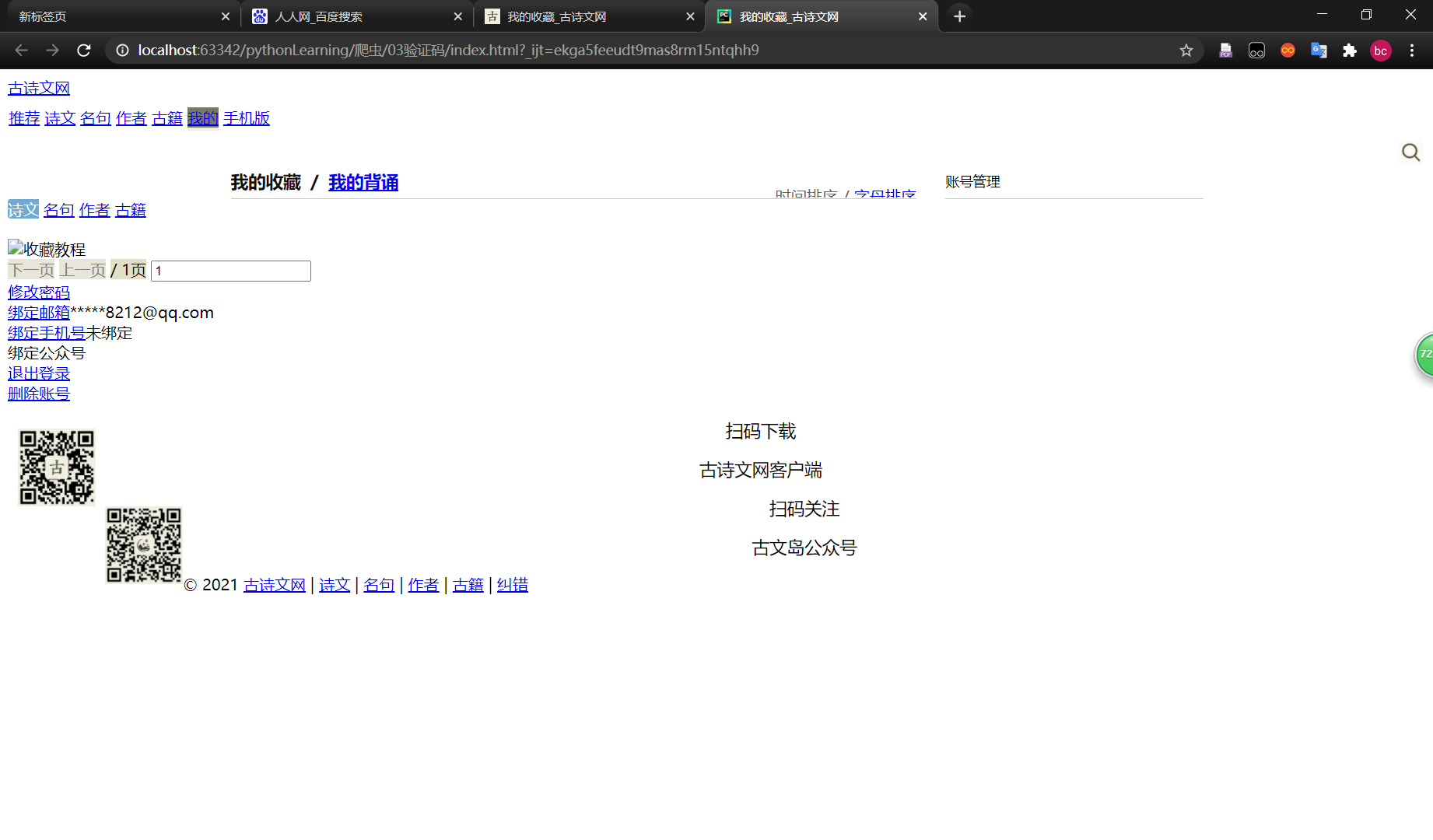
效果图
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100106.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
