1、什么是hashCode:
hashCode就是对象的散列码,是根据对象的某些信息推导出的一个整数值,默认情况下表示是对象的存储地址。通过散列码,可以提高检索的效率,主要用于在散列存储结构中快速确定对象的存储地址,如Hashtable、hashMap中。
为什么说hashcode可以提高检索效率呢?我们先看一个例子,如果想判断一个集合是否包含某个对象,最简单的做法是怎样的呢?逐一取出集合中的每个元素与要查找的对象进行比较,当发现该元素与要查找的对象进行equals()比较的结果为true时,则停止继续查找并返回true,否则,返回false。如果一个集合中有很多个元素,比如有一万个元素,并且没有包含要查找的对象时,则意味着你的程序需要从集合中取出一万个元素进行逐一比较才能得到结论,这样做的效率是非常低的。这时,可以采用哈希算法(散列算法)来提高从集合中查找元素的效率,将数据按特定算法直接分配到不同区域上。将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组(使用不同的hash函数来计算的),每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储在哪个区域,大大减少查询匹配元素的数量。
比如HashSet就是采用哈希算法存取对象的集合,它内部采用对某个数字n进行取余的方式对哈希码进行分组和划分对象的存储区域,当从HashSet集合中查找某个对象时,Java系统首先调用对象的hashCode()方法获得该对象的哈希码,然后根据哈希吗找到相应的存储区域,最后取得该存储区域内的每个元素与该对象进行equals()比较,这样就不用遍历集合中的所有元素就可以得到结论。
下面通过String类的hashCode()计算一组散列码:
public class HashCodeTest {
public static void main(String[] args) {
int hash= 0;
String s= "ok";
StringBuilder sb = new StringBuilder(s);
System.out.println(s.hashCode() + " " + sb.hashCode());
String t = new String("ok");
StringBuilder tb =new StringBuilder(s);
System.out.println(t.hashCode() + " " + tb.hashCode());
}
}
运行结果:
3548 1829164700
3548 2018699554我们可以看出,字符串s与t拥有相同的散列码,这是因为字符串的散列码是由内容导出的。而字符串缓冲sb与tb却有着不同的散列码,这是因为StringBuilder没有重写hashCode()方法,它的散列码是由Object类默认的hashCode()计算出来的对象存储地址,所以散列码自然也就不同了。那么该如何重写出一个较好的hashCode方法呢,其实并不难,我们只要合理地组织对象的散列码,就能够让不同的对象产生比较均匀的散列码。例如下面的例子:
public class Model {
private String name;
private double salary;
private int sex;
@Override
public int hashCode() {
return name.hashCode() + new Double(salary).hashCode() + new Integer(sex).hashCode();
}
}
上面的代码我们通过合理的利用各个属性对象的散列码进行组合,最终便能产生一个相对比较好的或者说更加均匀的散列码,当然上面仅仅是个参考例子而已,我们也可以通过其他方式去实现,只要能使散列码更加均匀(所谓的均匀就是每个对象产生的散列码最好都不冲突)就行了。不过这里有点要注意的就是java 7中对hashCode方法做了两个改进,首先java发布者希望我们使用更加安全的调用方式来返回散列码,也就是使用null安全的方法Objects.hashCode(注意不是Object而是java.util.Objects)方法,这个方法的优点是如果参数为null,就只返回0,否则返回对象参数调用的hashCode的结果。Objects.hashCode 源码如下:
public static int hashCode(Object o) {
return o != null ? o.hashCode() : 0;
}
因此我们修改后的代码如下:
import java.util.Objects;
public class Model {
private String name;
private double salary;
private int sex;
@Override
public int hashCode() {
return Objects.hashCode(name) + new Double(salary).hashCode() + new Integer(sex).hashCode();
}
}
java 7还提供了另外一个方法java.util.Objects.hash(Object… objects),当我们需要组合多个散列值时可以调用该方法。进一步简化上述的代码:
import java.util.Objects;
public class Model {
private String name;
private double salary;
private int sex;
@Override
public int hashCode() {
return Objects.hash(name,salary,sex);
}
}
好了,到此hashCode()该介绍的我们都说了,还有一点要说的,如果我们提供的是一个数组类型的变量的话,那么我们可以调用Arrays.hashCode()来计算它的散列码,这个散列码是由数组元素的散列码组成的。
2、equals()与hashCode()的联系:
Java的超类Object类已经定义了equals()和hashCode()方法,在Obeject类中,equals()比较的是两个对象的内存地址是否相等,而hashCode()返回的是对象的内存地址。所以hashCode主要是用于查找使用的,而equals()是用于比较两个对象是否相等的。但有时候我们根据特定的需求,可能要重写这两个方法,在重写这两个方法的时候,主要注意保持一下几个特性:
(1)如果两个对象的equals()结果为true,那么这两个对象的hashCode一定相同;
(2)两个对象的hashCode()结果相同,并不能代表两个对象的equals()一定为true,只能够说明这两个对象在一个散列存储结构中。
(3)如果对象的equals()被重写,那么对象的hashCode()也要重写。
3、为什么重写equals()的同时要重写hashCode()方法:
在将这个问题的答案之前,我们先了解一下将元素放入集合的流程,如下图:

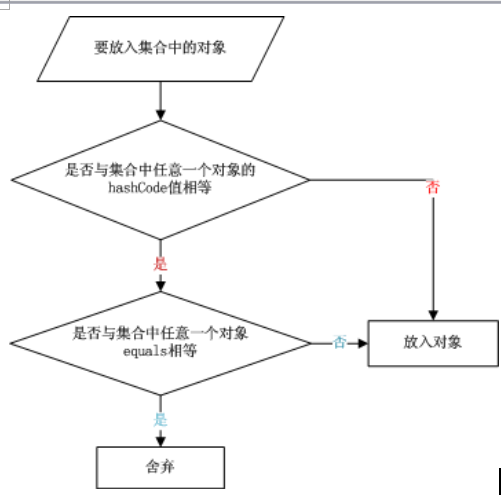
将对象放入到集合中时,首先判断要放入对象的hashcode值与集合中的任意一个元素的hashcode值是否相等,如果不相等直接将该对象放入集合中。如果hashcode值相等,然后再通过equals()判断要放入对象与该存储区域的任意一个对象是否相等,如果equals()判断不相等,直接将该元素放入到集合中,否则不放入。
同样,在使用get()查询元素的时候,集合类也先调key.hashCode()算出数组下标,然后看equals()的结果,如果是true就是找到了,否则就是没找到。
假设我们我们重写了对象的equals(),但是不重写hashCode()方法,由于超类Object中的hashcode()方法始终返回的是一个对象的内存地址,而不同对象的这个内存地址永远是不相等的。这时候,即使我们重写了equals()方法,也不会有特定的效果的,因为不能确保两个equals()结果为true的两个对象会被散列在同一个存储区域,即 obj1.equals(obj2) 的结果为true,但是不能保证 obj1.hashCode() == obj2.hashCode() 表达式的结果也为true;这种情况,就会导致数据出现不唯一,因为如果连hashCode()都不相等的话,就不会调用equals方法进行比较了,所以重写equals()就没有意义了。
以HashSet为例,如果一个类的hashCode()方法没有遵循上述要求,那么当这个类的两个实例对象用equals()方法比较的结果相等时,他们本来应该无法被同时存储进set集合中,但是,如果将他们存储进HashSet集合中时,由于他们的hashCode()方法的返回值不同(HashSet使用的是Object中的hashCode(),它返回值是对象的内存地址),第二个对象首先按照哈希码计算可能被放进与第一个对象不同的区域中,这样,它就不可能与第一个对象进行equals方法比较了,也就可能被存储进HashSet集合中了;所以,Object类中的hashCode()方法不能满足对象被存入到HashSet中的要求,因为它的返回值是通过对象的内存地址推算出来的,同一个对象在程序运行期间的任何时候返回的哈希值都是始终不变的,所以,只要是两个不同的实例对象,即使他们的equals方法比较结果相等,他们默认的hashCode方法的返回值是不同的。
接下来,我们就举几个小例子测试一下:
3.1、测试一:覆盖equals()但不覆盖hashCode(),导致数据不唯一性。
public class HashCodeTest {
public static void main(String[] args) {
Collection set = new HashSet();
Point p1 = new Point(1, 1);
Point p2 = new Point(1, 1);
System.out.println(p1.equals(p2));
set.add(p1); //(1)
set.add(p2); //(2)
set.add(p1); //(3)
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object object = iterator.next();
System.out.println(object);
}
}
}
class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Point other = (Point) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
@Override
public String toString() {
return "x:" + x + ",y:" + y;
}
}
输出结果:
true
x:1,y:1
x:1,y:1 原因分析:
- 当执行set.add(p1)时(1),集合为空,直接存入集合;
- 当执行set.add(p2)时(2),首先判断该对象p2的hashCode值所在的存储区域是否有相同的hashCode,因为没有覆盖hashCode方法,所以默认使用Object的hashCode方法,返回内存地址转换后的整数,因为不同对象的地址值不同,所以这里不存在与p2相同hashCode值的对象,所以直接存入集合。
- 当执行set.add(p1)时(3),时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,继续判断equals是否返回true,因为是同一对象所以返回true。此时jdk认为该对象已经存在于集合中,所以舍弃。
3.2、测试二:覆盖hashCode(),但不覆盖equals(),仍然会导致数据的不唯一性。
修改Point类:
class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public String toString() {
return "x:" + x + ",y:" + y;
}
} 输出结果:
false
x:1,y:1
x:1,y:1 原因分析:
- 当执行set.add(p1)时(1),集合为空,直接存入集合;
- 当执行set.add(p2)时(2),首先判断该对象p2的hashCode值所在的存储区域是否有相同的hashCode,这里覆盖了hashCode方法,p1和p2的hashCode相等,所以继续判断equals()是否相等,因为这里没有覆盖equals(),默认使用 “==” 来判断,而 “==” 比较的是两个对象的内存地址,所以这里equals()会返回false,所以集合认为是不同的对象,所以将p2存入集合。
- 当执行set.add(p1)时(3),时,因为p1已经存入集合,同一对象返回的hashCode值是一样的,并且equals返回true。此时认为该对象已经存在于集合中,所以舍弃。
综合上述两个测试,要想保证元素的唯一性,必须同时覆盖hashCode和equals才行。
(注意:在HashSet中插入同一个元素(hashCode和equals均相等)时,新加入的元素会被舍弃,而在HashMap中插入同一个Key(Value 不同)时,原来的元素会被覆盖。)
4、由hashCode()造成的内存泄露问题:
public class RectObject {
public int x;
public int y;
public RectObject(int x,int y){
this.x = x;
this.y = y;
}
@Override
public int hashCode(){
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj){
if(this == obj)
return true;
if(obj == null)
return false;
if(getClass() != obj.getClass())
return false;
final RectObject other = (RectObject)obj;
if(x != other.x){
return false;
}
if(y != other.y){
return false;
}
return true;
}
}
我们重写了父类Object中的hashCode和equals方法,看到hashCode和equals方法中,如果两个RectObject对象的x,y值相等的话他们的hashCode值是相等的,同时equals返回的是true;
import java.util.HashSet;
public class Demo {
public static void main(String[] args){
HashSet<RectObject> set = new HashSet<RectObject>();
RectObject r1 = new RectObject(3,3);
RectObject r2 = new RectObject(5,5);
RectObject r3 = new RectObject(3,3);
set.add(r1);
set.add(r2);
set.add(r3);
r3.y = 7;
System.out.println("删除前的大小size:"+set.size());//2
set.remove(r3);
System.out.println("删除后的大小size:"+set.size());//2
}
}
运行结果:
删除前的大小size:3
删除后的大小size:3在这里,我们发现了一个问题,当我们调用了remove删除r3对象,以为删除了r3,但事实上并没有删除,这就叫做内存泄露,就是不用的对象但是他还在内存中。所以我们多次这样操作之后,内存就爆了。看一下remove的源码:
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
然后再看一下map的remove方法的源码:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
再看一下removeEntryForKey方法源码:
/**
* Removes and returns the entry associated with the specified key
* in the HashMap. Returns null if the HashMap contains no mapping
* for this key.
*/
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
我们看到,在调用remove方法的时候,会先使用对象的hashCode值去找到这个对象,然后进行删除,这种问题就是因为我们在修改了 r3 对象的 y 属性的值,又因为RectObject对象的hashCode()方法中有y值参与运算,所以r3对象的hashCode就发生改变了,所以remove方法中并没有找到 r3,所以删除失败。即 r3的hashCode变了,但是他存储的位置没有更新,仍然在原来的位置上,所以当我们用他的新的hashCode去找肯定是找不到了.
上面的这个内存泄露告诉我一个信息:如果我们将对象的属性值参与了hashCode的运算中,在进行删除的时候,就不能对其属性值进行修改,否则会导致内存泄露问题。
5、基本数据类型和String类型的hashCode()方法和equals()方法:
(1)hashCode():八种基本类型的hashCode()很简单就是直接返回他们的数值大小,String对象是通过一个复杂的计算方式,但是这种计算方式能够保证,如果这个字符串的值相等的话,他们的hashCode就是相等的。
(2)equals():8种基本类型的equals方法就是直接比较数值,String类型的equals方法是比较字符串的值的。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/100013.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
